리소스 활용 효율성
머신 러닝, 특히 딥 러닝은 훈련 중에 많은 양의 GPU 리소스를 소비하는 것으로 악명이 높습니다. 그러나, 마지막 부분에서 이미 강조했듯이, 기계 학습은 단순히 모델을 훈련시키는 것 이상입니다. 또한 머신 러닝 워크플로우 내의 이러한 구성 요소에는 대량의 CPU, 메모리, 스토리지 및 네트워크 리소스가 필요합니다.
VMware Cloud Platform에 대한 머신 러닝 – Part 1에서는 개념, 교육 및 구축의 세 가지 단계를 다룹니다. 개념 단계와 교육 단계 모두에서 모델을 탐색하고 교육하려면 기존의 “알려진 데이터”가 필요합니다. 모델을 개발하는 동안 교육 세트, 검증 세트 및 테스트 세트의 세 가지 다른 데이터 세트를 사용하는 것이 일반적입니다. 데이터 세트를 생성하는 것은 가능한 한 많은 데이터를 가져오는 것만이 아닙니다. 모델에 의해 생성된 권장 사항의 정확성은 교육 및 검증에 사용되는 데이터 세트의 품질에 크게 좌우되기 때문에 의미 있는 데이터와 높은 수준의 품질을 얻는 것이 훨씬 더 중요합니다. 데이터 과학 팀은 이러한 고품질 데이터 세트를 얻기 위해 기존의 원시 데이터를 “엉켜서(wrangle)” 형성해야 합니다. 데이터 논쟁은 원시 데이터를 모델을 교육하기 위한 데이터 세트 “다운스트림”으로 사용할 수 있는 더 가치 있는 데이터로 변환합니다. 그리고 이러한 모든 논쟁에는 GPU 외에도 많은 부수적인 인프라와 서비스가 필요합니다.
대규모 데이터셋은 어떤 기업 IT 조직에서도 새로운 것이 아닙니다. “기록 시스템”은 항상 비즈니스 프로세스의 중추입니다. 70년대의 메인프레임과 80년대와 90년대의 SAP 및 Oracle과 같은 사내 ERP 시스템의 부상에 대해 생각해 보십시오. 오늘날 데이터베이스, 데이터 웨어하우스 및 데이터 레이크에는 페타바이트 단위의 데이터가 포함되어 있습니다. 교육 목적으로 사용되는 100기가바이트 데이터 세트는 인상적이지 않게 들릴 수 있습니다. 하지만 다른 점이 있습니다. 이 데이터 세트는 끊임없이 이동합니다. 비트와 바이트는 천천히 데이터베이스에 축적되지 않고 SQL 문에 의해 선택될 때까지 대기합니다. 아니요. 이러한 데이터 세트는 인프라를 통해 풀링되고 푸시됩니다. 여러 소스에서 추출되어 여러 플랫폼에 의해 변환되고 여러 번 저장 및 버전화됩니다. 예를 들어, 많은 ML 프로젝트는 구조화, 변환 및 분석이 필요한 시스템에서 방대한 양의 비정형 데이터(비디오, 오디오, 로그 파일)를 기본 형식으로 캡처하고 저장합니다. 이러한 프로세스는 가상화된 플랫폼에서 x86 사이클을 태우고 네트워크에 데이터를 노출하는 많은 데이터 이동을 생성합니다.
아래 다이어그램은 다양한 협업 Juypter 노트북 솔루션, 아티팩트 스토어 또는 완전한 데이터 과학 또는 Databricks, Domino, H20.ai, DataRobot, Dataiku와 같은 MLops 플랫폼과 같은 많은 필수 데이터 과학 팀 도구를 생략하고 이러한 환경의 구조적 구성 요소를 강조하는 것입니다.

교육 후 프로세스를 살펴보면 배치 단계에 속합니다. 이 단계에서는 데이터 과학 팀 또는 MLops 팀이 통합 모델을 고객 또는 최종 시스템과 연계하는 시스템 또는 플랫폼(예: 로봇 암 또는 공장 설치)에 통합합니다. 통합 모델은 추가 교육이 모델을 개선하지 않을 때까지 학습된 모델입니다. 완성된 모델이라고 하면 어떨까요? 세상이 변함에 따라, 모델은 세계의 현재 상태를 반영하도록 훈련되지 않을 수 있습니다. 코로나 및 호텔, 여객기 및 엔터테인먼트 산업에 배치된 ML 모델에 대해 생각해 보십시오. 그들은 세계의 현재 상황을 반영하기 위해 약간의 조정이 필요했습니다. 이 때문에 일부 모델은 재교육이 필요합니다. 이 재교육은 실시간으로 이루어지지 않습니다. 사용 사례와 데이터 흐름에 따라 다릅니다. 자동 검색 레지스터, 슈퍼마켓의 휴가철 포장 변경 또는 창고에 있는 추가 품목에 대해 생각해 보십시오. 일반적으로 대부분의 팀은 수동 재교육으로 시작합니다. 그러나 자동화 분야로 전환하여 CI/CD 파이프라인을 살펴보고, 주기적인 구축 프로세스를 생성하고, 새로운 모델을 재교육하고, 보이지 않는 데이터를 새로운 교육 세트로 캡처하기를 원합니다.
상상할 수 있듯이 이러한 플랫폼과 (파이프라인) 구성요소를 실행하려면 많은 처리 능력이 필요합니다. 게다가, 많은 조직에서 AI\ML 프로젝트는 긴급한 비즈니스 과제를 해결하기 위해 개별 사업부에 의해 시작됩니다. 각 팀은 솔루션 기술 스택을 실행하고 개발 라이프사이클을 따라 리소스 활용률로 모델을 개발합니다. 오늘날 우리가 보는 것은 ML 프로젝트의 무질서한 확산의 시작입니다. 많은 ML 프로젝트는 작은 데이터셋으로 시작하여 노트북과 일부 작은 데이터셋에서 시작하여 서서히 성장하여 비즈니스에 필수적인 요소가 됩니다. 그리고 우리는 이 현상에 동일한 조직과 프로세스 모델을 부착합니다. 누군가는 이를 감지하고, 더 많은 통합을 요청하고, Machine Learning Center of Excellence를 시작하고, 자원 활용을 중앙 집중화하는 것을 생각하기 시작할 것입니다.
그리고 이것이 올바른 사고방식입니다. 각 팀이 독자적인 플랫폼을 구축하지 않았으면 합니다. 이러한 현상은 90년대에 조직이 메인프레임에서 분산형 X86 서버로 전환하면서 볼 수 있었습니다. 이 기계들 중 많은 것들이 충분히 활용되지 않았습니다. 이제 많은 데이터 과학자가 가상화의 효과를 인식하지 못하고 있다는 것을 알 수 있습니다. 클라우드 또는 베어메탈입니다. 클라우드 플랫폼은 시작하기에 좋지만 너무 편견이 심하여(too opinionated) 베어메탈로 전환됩니다. 그들은 빵을 자른 이후 가장 훌륭한 것을 빼놓습니다.
개념 및 교육 단계의 두 가지 예를 사용해 보겠습니다. 데이터 과학자 팀은 “하이퍼 파라미터 검색”을 수행할 때 여러 개의 더 작은 GPU 장착 머신과 더 작은 데이터 세트를 사용하여 올바른 ML 모델 아키텍처 및 모델을 찾습니다. 또는 스파크 클러스터를 사용하여 집중적인 데이터 처리 작업을 수행하는 경우 일반적으로 사전 처리 작업에만 집중합니다. 여기서 핵심은 ML 플랫폼이 주로 많은 부분으로 구성되지만 한 부분만 많이 활용된다는 것입니다. 리소스 활용 측면에서 많은 플랫폼 부품이 원래 분산 아키텍처로 설계되었기 때문에 모델 개발당 로드 관련 활용률 급증을 해결해야 합니다.
위의 모든 것이 매우 복잡하게 들릴 수 있지만, 많은 경우 그렇지 않습니다. 조직이 작업을 단일 플랫폼으로 중앙 집중화하면 워크로드의 소음이 많은 이웃 측면을 처리해야 합니다. 하지만 소음이 많은 이웃을 상대해 본 적이 있으며 vSphere의 핵심 부분 중 많은 부분이 새로운 분산 워크로드를 처리하기 위해 업데이트된다는 것이 가장 좋은 점입니다. 예를 들어 DRS 2.0. 컨테이너형 워크로드를 처리하기 위해 5분마다가 아니라 60초마다 실행되며 vSphere 클러스터 전체에서 높은 수준의 호스트 활용률 균형 조정 대신 워크로드 행복에 초점을 맞춥니다. NVIDIA AI Enterprise를 도입한 NVIDIA와의 파트너십을 통해 GPU를 공간적으로 분할하여 컴퓨팅 리소스를 격리하고 완전한 멀티 테넌시(Multi-tenancy)를 구현할 수 있습니다.
다양한 vGPU 기술이 ML 사용 사례에 가장 적합한 방법에 대한 최신 Lan Vu 블로그 게시물을 참조하십시오.)
또한 파트너와 함께 새로운 기술을 개발하여 ML 모델 개발에서 vSphere 플랫폼에 도입할 대량의 IO 스트림을 고려하고 있습니다. Project Montrey는 클러스터 아키텍처에 데이터 처리 장치(DPU)를 도입합니다.
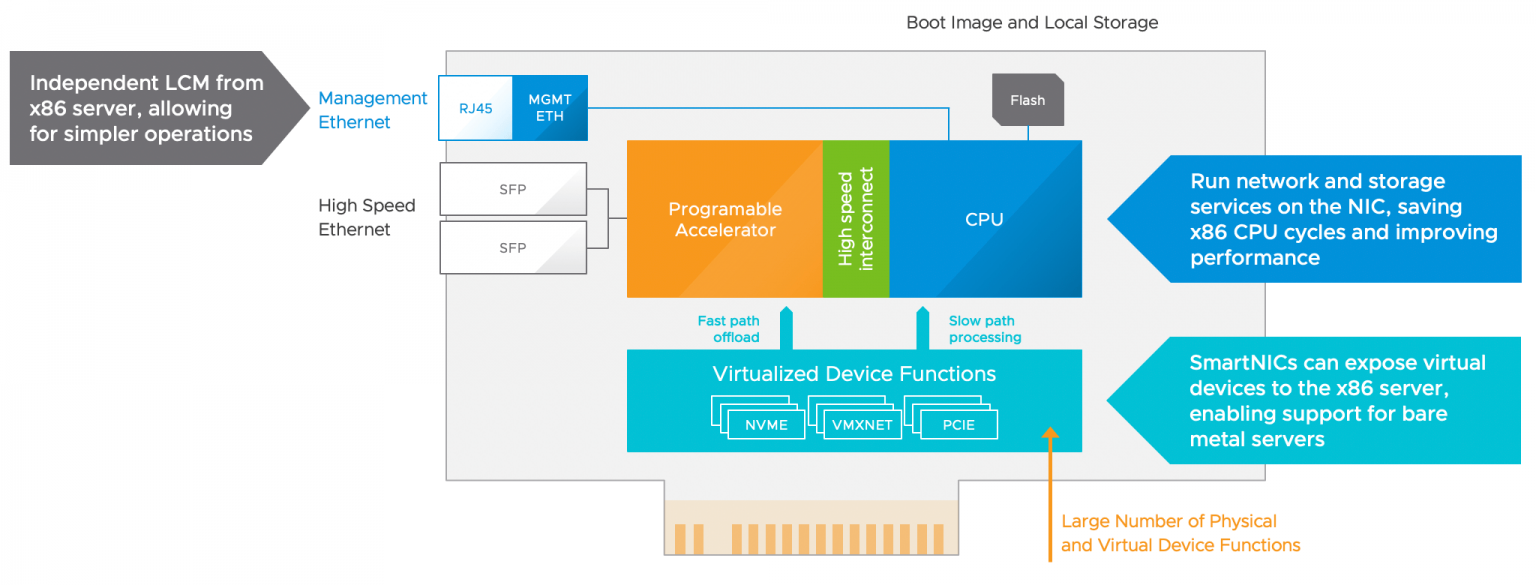
다양한 활용 사례가 있지만, DPU를 통해 생성할 수 있는 혁신적인 네트워크 IO 오프로드와 NVIDIA의 Bluefield 아키텍처를 통해 보다 지능적인 기능을 제공할 수 있다는 점이 저를 흥분시킵니다. 오늘날 가상화 플랫폼 내의 모든 네트워크 IO는 ESXi 호스트의 x86(하나의 x86 사이클 이상)을 소비합니다. 따라서 플랫폼을 통해 다양한 모델의 데이터셋과 데이터셋을 풀링하고 푸시하면 가상화 플랫폼을 사용하는 데이터 과학자와 다른 직원 및 서비스에 대해 툴체인에 사용되는 나머지 가상 머신과 컨테이너를 실행하는 데 남은 x86 사이클에 영향을 미칩니다. DPU를 도입하면 이러한 네트워크 IO 스트림을 컴퓨팅 계층에서 격리할 수 있습니다.
ML 플랫폼의 잠재력이 큰 또 다른 프로젝트로는 프로젝트 Capitola, 즉 vSphere 팀이 소프트웨어 정의 메모리 구조라고 부르는 프로젝트가 있습니다. 데이터 사전 처리 단계에서는 많은 양의 스토리지 공간을 확보하는 것이 가장 좋지만 빠른 스토리지 공간을 원합니다. 하지만 비용을 절감하고 연간 IT 예산을 모두 RAM 모듈에 지출하고 싶지는 않을 수도 있습니다. Project Capitola를 사용하면 애플리케이션을 다시 작성하지 않고도 다양한 메모리 기술을 사용하여 워크로드에 다른 계층의 메모리 용량을 제공할 수 있습니다.
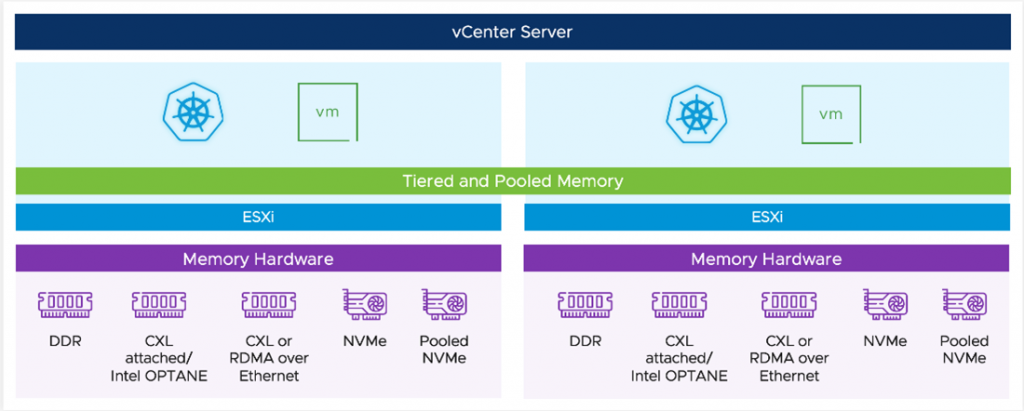
중요한 과제는 올바른 리소스를 제공하고 리소스를 효율적이고 경제적으로 연결 및 분리하여 데이터 과학 팀과 조직이 이점을 누릴 수 있는 플랫폼을 확보하는 것입니다. 플랫폼은 가능한 한 신속하게(셀프 서비스) 워크로드 환경을 제공하고 탄력적이어야 합니다. 다음 파트에서는 위험 완화에 대해 알아보겠습니다.
Montrey, Capitola 또는 셀프 서비스 부분에 대해 자세히 알아보려면 Cormac Hogan, Duncan Epping 및 (Virtual) Roadshow “The ever-evolving VMware Infrastructure”에 참여하십시오. 가능 여부에 대해 VMUG 리더에게 문의하십시오.
출처 : https://frankdenneman.nl/2022/06/08/machine-learning-on-vmware-cloud-platform-part-2/




