Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://developers.redhat.com/articles/2025/10/16/network-performance-distributed-training-maximizing-gpu-utilization-openshift
두 개의 IBM Cloud GPU 클러스터(하나는 NVIDIA L40S GPU를 탑재하고 다른 하나는 H100 GPU를 탑재)를 직접 비교하여 분산 학습 성능을 실제로 좌우하는 요인이 무엇인지 확인했습니다.
핵심적인 결과는 분산 학습의 경우, 네트워크 아키텍처 선택이 성능에 가장 중요한 요소이며, 기본 컨테이너 네트워킹의 성능을 훨씬 능가한다는 것입니다. 테스트 결과, 노드 간 통신에 표준 Red Hat OpenShift Pod 네트워크를 사용하면 심각한 성능 병목 현상이 발생하여 값비싼 GPU 리소스를 최대한 활용하지 못하는 것으로 나타났습니다.
L40S 클러스터의 경우, 보조 가상 네트워크 인터페이스 카드(vNIC)를 활용함으로써 기본 파드 네트워크 대비 상당한 성능 향상을 달성했으며, 이러한 격차는 8노드 테스트에서 최대 성능 향상률 132%로 확장되었습니다. 더 강력한 H100 클러스터의 경우, 그 효과는 더욱 극명했습니다. vNIC에서 고처리량 단일 루트 입출력 가상화(SR-IOV) 네트워크로 전환하자 학습 처리량이 3배 증가했습니다. SR-IOV를 통한 원격 직접 메모리 액세스(RDMA)를 활성화하면 테스트 대상 모델 크기에 비해 성능 향상이 미미했지만, CPU 네트워크 관리가 병목 현상이 발생하는 대규모 모델에서는 필수적인 기술입니다.
우리의 주요 권장 사항은 다음과 같습니다.
- OpenShift에서 확장 가능한 분산 학습을 위해서는 고성능 네트워킹이 필수적입니다.
- H100과 같은 최고급 GPU가 장착된 클러스터의 경우, 네트워크가 주요 병목 현상이 되는 것을 방지하기 위해 더 높은 대역폭을 갖춘 SR-IOV NIC가 필요합니다.
- L40S와 같은 중간급 GPU가 장착된 클러스터의 경우, 보조 vNIC는 효율적인 확장을 달성하기 위한 비용 효율적인 솔루션을 제공합니다.
적절한 네트워크 인프라에 투자하는 것은 GPU 하드웨어에 대한 투자 수익을 극대화하고 대규모로 비용 효율적인 고성능 AI 운영을 보장하는 데 매우 중요합니다.
기술적 배경
본 보고서의 분산 학습 프로세스는 대규모 언어 모델을 학습하는 데 사용되는 일반적인 방법론을 기반으로 합니다. 본 테스트에서는 학습 스크립트와 효율적인 데이터 처리를 위해 오픈 소스 InstructLab 프로젝트를 사용했지만, 네트워크 성능에 대한 결과는 모든 분산 학습 프레임워크에 광범위하게 적용 가능합니다.
핵심 학습 방법론은 PyTorch의 Fully Sharded Data Parallel( FSDP ) 기능을 기반으로 합니다. FSDP는 모델의 매개변수, 그래디언트, 옵티마이저 상태를 클러스터 내 모든 사용 가능한 GPU에 분산하여 매우 큰 규모의 모델을 학습할 수 있도록 하는 데이터 병렬 처리 기술입니다. 각 GPU가 전체 모델의 일부만 보유하도록 함으로써, 단일 GPU 메모리에 담기에는 너무 큰 모델도 학습할 수 있습니다.
그러나 이러한 샤딩 전략은 학습 과정을 기반 네트워크의 속도와 효율성에 크게 의존하게 만듭니다. GPU는 정방향 및 역방향 패스 중에 필요한 매개변수를 교환하기 위해 지속적으로 통신해야 하므로, 네트워크 아키텍처 선택은 전체 FSDP 성능에 중요한 요소가 됩니다.
사용한 하드웨어
우리의 테스트에서는 두 개의 IBM Cloud GPU 클러스터를 활용하여 서로 다른 하드웨어 구성이 네트워크 최적화에 어떻게 반응하는지 파악했습니다.
2xL40S 클러스터 워커
IBM Cloud의 gx3-48x240x2l40s 가상 인스턴스는 48개의 vCPU, 240GiB RAM, 그리고 각각 48GB 메모리를 갖춘 2개의 NVIDIA L40S GPU를 갖추고 있습니다. vNIC 당 100Gbps의 대역폭을 제공하는 고속 네트워크 연결을 제공하여 AI, 머신 러닝, 대규모 시뮬레이션과 같은 고성능 컴퓨팅 작업에 이상적입니다. 이 구성은 까다로운 워크로드를 위한 CPU, GPU 및 메모리 리소스의 강력한 조합을 제공합니다.
테스트에서는 시스템 노드 수를 1개에서 8개까지 확장하여 연산 리소스 증가에 따른 성능 변화를 평가했습니다. 이러한 접근 방식을 통해 시스템의 확장성을 분석하고 노드 확장이 전체 성능에 미치는 영향을 파악할 수 있었습니다.
8xH100 클러스터 노드
IBM Cloud의 gx3d -160x1792x8h100 가상 인스턴스는 160개의 vCPU, 1,792GiB RAM, 그리고 각각 80GB 메모리를 갖춘 8개의 NVIDIA H100 GPU를 탑재하고 있습니다. vNIC당 200Gbps의 대역폭과 최대 8개의 SR-IOV NIC(각각 400Gbps)를 지원하는 고속 네트워크 연결을 제공하여 고급 AI, 딥 러닝, 고성능 컴퓨팅과 같은 매우 까다로운 워크로드에 적합합니다. 이 구성은 대규모 시뮬레이션 및 데이터 집약적인 작업을 위한 뛰어난 GPU 구성과 함께 뛰어난 연산 능력을 제공합니다.
테스트에서는 노드를 1개에서 2개로 확장했으며, 각 노드에는 NVIDIA H100 GPU 8개가 장착되었습니다. 이 구성은 노드당 상당한 연산 능력을 제공하여 노드 수를 두 배로 늘렸을 때 성능이 어떻게 변하는지 평가할 수 있었습니다. 각 노드는 고성능 H100 GPU 덕분에 복잡하고 GPU 집약적인 워크로드를 처리할 수 있었습니다.
테스트 세부 정보
성능 테스트는 CI 자동화 환경에서 재현성과 투명성을 염두에 두고 수행되었습니다. 아래 하위 섹션에서는 테스트 환경, 테스트 하네스, 그리고 훈련 작업의 주요 측면을 자세히 설명합니다.
테스트 환경
모든 테스트는 다음 플랫폼 버전을 사용하는 OpenShift 클러스터에서 실행되었습니다.
- OpenShift 버전: 4.18.16
- OpenShift AI 버전: 2.19.0
테스트 자동화 하네스
전체 테스트 워크플로는 OpenShift에서 복잡한 테스트 시나리오를 조율하는 오픈소스 도구인 TOPSAIL을 fine_tuning 사용하여 자동화되었습니다. TOPSAIL 내 프로젝트는 환경 준비, 데이터 세트 전처리, 필요한 모든 쿠버네티스 리소스의 동적 생성 및 배포를 포함한 테스트 실행의 모든 측면을 관리하는 데 사용되었습니다. 여기에는 PyTorchJob 매니페스트, config.json 하이퍼파라미터 파일, 그리고 아래에 자세히 설명된 run_ilab.sh 진입점 스크립트가 포함됩니다. 이러한 자동화는 모든 구성에서 일관되고 반복 가능한 테스트 방법론을 보장합니다.
학습 직무 사양
분산 학습 작업은 PyTorchJob 사용자 지정 리소스를 사용하여 조정되었습니다. 다음은 8노드 ilab 작업 예시의 주요 구성 매개변수를 요약한 것입니다.
apiVersion: kubeflow.org/v1
kind: PyTorchJob
metadata:
name: ilab
namespace: fine-tuning-testing
spec:
pytorchReplicaSpecs:
Master:
replicas: 1
restartPolicy: Never
template:
spec:
containers:
- name: pytorch
image: registry.redhat.io/rhelai1/instructlab-nvidia-rhel9:1.5.1-1749157760
command:
- bash
- /mnt/entrypoint/run_ilab.sh
resources:
limits:
nvidia.com/gpu: "2"
requests:
cpu: "1"
memory: 10Gi
nvidia.com/gpu: "2"
# ... and other configurations
Worker:
replicas: 7
restartPolicy: Never
template:
spec:
containers:
- name: pytorch
image: registry.redhat.io/rhelai1/instructlab-nvidia-rhel9:1.5.1-1749157760
command:
- bash
- /mnt/entrypoint/run_ilab.sh
resources:
limits:
nvidia.com/gpu: "2"
requests:
cpu: "1"
memory: 10Gi
nvidia.com/gpu: "2"
volumeMounts:
- mountPath: /dev/shm
name: shm-volume
# ... and other volume mounts
volumes:
- name: storage-volume
persistentVolumeClaim:
claimName: fine-tuning-storage
- name: shm-volume
emptyDir:
medium: Memory
sizeLimit: 20Gi
# ... and other volumes이 구성은 컨트롤러 1개와 워커 복제본 7개를 포함하는 분산 학습 클러스터를 구축했습니다. 각 복제본 포드에는 NVIDIA GPU 2개, CPU 코어 1개, 그리고 10Gi의 시스템 메모리가 프로비저닝되었습니다. 핵심적인 아키텍처 선택은 분산 학습에 필수적인 고성능 프로세스 간 통신을 용이하게 하기 위해 20Gi 인메모리 볼륨(/dev/shm)을 사용하는 것이었습니다.
훈련 과정의 핵심은 torchrun를 통해 실행되었습니다. 일관된 기준선을 보장하기 위해 모든 테스트에서 다음 매개변수가 일정하게 유지되었습니다.
--model_name_or_path=granite-3.1-8b-starter-v2--num_epochs=1--data_path=data.jsonl
각 특정 테스트 시나리오에 맞게 조정된 주요 변수에는 노드 수( --nnodes), 노드당 프로세스 수( --nproc_per_node), 최대 배치 길이( --max_batch_len)가 포함되었습니다.
이 모델은 샘플당 평균 시퀀스 길이가 1,483개 토큰인 9,872개의 토큰화된 명령-응답 샘플을 포함하는 데이터 세트에서 학습되었습니다.
네트워크 구성
본 연구에서는 분산 학습 처리량의 핵심 요소인 노드 간 통신에 미치는 영향을 파악하기 위해 여러 네트워크 아키텍처의 성능을 평가했습니다. 아래 하위 섹션에서는 네 가지 네트워크 구성을 설명합니다.
포드 네트워크
설명: 각 포드가 IP 주소를 받고 가상화된 오버레이 네트워크를 통해 통신하는 기본 OpenShift 소프트웨어 정의 네트워크(OVN)입니다.
성능 특성: Pod 네트워크의 대역폭은 고정되어 있지 않습니다. 기본 물리적 네트워크에 의해 제한되며, 소프트웨어 정의 네트워크(SDN) 캡슐화 프로토콜의 오버헤드로 인해 대역폭이 감소합니다. 이로 인해 지연 시간이 발생하고 CPU 사이클이 소모되므로, 처리량이 높고 지연 시간이 짧은 분산 워크로드에는 적합하지 않습니다.
vNIC
설명: 가상 머신(VM)이 전용 하드웨어가 있는 것처럼 네트워크와 상호 작용할 수 있도록 하는 가상화된 네트워크 인터페이스로, virtio 프로토콜을 사용하여 물리적 네트워크 인터페이스 카드(NIC)를 추상화합니다.
성능 특성: vNIC의 대역폭은 인스턴스 프로필에 따라 제한됩니다. 테스트 결과, L40S 노드의 경우 100Gbps , H100 노드의 경우 200Gbps 였습니다 . Pod 네트워크보다 빠르지만, 하이퍼바이저의 가상화 오버헤드는 여전히 발생합니다.
SR-IOV
설명: SR‑IOV는 단일 물리적 NIC가 여러 가상 기능(VF)을 게스트 VM에 직접 노출시켜 하이퍼바이저 전환 오버헤드를 제거하는 PCIe(Peripheral Component Interconnect Express) 사양입니다.
성능 특성: SR-IOV는 거의 회선 속도에 가까운 성능을 제공합니다. H100 클러스터의 경우, 이는 물리적 400Gbps NIC의 전체 대역폭에 액세스하는 것을 의미했으며, 결과적으로 처리량이 크게 증가했습니다.
RDMA를 사용한 SR-IOV
설명: SR-IOV와 RDMA를 결합하여 네트워크 인터페이스가 CPU를 사용하지 않고 다른 노드의 메모리에 직접 액세스할 수 있도록 합니다. 이 무복사 데이터 전송 메커니즘은 최대 처리량과 최소 지연 시간을 위해 설계되었습니다.
성능 특성: 대역폭은 기본 SR-IOV 인터페이스와 동일(예: 400Gbps )하지만 RDMA는 CPU에서 데이터 전송 작업을 오프로드하여 대기 시간과 CPU 사용률을 더욱 줄입니다. 이는 매우 큰 데이터 전송이 있는 워크로드에 매우 중요합니다.
L40S 클러스터에서 사용 가능한 네트워크 구성
- 포드 네트워크
- 다른 서브넷의 vNIC
H100 클러스터에서 사용 가능한 네트워크 구성
- 포드 네트워크
- vNIC
- SR-IOV NIC
- RDMA를 갖춘 SR-IOV NIC
IBM Cloud NIC 생성 절차
이 섹션에서는 표준 vNIC와 고성능 SR-IOV NIC를 모두 포함하여 IBM Cloud에서 다양한 네트워크 인터페이스 카드를 만들고 연결하는 단계를 설명합니다.
서브넷 생성
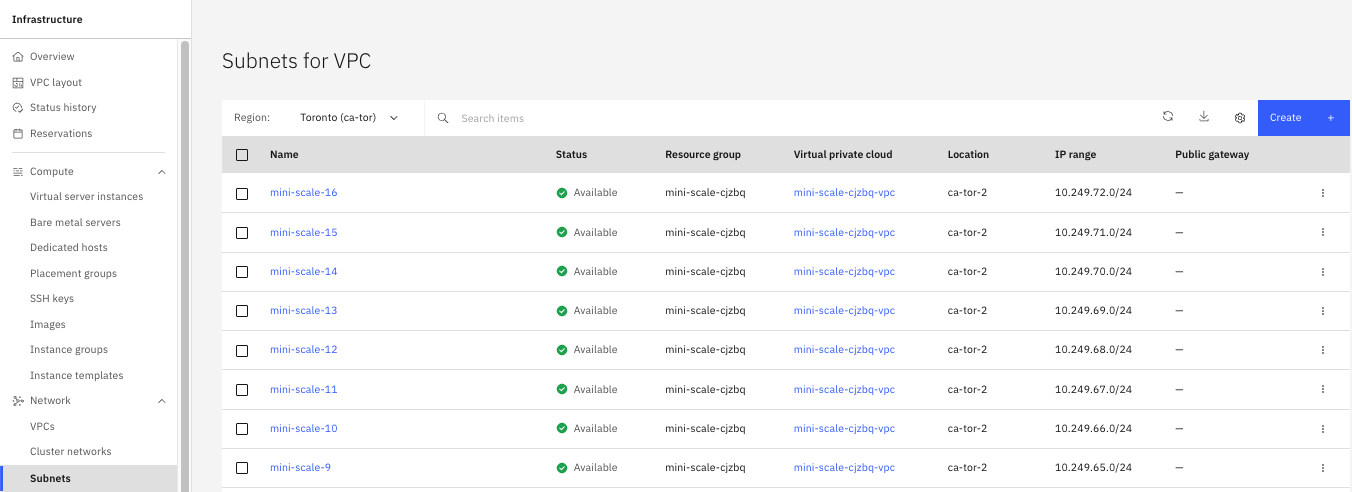
vNIC를 생성하려면 먼저 서브넷과 연결해야 합니다. IBM Cloud 콘솔의 Virtual Private Cloud (VPC) Infrastructure 섹션에서 Subnets으로 이동하여 Create을 선택하면 이 프로세스가 시작됩니다 (그림 1). 그런 다음 서브넷의 고유 이름을 입력하고, 상위 VPC를 선택한 후, 특정 위치(영역)를 선택해야 합니다.
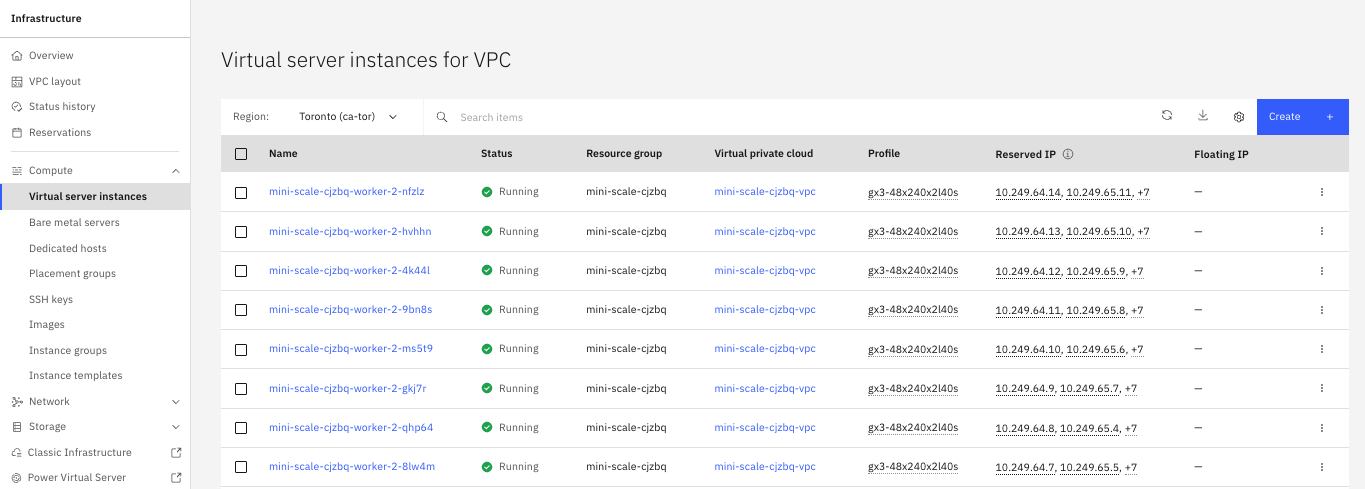
기존 Virtual Server Instance (VSI)의 네트워크 연결을 강화하기 위해 추가 vNIC를 생성하고 연결할 수 있습니다. 이 과정은 IBM Cloud 콘솔에서 특정 VSI로 이동하는 것으로 시작됩니다(그림 2).
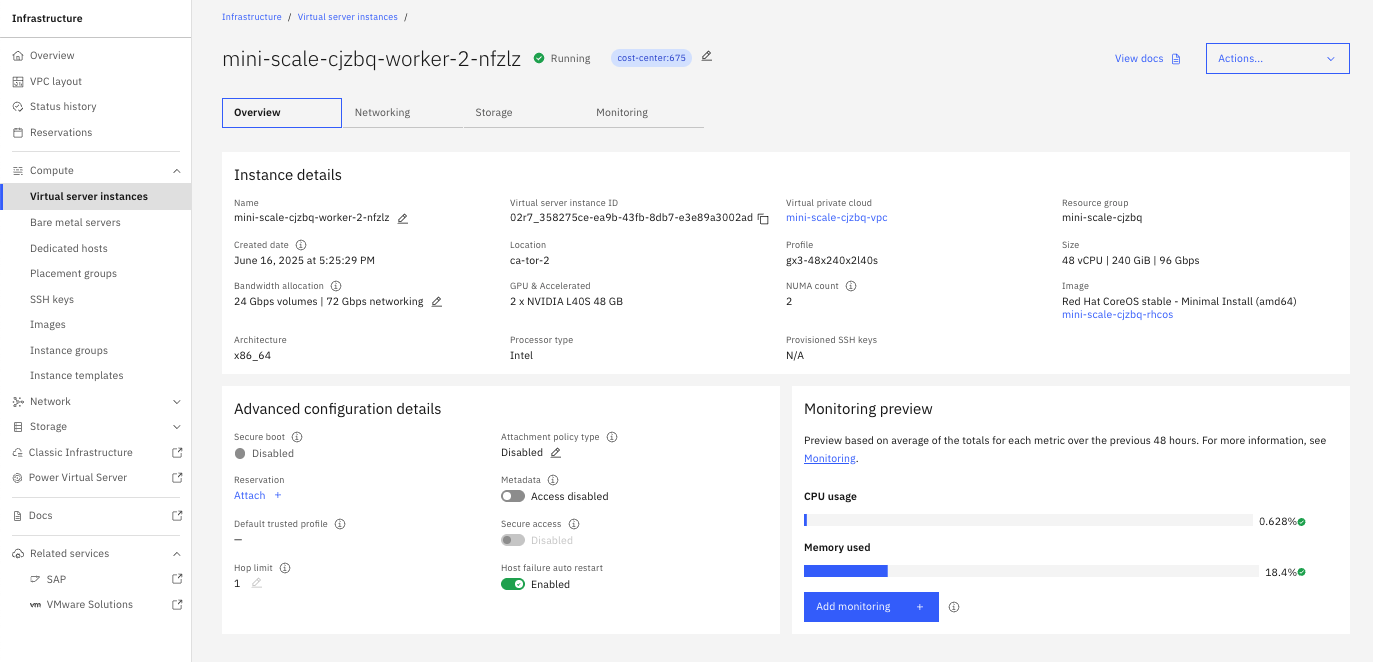
인스턴스 세부 정보 페이지(그림 3)에서 Networking 페이지 의 Network interfaces 탭을 선택하면 현재 연결된 모든 NIC가 나열됩니다. 여기에서 새 인터페이스를 생성할 수 있습니다.
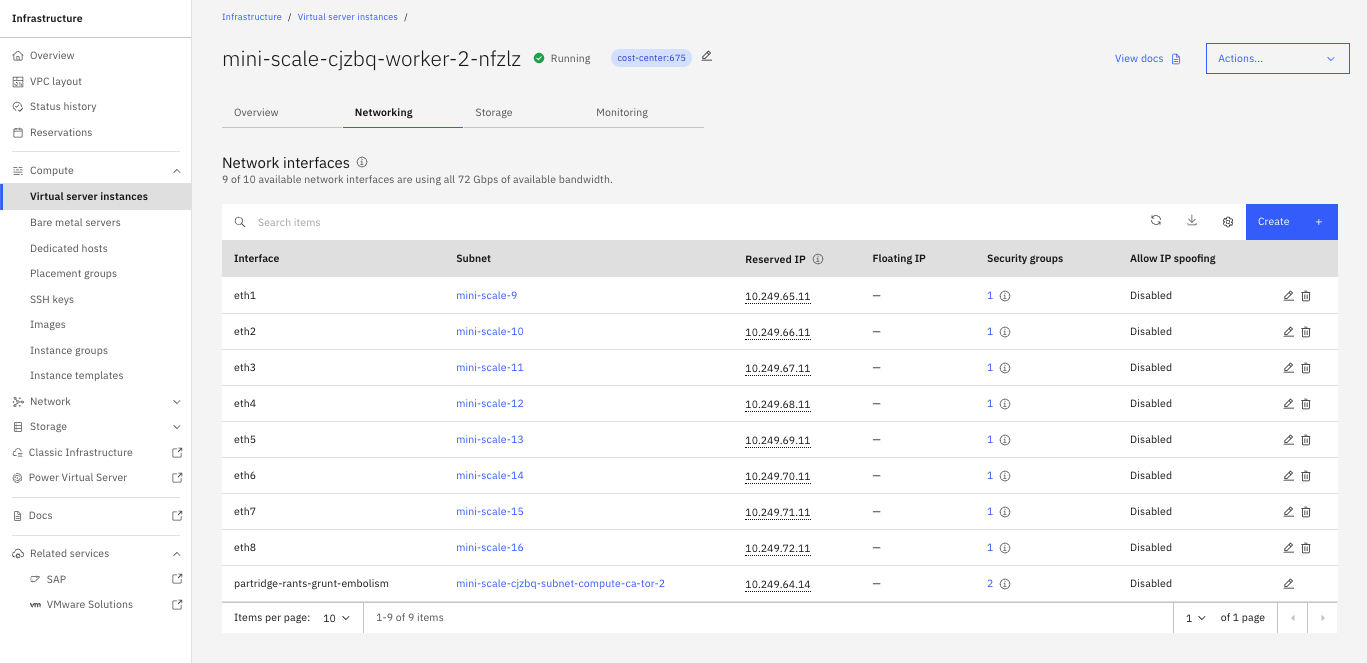
구성을 위해서는 새 vNIC의 이름을 지정하고 기존 VPC에서 대상 서브넷을 선택해야 합니다. 선택한 서브넷이 VSI와 동일한 영역에 있어야 합니다. 구성이 확인되면 vNIC가 프로비저닝되고 인스턴스에 연결되며, 인터페이스 목록에 표시되고 게스트 운영 체제에서 구성을 위해 사용할 수 있게 됩니다. 그림 4를 참조하십시오.
IBM Cloud에 SR-IOV NIC를 추가하는 절차
고성능과 낮은 지연 시간이 요구되는 워크로드의 경우, SR-IOV를 활성화하여 직접 하드웨어 액세스를 제공할 수 있습니다. 이 기능은 VSI 프로필을 처음 생성할 때 활성화해야 합니다. VSI에 SR-IOV 지원 프로필이 프로비저닝되면 SR-IOV 네트워크 인터페이스를 연결하는 프로세스는 표준 vNIC와 유사합니다.
VSI의 클러스터 네트워크 연결 탭 으로 이동합니다 (그림 5).
인터페이스 생성 메뉴에는 SR-IOV에 대한 추가 옵션 또는 탭이 있습니다. 여기에서 물리적 NIC에서 가상 머신으로 직접 가상 파일(VF)을 할당하는 SR-IOV 인터페이스를 생성할 수 있습니다. 이를 통해 하이퍼바이저의 가상 스위치를 우회하여 네트워크 지연 시간과 CPU 오버헤드를 크게 줄이고, 인터페이스를 게스트 운영 체제에 물리적 장치로 노출하여 고처리량 통신에 대비할 수 있습니다.
엔트리포인트 스크립트
run_ilab.sh 스크립트 는 네트워킹 환경을 동적으로 구성하고 학습 프로세스를 시작했습니다. 다음 섹션에서는 스크립트의 핵심 로직을 중점적으로 설명합니다.
RDMA 구성
이 블록은 WITH_RDMA 변수가 설정된 경우에만 활성화됩니다. RDMA 기능을 갖춘 사용 가능한 SR-IOV NIC를 감지하고 PyTorch 분산 백엔드가 노드 간 통신에 고성능 RDMA 경로를 사용하도록 필요한 NCCL 환경 변수를 설정합니다.
if [[ "${WITH_RDMA:-}" ]]; then
export NCCL_TOPO_FILE=/mnt/storage/topo.xml
num_rdma=$(ls /sys/class/infiniband/ | wc -l)
IFS=',' read -ra ADDR <<< "$NCCL_SOCKET_IFNAME"
length=${#ADDR[@]}
NCCL_IB_HCA=''
for idx in $(seq $((num_rdma-1)) -1 $((num_rdma-length))); do
if [ -z "$NCCL_IB_HCA" ]; then
NCCL_IB_HCA="mlx5_$idx"
else
NCCL_IB_HCA="$NCCL_IB_HCA,mlx5_$idx"
fi
done
export NCCL_IB_HCA="$NCCL_IB_HCA"
export NCCL_IB_DISABLE=0
export NCCL_IB_GID_INDEX=3
export NCCL_DEBUG=info
fivNIC IP 주소 리매핑
이 섹션은 보조 vNIC 또는 SR-IOV NIC(NCCL_SOCKET_IFNAME 변수로 지정됨)가 사용될 때 실행됩니다. 미리 정의된 매핑 파일을 읽어 각 Pod의 보조 네트워크 인터페이스를 동적으로 재구성하고, 올바른 IP 주소를 할당하고, 여러 서브넷 간 통신을 지원하는 데 필요한 경로를 추가합니다.
if [[ "${NCCL_SOCKET_IFNAME:-}" ]]; then
MAPPING="$(cat /mnt/nic-mapping/nodename_ip_mapping.yaml)"
for ifname in $(echo $NCCL_SOCKET_IFNAME | tr , " "); do
current_ip=$(ip route | grep "$ifname " | cut -d" " -f9)
correct_ip=$(echo "$MAPPING" | grep "$NODE_HOSTNAME" | grep "$ifname:" | cut -d: -f4)
ip addr del "$current_ip/24" dev "$ifname"
ip addr add "$correct_ip/24" dev "$ifname"
while read remote_mapping; do
remote_ip=$(echo "$remote_mapping" | cut -d: -f4)
ip route add $remote_ip/32 via "$correct_ip" metric 150
done <<< $(echo "$MAPPING" | grep -v "$NODE_HOSTNAME" | grep "$ifname:")
done
fiIP 주소 매핑 파일(nodename_ip_mapping.yaml)
IP 리매핑 로직은 각 포드에 마운트된 미리 생성된 YAML 파일을 사용합니다. 이 파일은 네트워크 토폴로지의 단일 정보 소스 역할을 하며, 각 노드의 호스트 이름을 할당된 보조 네트워크 인터페이스와 해당 인터페이스의 올바른 IP 주소에 매핑합니다. 파일의 내용은 클러스터의 ConfigMap에 저장됩니다.
apiVersion: v1
data:
nodename_ip_mapping.yaml: |
mini-scale-cjzbq-worker-2-4k44l:ens13:net1:10.249.65.9
mini-scale-cjzbq-worker-2-4k44l:ens14:net2:10.249.66.9
mini-scale-cjzbq-worker-2-4k44l:ens15:net3:10.249.67.9
mini-scale-cjzbq-worker-2-4k44l:ens16:net4:10.249.68.9
mini-scale-cjzbq-worker-2-4k44l:ens17:net5:10.249.69.9
...
kind: ConfigMap
metadata:
name: ilab-nic-mapping
namespace: fine-tuning-testingtorchrun 실행 명령
이는 최종 실행 단계입니다. 스크립트는 torchrun 를 사용하여 분산 학습 작업을 시작합니다. --nnodes, --nproc_per_node , --max_batch_len와 같은 학습 실행에 필요한 모든 하이퍼파라미터가 포함된 파일을 config.json 구문 분석하여 명령줄 인수를 동적으로 빌드합니다 .
config_json=$(jq . "$CONFIG_JSON_PATH")
if ! torchrun \
--node_rank "${RANK}" \
--rdzv_endpoint "${MASTER_ADDR}:${MASTER_PORT}" \
$(echo "$config_json" | jq -r '. | to_entries | .[] | ("--" + .key + " " + (.value | tostring))' | sed "s/ true//");
then
ret=1
echo "TORCHRUN FAILED :/ (retcode=$ret)"
fi하이퍼파라미터 구성(config.json)
torchrun 명령은 Pod에 마운트된 config.json 파일을 통해 구성됩니다. 이를 통해 유연하고 반복 가능한 테스트 실행이 가능합니다. 아래는 테스트 실행 중 하나에 사용된 구성의 예입니다.
{
"nnodes": 8,
"nproc_per_node": 2,
"module": "instructlab.training.main_ds",
"model_name_or_path": "/mnt/storage/model/granite-3.1-8b-starter-v2",
"data_path": "/mnt/storage/dataset/data.jsonl",
"output_dir": "/mnt/output/model",
"num_epochs": 1,
"effective_batch_size": 3840,
"learning_rate": 0.0001,
"num_warmup_steps": 800,
"save_samples": 0,
"log_level": "INFO",
"max_batch_len": 35000,
"seed": 42,
"distributed_training_framework": "fsdp",
"cpu_offload_optimizer": true,
"cpu_offload_params": true,
"fsdp_sharding_strategy": "HYBRID_SHARD"
}네트워크 연결 정의
OpenShift는 훈련 포드에서 보조 네트워크를 사용할 수 있도록 NetworkAttachmentDefinition(NAD) 사용자 지정 리소스를 사용합니다. 이러한 NAD는 Container Network Interface (CNI) 플러그인이 포드에 추가 네트워크 인터페이스를 연결하는 방식을 정의합니다. vNIC 및 SR-IOV 테스트를 위해 서로 다른 NAD가 생성되었습니다.
vNIC(호스트 장치) 연결 정의
표준 vNIC 테스트에는 host-device NAD가 사용되었습니다. 이 구성은 Multus CNI가 호스트 노드의 기존 네트워크 장치(예: ens13)를 Pod의 네트워크 네임스페이스로 직접 이동하여 물리적 네트워크에 직접 액세스하도록 지시합니다. whereabouts IP 주소 관리(IPAM) 플러그인을 사용하여 미리 정의된 범위에서 이 인터페이스에 고정 IP 주소를 할당했습니다.
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: network-port-01
spec:
config: '{
"cniVersion": "0.3.1",
"name": "network-port-01",
"device": "ens13",
"type": "host-device",
"ipam": {
"type": "whereabouts",
"range": "10.241.129.0/24"
}
}'RDMA 첨부 정의를 포함한 SR-IOV
고성능 테스트에는 host-device CNI 플러그인도 사용되었지만, RDMA 기능을 활성화하는 특정 사용자 지정 플래그가 포함되었습니다. 이 NAD는 호스트 노드의 특정 SR-IOV 네트워크 장치(예: enp223s0)를 가져와 Pod로 전달합니다. 주요 차이점은 플래그로 isRdma: true, 이 인터페이스에 대해 RDMA(커널 바이패스) 모드를 활성화하도록 기본 네트워크 패브릭에 신호를 보내 노드 간 통신 지연 시간을 최소화합니다.
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: subnet-rdma-port-07
spec:
config: '{
"cniVersion": "0.3.1",
"name": "subnet-rdma-port-07",
"device": "enp223s0",
"type": "host-device",
"ipam": {
"type": "whereabouts",
"range": "10.241.129.0/24"
}
"isRdma": true
}'성과 결과 및 분석
우리의 테스트는 네트워크 구성이 분산형 학습 환경에서 높은 GPU 활용도와 확장성을 달성하는 데 가장 중요한 요소라는 것을 분명히 보여줍니다.
L40S 클러스터 결과
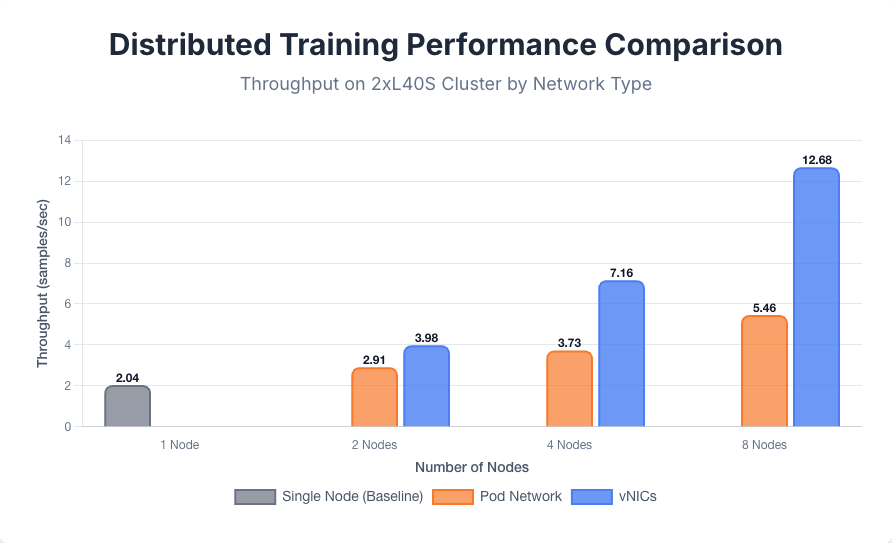
기준 성능은 단일 노드에서 초당 2.04개의 샘플 처리량을 달성하여 확립되었습니다. 여러 노드로 확장했을 때, 노드 간 통신에 사용된 네트워크 구성에 따라 성능 차이가 뚜렷하게 나타났습니다. 기본 Pod 네트워크를 사용하여 노드를 2, 4, 8개로 확장했을 때 각각 초당 2.91, 3.73, 5.46개의 샘플 처리량을 얻었습니다. 반면, 전용 vNIC를 사용했을 때는 동일한 노드 수에서 초당 3.98, 7.16, 12.68개의 샘플 처리량을 달성하여 성능이 크게 향상되었습니다. 각 다중 노드 vNIC 테스트에서 사용된 보조 네트워크 인터페이스 수는 훈련 작업에 참여하는 노드 수와 동일했습니다.
노드 수가 증가함에 따라 성능 격차가 벌어지며, 이는 파드 네트워크의 고대역폭 통신 한계를 여실히 드러냅니다. 모든 파드 간 트래픽을 캡슐화하는 가상 오버레이 네트워크의 오버헤드는 지연 시간을 발생시키고 CPU 사이클을 소모하여 GPU를 완전히 활용하지 못하게 하는 병목 현상을 야기합니다. 전용 vNIC는 물리적 네트워크로의 직접적이고 지연 시간이 짧은 경로를 제공하는데, 이는 분산 학습에 필요한 빈번한 그래디언트 동기화에 필수적이며, 이를 통해 더욱 효율적인 확장을 가능하게 합니다.
성능 비교는 그림 6에 나와 있습니다.
H100 클러스터 결과
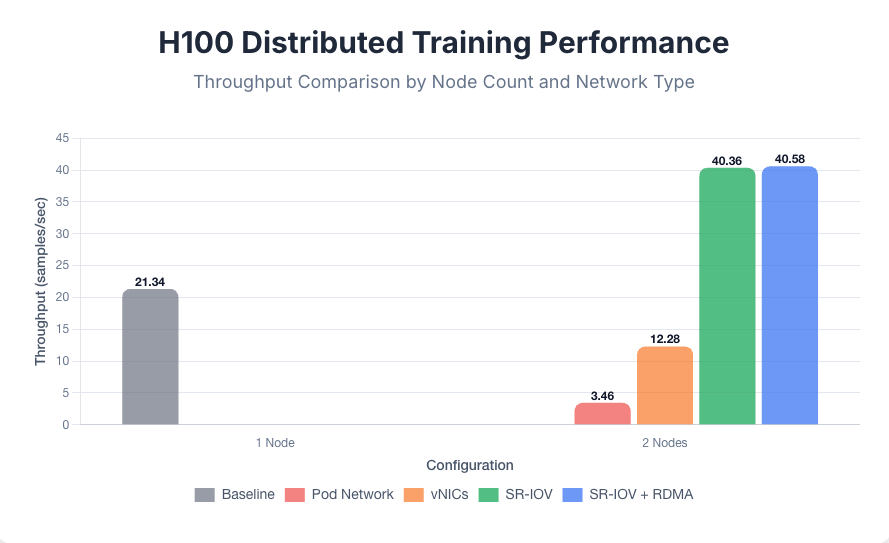
단일 8xH100 노드를 사용하여 훈련은 초당 21.34개의 샘플 이라는 기준 처리량을 달성했습니다 . 두 개의 노드로 확장했을 때, 결과는 네트워크 병목 현상의 영향을 극적으로 보여주었습니다. 기본 Pod 네트워크(초당 3.46개의 샘플)와 표준 vNIC(초당 12.28개의 샘플) 모두 확장에 실패하여 단일 노드 기준보다 처리량이 현저히 낮았습니다.
이러한 부정적인 스케일링은 이러한 네트워크의 높은 지연 시간과 낮은 대역폭으로 인해 통신 병목 현상이 매우 심각해져 노드 간 그래디언트 동기화 대기 시간이 추가 GPU의 연산 성능 향상을 초과했기 때문에 발생합니다. FSDP 훈련 프로토콜은 연산과 통신을 중첩하여 통신 오버헤드를 숨기려고 합니다. L40S와 같은 느린 GPU의 경우 vNIC 사용으로 인한 통신 오버헤드를 숨길 수 있었지만, H100과 같은 빠른 GPU의 경우 vNIC의 통신 오버헤드를 숨길 수 없었습니다. 따라서 성능 향상을 위해 SR-IOV 인터페이스가 필요했습니다.
고성능 네트워킹을 사용함으로써만 엄청난 성능 향상을 달성할 수 있었습니다. SR-IOV 인터페이스로 전환하여 초당 40.36개의 샘플 처리량을 달성하여 단일 노드 성능을 거의 두 배로 향상시켰으며, 최고 수준의 GPU 사용 시 네트워크 병목 현상을 방지하기 위해서는 직접 하드웨어 액세스가 필수적임을 확인했습니다.
RDMA를 활성화하면 초당 40.58개의 샘플 로 최종적으로 미미한 개선이 이루어졌습니다 . 이는 이 모델 크기에서 주요 병목 현상이 RDMA가 해결하는 데이터 전송 시 CPU 개입이 아니라 하이퍼바이저 오버헤드임을 시사합니다. SR-IOV는 이 문제를 해결합니다. 2노드 테스트의 경우, 각 구성에서 단일 보조 네트워크 인터페이스를 사용했습니다. 추가 테스트 결과, 인터페이스 수를 2개, 4개 또는 8개로 늘려도 처리량에 큰 변화가 없었으며, 이는 이 워크로드에 단일 고대역폭 NIC만으로도 충분함을 나타냅니다.
8xH100 분산 학습 성능 비교는 그림 7을 참조하세요.
결론 및 전략적 권장 사항
이 포괄적인 테스트의 결과는 OpenShift에서 분산형 AI 교육을 최적화하기 위한 몇 가지 주요 결과를 보여줍니다.
무엇보다도, 기본 OpenShift Pod 네트워크는 고성능 분산 워크로드를 처리하기에 부족하여 심각한 병목 현상을 발생시키고, 이는 대규모로 진행될수록 더욱 심해집니다. 따라서 보조 네트워크를 활용하는 것이 필수적입니다.
L40S와 같은 미드티어 GPU 클러스터의 경우, 표준 vNIC는 상당히 적절한 성능 향상을 제공합니다. 그러나 H100 GPU를 사용하는 하이엔드 클러스터의 경우, 네트워크가 주요 제한 요소가 되므로 GPU 부족 현상을 방지하고 최적의 처리량을 달성하기 위해 SR-IOV와 같은 고처리량 솔루션이 필요합니다.
마지막으로, 테스트된 8B 모델에서는 RDMA의 이점이 미미했지만, 데이터에 따르면 보다 집중적인 노드 간 통신 요구 사항이 있는 대규모 모델을 학습할 때 RDMA의 가치가 중요해질 것으로 나타났습니다.
추천사항
테스트 결과를 바탕으로 다음과 같은 전략적 권장 사항을 제안합니다.
- 더 큰 모델에는 RDMA를 계획하십시오. 테스트된 8B 모델에는 필수적이지 않지만, 훨씬 더 큰 모델 학습을 위한 인프라를 계획할 때는 RDMA를 표준 요구 사항으로 고려해야 합니다. CPU 바이패스 기능이 네트워크 병목 현상 방지에 필수적이기 때문입니다.
- 다중 노드 학습에는 Pod 네트워크를 사용하지 마십시오. 기본 OpenShift SDN은 분산 학습에 필요한 고대역폭, 저지연 통신에 적합하지 않습니다. 다중 노드 워크로드에는 사용하지 않는 것이 좋습니다.
- 네트워크 기술을 GPU 계층에 맞게 조정하세요. 중간급 GPU(예: L40S)를 사용하는 클러스터의 경우, 표준 vNIC는 상당한 성능 향상을 제공하며 우수한 확장성을 확보하는 데 비용 효율적인 솔루션입니다.
- 고성능 GPU에 SR-IOV를 의무화하십시오. 최고급 GPU(예: H100)가 장착된 클러스터의 경우 SR-IOV는 필수적입니다. SR-IOV는 상당한 성능 향상을 제공하며, 네트워크가 주요 병목 현상이 되는 것을 방지하고 GPU 투자를 최대한 활용하는 데 필수적입니다.


