쿠버네티스의 조기 채택에는 일반적으로 베어메탈 인프라에 구축된 대형 클러스터가 상대적으로 적은 패턴이 포함되었다. 클러스터에서 실행 중인 애플리케이션은 순간적으로 삭제되는 경향이 있지만, 클러스터 자체는 그렇지 않았다. 오늘날 우리가 보고 있는 것은 개별 개발 팀, 프로젝트 또는 심지어 애플리케이션과 연계된 많은 소규모 클러스터로의 전환이다. 이러한 클러스터는 수동으로 배포할 수 있지만, 대개 정적 스크립트나 CI/CD 파이프라인 등 자동화의 결과인 경우가 많다. 정의되는 특성은 클러스터에서 실행되는 애플리케이션만 수명이 짧은 것은 아니다. 덧없지만, 클러스터 자체는 같은 패턴을 따른다.
쿠버네티스 클러스터는 주문형 리소스로 구축될 수 있지만 로깅, 메트릭, 이미지 등록 또는 영구 데이터베이스와 같은 핵심 인프라 서비스에 대한 액세스가 필요한 경우가 많다. 이러한 서비스는 오래 지속되고 여러 클러스터에서 이상적으로 공유되는 경향이 있다. 또한 이를 소비해야 하는 “워크로드 클러스터”와 다른 리소스, 가용성 또는 보안 요구사항도 있을 수 있다. 요컨대, 인프라 서비스는 워크로드 클러스터와 별도로 배치되고 관리될 수 있지만, 인프라 서비스에 의존하는 애플리케이션 서비스를 수정할 필요 없이 쉽게 액세스할 수 있어야 한다.
애플리케이션과 인프라 서비스를 별도의 클러스터로 분리하는 것은 분명해 보일 수 있지만, 한 클러스터에서 다른 클러스터에서 실행되는 서비스에 워크로드를 연결하는 것은 다소 까다로울 수 있다. 이 글과 첨부된 데모 비디오는 Kubernetes 서비스와 워크로드 클러스터의 애플리케이션이 별도의 클러스터에서 실행되는 인프라 서비스를 소비할 수 있도록 클러스터 간 연결을 설정하는 방법을 설명한다.
쿠버네티스 서비스란?
여러분 대부분이 알고 있듯이, 쿠버네티스 서비스는 일련의 포드에서 실행되는 애플리케이션을 발견하고, 그것을 네트워크 서비스로 노출시킬 수 있는 방법을 제공한다. 각 서비스는 단일 DNS 이름을 얻고, 기본 포드에 대한 라우팅을 제공한다. 이를 통해 IP의 변화 및 잠재적인 DNS 캐싱 문제가 있는 순간 삭제 포드의 당면 과제를 해결한다.
서비스는 “Selector”를 포함하는 사양을 사용하여 생성된다. 이 Selector에는 서비스를 구성하는 포드를 정의하는 레이블 세트가 포함되어 있다. 서비스를 구성하는 포드의 IP는 Endpoint는 쿠버네티스 객체에 추가된다. 포드가 죽거나 새 IP로 다시 생성될 때 엔드포인트가 업데이트된다.
서비스는 다른 서비스에 대한 액세스가 필요한 경우 클러스터에서 실행 중인 DNS 서버에 대한 DNS 조회를 수행한 다음 반환된 ClusterIP를 통해 서비스에 액세스한다.

이 경우 웹 앱 포드는 동일한 쿠베르네츠 클러스터의 다른 네임스페이스에서 실행되는 db 서비스에 액세스해야 한다. 포드는 DNS 검색에서 “servicename.namespace.svc.cluster.local”을 지정하여 서비스를 호출한다.
일반적으로 클러스터에서 포드로 실행되는 core-dns와 같은 DNS 서버는 클러스터 IP를 반환한다. 그런 다음 web-app 포드는 클러스터 IP를 통해 db 서비스를 호출한다. Cluster IP는 클러스터에 정의된 가상 IP이다. 물리적 인터페이스는 없지만, 이 가상 인터페이스에서 기본 포드 IP로의 라우팅은 클러스터 노드로 연결된다. 이 연결은 클러스터에 대해 구현된 네트워킹에만 해당된다. 여기서 중요한 점은 엔드포인트 객체가 쿠베르네츠 서비스에 정의된 Selector를 기반으로 자동으로 업데이트되고 web-app 포드는 이러한 IP에 대해 아무것도 알 필요가 없다는 것이다.
DB Service와 Web-App Service가 서로 다른 클러스터에 있는 경우 어떻게 하시겠습니까?
만약 우리 조직이 데이터베이스 서비스가 중앙집중식 클러스터에 상주하는 공유 서비스 모델을 채택하기를 원한다면, 웹앱은 별도의 클러스터에 배치될 것이다. 쿠버네티스가 포함된 vSphere 7의 경우, 공유 데이터베이스 서비스를 슈퍼바이저 클러스터에 배포하고 vSphere 포드 서비스를 하이퍼바이저에서 직접 실행되는 포드로 배포할 수 있다. 이 모델은 VM의 리소스 및 보안 격리 기능을 제공하지만 Kubernetes 포드 및 서비스 조정 기능을 통해 Web-App은 Tanzu Kubernetes 클러스터에 배치될 수 있다. TK 클러스터는 Tanzu Kubernetes Grid Service for vSphere를 통해 구축되며 애플리케이션의 비공유 인프라 구성요소를 위해 완전히 일치하고 업스트림 정렬된 Kubernetes 클러스터를 제공한다. 데이터베이스 포드를 실행하기 위해 다른 TK 클러스터를 쉽게 사용할 수 있었다는 점에 유의한다. 여기서 요점은 클러스터 간에 애플리케이션 구성요소를 분리하는 것이다.

일단 TK 클러스터에 배치되면 web-app 포드가 db 서비스를 호출하려고 시도하지만 DNS 조회가 실패한다. DNS 서버가 클러스터에 로컬이고 슈퍼바이저 클러스터에서 실행 중인 db 서비스에 대한 항목이 없기 때문이다. 항목이 있다고 해도 반환된 db 서비스의 클러스터 IP는 TK 클러스터에서 액세스할 수 있는 라우팅 가능한 IP가 아닐 것이다. 우리는 이 두 가지 문제를 해결해야 한다.
db Service를 클러스터 외부에 노출
우리가 가장 먼저 해야 할 일은 클러스터 외부에서 db 서비스에 인그레스를 제공하는 것이다. 이것은 표준 쿠버네티스 서비스 능력이다. 우리는 LoadBalancer 타입으로 서비스를 변경하겠다. 이로 인해 NSX는 기존 슈퍼바이저 클러스터 로드 밸런서에 가상 서버를 할당하고 라우팅 가능한 수신 IP를 할당하게 된다. 이 IP는 슈퍼바이저 클러스터 생성 시 정의된 수신 IP 범위에서 생성된다.


Tanzu Kubernetes 클러스터를 사용하여 Selectorless 서비스 생성
일단 db 서비스가 클러스터 외부에서 접근 가능하게 되면, 우리는 Web-App 서비스가 TK 클러스터로부터 발견할 수 있는 방법이 필요하다. 이는 셀렉터리스 서비스를 사용하여 수행할 수 있다. Endpoint 개체는 서비스와 연결된 포드의 IP를 보유하고 있으며 선택기 레이블을 통해 채워져 있다는 점을 기억하십시오. 위의 예에서, app: db로 레이블된 포드는 db 서비스의 일부분이다. Selector 없이 서비스를 생성할 때 쿠베르네츠 컨트롤러에 의해 자동으로 유지되는 엔드포인트 개체가 없으므로 직접 채운다. Selectorless 서비스와 Endpoint를 만들 것이다. 엔드포인트는 db 서비스의 로드 밸런서 VIP로 채워진다.


이제 우리의 web-app은 db 서비스를 로컬로 조회할 수 있고, DNS는 로컬 서비스의 클러스터 IP를 반환할 것이며, 이 IP는 슈퍼바이저 클러스터의 db 서비스와 연결된 로드 밸런싱 장치의 끝점으로 확인될 것이다.
이제 이 개념을 클러스터 간에 여러 서비스가 구축된 애플리케이션으로 확장해 봅시다. ACME Fitness Shop은 온라인 상점의 기능을 시뮬레이션하는 서비스 세트로 구성된 데모 어플리케이션이다. 개별 서비스는 서로 다른 언어로 작성되며 다양한 데이터베이스와 캐시에 의해 지원된다. 이 앱에 대한 자세한 내용은 https://github.com/vmwarecloudadvocacy/acme_fitness_demo을 참조한다. 데이터베이스를 슈퍼바이저 클러스터에 중앙 집중화하고 ESXi에서 직접 네이티브 포드로 실행하는 한편, 나머지 애플리케이션 워크로드는 Tanzu Kubernetes Service for vSphere를 통해 관리되는 TK 클러스터에 배포한다.
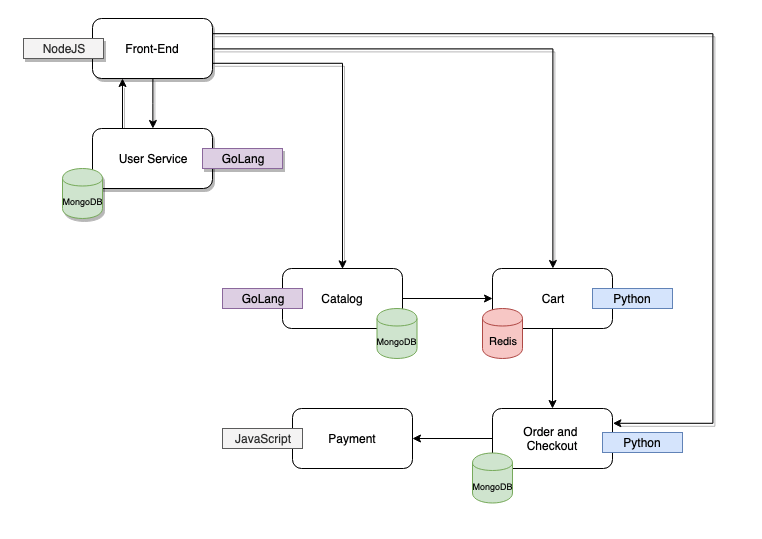
그 과정은 앞의 예와 같다. 데이터베이스 포드는 각 포드에 대한 로드 밸런서 서비스와 함께 슈퍼바이저 클러스터에 배포된다.
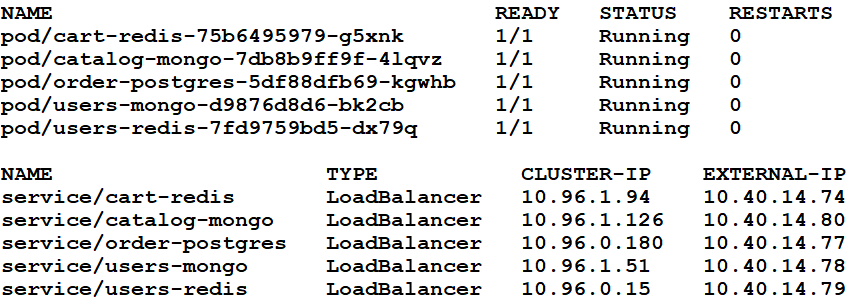
Selectorless 서비스는 TK 클러스터에 생성되며, 엔드포인트는 감독자 클러스터에서 실행되는 데이터베이스의 해당 로드 밸런서 서비스의 가상 IP로 업데이트된다. 나머지 비 데이터베이스 애플리케이션 서비스도 이 TK 클러스터에 배치된다.

Selectorless Services:

서비스 엔드포인트:

행동으로 보자!!
이 비디오는 Shared IT 인프라 서비스의 간단한 예를 살펴본 후 ACME Fit 애플리케이션을 동일한 방식으로 실제로 배치한다.




