Proxmox VE 매뉴얼을 DeepL/Google Translate로 기계번역하고, 살짝 교정했습니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html
version 8.1.4, Wed Mar 6 18:21:39 CET 2024
Proxmox VE 클러스터 관리자 pvecm은 물리적 서버 그룹을 만드는 도구입니다. 이러한 그룹을 클러스터라고 합니다. 안정적인 그룹 통신을 위해 Corosync 클러스터 엔진을 사용합니다. 클러스터의 노드 수에 대한 명시적인 제한은 없습니다. 실제로 가능한 실제 노드 수는 호스트 및 네트워크 성능에 따라 제한될 수 있습니다. 현재(2021년), 50개 이상의 노드가 있는 클러스터(하이엔드 엔터프라이즈 하드웨어 사용)가 운영되고 있다는 보고가 있습니다.
pvecm은 새 클러스터 생성, 클러스터에 노드 가입, 클러스터 탈퇴, 상태 정보 가져오기 및 기타 다양한 클러스터 관련 작업을 수행하는 데 사용할 수 있습니다. Proxmox Cluster File System(“pmxcfs”)은 클러스터 구성을 모든 클러스터 노드에 투명하게 배포하는 데 사용됩니다.
노드를 클러스터로 그룹화하면 다음과 같은 이점이 있습니다:
- 중앙 집중식 웹 기반 관리
- 멀티 마스터 클러스터: 각 노드가 모든 관리 작업을 수행할 수 있습니다.
- 데이터베이스 기반 파일 시스템인 pmxcfs를 사용하여 구성 파일을 저장하고, 코로싱크를 사용하여 모든 노드에 실시간으로 복제합니다.
- 물리적 호스트 간에 가상 머신과 컨테이너의 손쉬운 마이그레이션
- 빠른 배포
- 방화벽 및 HA와 같은 클러스터 전체 서비스
5.1. 요구 사항
- corosync가 작동하려면 모든 노드가 UDP 포트 5405-5412를 통해 서로 연결할 수 있어야 합니다.
- 날짜와 시간이 동기화되어야 합니다.
- 노드 간 TCP 포트 22의 SSH 터널이 필요합니다.
- 고가용성에 관심이 있는 경우 안정적인 쿼럼을 위해 최소 3개의 노드가 있어야 합니다. 모든 노드의 버전이 동일해야 합니다.
- 특히 공유 스토리지를 사용하는 경우에는 클러스터 트래픽을 위한 전용 NIC를 사용하는 것이 좋습니다.
- 노드를 추가하려면 클러스터 노드의 root 비밀번호가 필요합니다.
- 가상 머신의 온라인 마이그레이션은 노드에 동일한 공급업체의 CPU가 있는 경우에만 지원됩니다. 그렇지 않은 경우에도 작동할 수 있지만 보장되지는 않습니다.
참고: proxmox VE 3.x 및 이전 버전과 proxmox VE 4.X 클러스터 노드를 혼합할 수 없습니다.
참고: Proxmox VE 4.4와 Proxmox VE 5.0 노드를 혼합할 수는 있지만 프로덕션 구성으로 지원되지 않으며 전체 클러스터를 주요 버전에서 다른 버전으로 업그레이드하는 동안에만 일시적으로 수행해야 합니다.
참고: 이전 버전으로 proxmox VE 6.x 클러스터를 실행할 수 없습니다. proxmox VE 6.x와 이전 버전 간의 클러스터 프로토콜(corosync)이 근본적으로 변경되었습니다. Proxmox VE 5.4용 corosync 3 패키지는 Proxmox VE 6.0으로의 업그레이드 절차 전용입니다.
5.2 노드 준비
먼저 모든 노드에 Proxmox VE를 설치합니다. 각 노드가 최종 호스트 이름 및 IP 구성으로 설치되었는지 확인합니다. 클러스터 생성 후에는 호스트 이름과 IP를 변경할 수 없습니다.
일반적으로 모든 노드 이름과 해당 IP를 /etc/hosts에서 참조하거나 다른 방법으로 이름을 확인할 수 있도록 하는 것이 일반적이지만, 클러스터가 작동하는 데 반드시 필요한 것은 아닙니다. 하지만 기억하기 쉬운 노드 이름을 사용하여 SSH를 통해 한 노드에서 다른 노드로 연결할 수 있으므로 유용할 수 있습니다(링크 주소 유형도 참조하세요). 클러스터 구성에서는 항상 노드를 IP 주소로 참조하는 것이 좋습니다.
5.3. 클러스터 만들기
콘솔에서 클러스터를 만들거나(ssh를 통해 로그인), Proxmox VE 웹 인터페이스(Datacenter → Cluster)를 사용하여 API를 통해 클러스터를 만들 수 있습니다.
참고: 클러스터에 고유한 이름을 사용하세요. 이 이름은 나중에 변경할 수 없습니다. 클러스터 이름은 노드 이름과 동일한 규칙을 따릅니다.
5.3.1. 웹 GUI를 통해 생성
Datacenter → Cluster에서 Create Cluster을 클릭합니다. 클러스터 이름을 입력하고 드롭다운 목록에서 주 클러스터 네트워크로 사용할 네트워크 연결을 선택합니다(Link 0). 기본값은 노드의 호스트 이름을 통해 확인된 IP입니다.
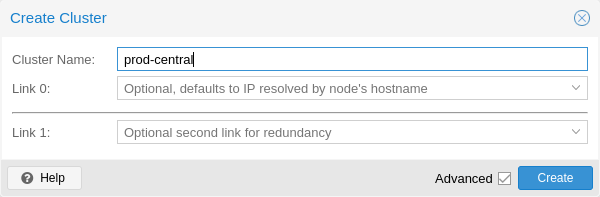
Proxmox VE 6.2부터 클러스터에 최대 8개의 예비 링크를 추가할 수 있습니다. 중복 링크를 추가하려면 추가 버튼을 클릭하고 각 필드에서 링크 번호와 IP 주소를 선택합니다. Proxmox VE 6.2 이전 버전에서는 두 번째 링크를 폴백으로 추가하려면 고급 확인란을 선택하고 추가 네트워크 인터페이스를 선택할 수 있습니다(Link 1, Corosync Redundancy 참조).
참고: 클러스터 통신을 위해 선택한 네트워크가 네트워크 스토리지 또는 실시간 마이그레이션과 같이 트래픽이 많은 용도로 사용되지 않는지 확인하세요. 클러스터 네트워크 자체는 소량의 데이터를 생성하지만 지연 시간에 매우 민감합니다. 전체 클러스터 네트워크 요구 사항을 확인하세요.
5.3.2. 명령줄을 통해 만들기
ssh를 통해 첫 번째 Proxmox VE 노드에 로그인하고 다음 명령을 실행합니다:
hp1# pvecm create CLUSTERNAME
새 클러스터 사용 상태를 확인하려면 다음과 같이 하세요:
# pvecm status
5.3.3. 동일한 네트워크의 여러 클러스터
동일한 물리적 또는 논리적 네트워크에 여러 개의 클러스터를 만들 수 있습니다. 이 경우 클러스터 통신 스택에서 발생할 수 있는 충돌을 피하기 위해 각 클러스터는 고유한 이름을 가져야 합니다. 이렇게 하면 클러스터를 명확하게 구분할 수 있어 사람이 혼동하는 것을 방지할 수 있습니다.
corosync 클러스터의 대역폭 요구 사항은 상대적으로 낮지만, 패키지 지연 시간과 초당 패키지 전송률(PPS)이 제한 요소입니다. 동일한 네트워크에 있는 여러 클러스터가 이러한 리소스를 놓고 서로 경쟁할 수 있으므로 대규모 클러스터의 경우 별도의 물리적 네트워크 인프라를 사용하는 것이 좋습니다.
5.4. 클러스터에 노드 추가하기
주의: 클러스터에 참여할 때 /etc/pve의 모든 기존 구성을 덮어씁니다. 특히, 가입 노드는 게스트 ID가 충돌할 수 있으므로 게스트를 보유할 수 없으며, 노드는 클러스터의 스토리지 구성을 상속받게 됩니다. 기존 게스트가 있는 노드에 참여하려면 해결 방법으로 각 게스트의 백업을 만든 다음(vzdump 사용) 참여 후 다른 ID로 복원할 수 있습니다. 노드의 스토리지 레이아웃이 다른 경우, 노드의 스토리지를 다시 추가하고 각 스토리지의 노드 제한을 조정하여 실제로 사용 가능한 노드에 반영해야 합니다.
5.4.1. GUI를 통해 클러스터에 노드 가입
기존 클러스터 노드에서 웹 인터페이스에 로그인합니다. Datacenter → Cluster에서 상단의 Join Information 버튼을 클릭합니다. 그런 다음 Copy Information 버튼을 클릭합니다. 또는 Information 필드에서 문자열을 수동으로 복사합니다.
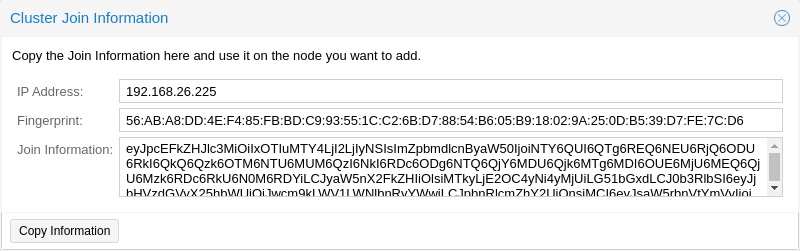
그런 다음 추가하려는 노드의 웹 인터페이스에 로그인합니다. Datacenter → Cluster에서 Join Cluster를 클릭합니다. Information 필드에 앞서 복사한 Join Information 텍스트를 입력합니다. 클러스터에 가입하는 데 필요한 대부분의 설정이 자동으로 채워집니다. 보안상의 이유로 클러스터 비밀번호는 수동으로 입력해야 합니다.
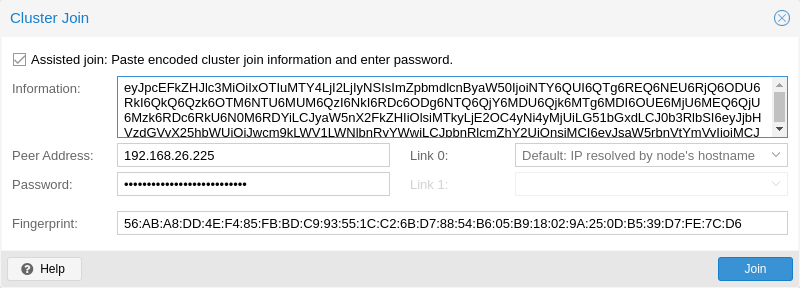
참고: 모든 필수 데이터를 수동으로 입력하려면 지원 조인 확인란을 비활성화하면 됩니다.
Join 버튼을 클릭하면 클러스터 조인 프로세스가 즉시 시작됩니다. 노드가 클러스터에 참여하면 현재 노드 인증서가 클러스터 CA(인증 기관)에서 서명한 인증서로 대체됩니다. 즉, 현재 세션은 몇 초 후에 작동이 중지됩니다. 그런 다음 웹 인터페이스를 강제 새로고침하고 클러스터 자격 증명으로 다시 로그인해야 할 수도 있습니다.
이제 노드가 Datacenter → Cluster 아래에 표시되어야 합니다.
5.4.2. 명령줄을 통해 클러스터에 노드 가입
기존 클러스터에 가입하려는 노드에 ssh를 통해 로그인합니다.
# pvecm add IP-ADDRESS-CLUSTER
IP-ADDRESS-CLUSTER의 경우 기존 클러스터 노드의 IP 또는 호스트 이름을 사용합니다. IP 주소를 사용하는 것이 좋습니다(링크 주소 유형 참조).
클러스터 상태를 확인하려면 다음을 사용합니다:
# pvecm status
4 노드 추가한 다음 클러스터 상태
# pvecm status
Cluster information
~~~~~~~~~~~~~~~~~~~
Name: prod-central
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
~~~~~~~~~~~~~~~~~~
Date: Tue Sep 14 11:06:47 2021
Quorum provider: corosync_votequorum
Nodes: 4
Node ID: 0x00000001
Ring ID: 1.1a8
Quorate: Yes
Votequorum information
~~~~~~~~~~~~~~~~~~~~~~
Expected votes: 4
Highest expected: 4
Total votes: 4
Quorum: 3
Flags: Quorate
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
0x00000001 1 192.168.15.91
0x00000002 1 192.168.15.92 (local)
0x00000003 1 192.168.15.93
0x00000004 1 192.168.15.94모든 노드 목록만 원하는 경우, 사용:
# pvecm nodes
클러스터에 있는 노드 목록
# pvecm nodes
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
1 1 hp1
2 1 hp2 (local)
3 1 hp3
4 1 hp45.4.3. 분리된 클러스터 네트워크로 노드 추가하기
분리된 클러스터 네트워크가 있는 클러스터에 노드를 추가할 때는 link0 매개변수를 사용하여 해당 네트워크의 노드 주소를 설정해야 합니다:
# pvecm add IP-ADDRESS-CLUSTER --link0 LOCAL-IP-ADDRESS-LINK0
Kronosnet 전송 계층의 기본 제공 중복성을 사용하려면 link1 매개변수도 사용하세요.
GUI를 사용하면 클러스터 조인 대화 상자의 해당 Link X 필드에서 올바른 인터페이스를 선택할 수 있습니다.
5.5. 클러스터 노드 제거
주의: 이 절차는 사용자가 원하거나 필요로 하는 것과 다를 수 있으므로 계속 진행하기 전에 절차를 주의 깊게 읽으세요.
노드에서 모든 가상 머신을 이동합니다. 보관하려는 로컬 데이터 또는 백업의 복사본을 만들었는지 확인하세요. 또한 제거할 노드에 대해 예약된 복제 작업을 모두 제거해야 합니다.
주의: 노드를 제거하기 전에 해당 노드에 대한 복제 작업을 제거하지 않으면 복제 작업을 제거할 수 없게 됩니다. 특히 복제된 VM이 마이그레이션되면 복제 방향이 자동으로 전환되므로 삭제할 노드에서 복제된 VM을 마이그레이션하면 복제 작업이 해당 노드로 자동으로 설정됩니다.
다음 예에서는 클러스터에서 노드 hp4를 제거합니다.
hp4가 아닌 다른 클러스터 노드에 로그인하고 pvecm nodes 명령을 실행하여 제거할 노드 ID를 식별합니다:
hp1# pvecm nodes
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
1 1 hp1 (local)
2 1 hp2
3 1 hp3
4 1 hp4이 시점에서 hp4의 전원을 끄고 현재 구성으로 (네트워크에서) 다시 전원이 켜지지 않는지 확인해야 합니다.
중요: 위에서 언급했듯이 제거하기 전에 노드의 전원을 끄고 현재 구성으로 (기존 클러스터 네트워크에서) 다시 전원이 켜지지 않는지 확인하는 것이 중요합니다. 노드의 전원을 그대로 켜면 클러스터가 중단될 수 있으며, 정상 작동 상태로 복원하기 어려울 수 있습니다.
노드 hp4의 전원을 끄면 클러스터에서 안전하게 제거할 수 있습니다.
hp1# pvecm delnode hp4 Killing node 4
참고: 이 시점에서 노드를 죽일 수 없습니다(오류 = CS_ERR_NOT_EXIST)라는 오류 메시지가 표시될 수 있습니다. 이는 실제 노드 삭제에 실패했다는 뜻이 아니라 오프라인 노드를 죽이려고 시도하는 corosync의 실패를 의미합니다. 따라서 안전하게 무시해도 됩니다.
노드 목록을 다시 확인하려면 pvecm 노드 또는 pvecm 상태를 사용하세요. 다음과 같이 보일 것입니다:
hp1# pvecm status
...
Votequorum information
~~~~~~~~~~~~~~~~~~~~~~
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
0x00000001 1 192.168.15.90 (local)
0x00000002 1 192.168.15.91
0x00000003 1 192.168.15.92어떤 이유로든 이 서버를 동일한 클러스터에 다시 참여시키려면 다음과 같이 해야 합니다:
- 해당 서버에 Proxmox VE를 새로 설치합니다,
- 그런 다음 이전 섹션에서 설명한 대로 가입해야 합니다.
제거된 노드의 구성 파일은 여전히 /etc/pve/nodes/hp4에 남아 있습니다. 필요한 구성이 있으면 복구하고 나중에 디렉터리를 제거하세요.
참고 :노드를 제거한 후에도 해당 노드의 SSH 지문은 다른 노드의 알려진_호스트에 계속 남아 있습니다. 동일한 IP 또는 호스트 이름을 가진 노드에 다시 가입한 후 SSH 오류가 발생하면 다시 추가된 노드에서 pvecm updatecerts를 한 번 실행하여 지문 클러스터 전체를 업데이트하세요.
5.5.1. 재설치하지 않고 노드 분리
주의: 이 방법은 권장되는 방법이 아니므로 주의해서 진행하세요. 확실하지 않은 경우 이전 방법을 사용하세요.
노드를 처음부터 다시 설치하지 않고 클러스터에서 노드를 분리할 수도 있습니다. 그러나 클러스터에서 노드를 제거한 후에도 노드는 공유 스토리지에 계속 액세스할 수 있습니다. 클러스터에서 노드 제거를 시작하기 전에 이 문제를 해결해야 합니다. 스토리지 잠금은 클러스터 경계에서 작동하지 않으므로 Proxmox VE 클러스터는 다른 클러스터와 정확히 동일한 스토리지를 공유할 수 없습니다. 또한 VMID 충돌이 발생할 수도 있습니다.
분리하려는 노드만 액세스할 수 있는 새 스토리지를 만드는 것이 좋습니다. 예를 들어 NFS에 새 내보내기 또는 새 Ceph 풀을 만들 수 있습니다. 여러 클러스터에서 똑같은 스토리지에 액세스하지 않는 것이 중요합니다. 이 스토리지를 설정한 후 모든 데이터와 VM을 노드에서 이 스토리지로 이동합니다. 그러면 노드를 클러스터에서 분리할 준비가 된 것입니다.
경고: 모든 공유 리소스가 깨끗하게 분리되어 있는지 확인하세요! 그렇지 않으면 충돌과 문제가 발생할 수 있습니다.
먼저 노드에서 corosync 및 pve-cluster 서비스를 중지합니다:
systemctl stop pve-cluster systemctl stop corosync
로컬 모드에서 클러스터 파일 시스템을 다시 시작합니다:
pmxcfs -l
corosync 구성 파일을 삭제합니다:
rm /etc/pve/corosync.conf rm -r /etc/corosync/*
이제 파일 시스템을 정상 서비스로 다시 시작할 수 있습니다:
killall pmxcfs systemctl start pve-cluster
이제 노드가 클러스터에서 분리되었습니다. 클러스터의 나머지 노드에서 해당 노드를 삭제할 수 있습니다:
pvecm delnode oldnode
나머지 노드의 정족수 부족으로 인해 명령이 실패하는 경우 해결 방법으로 예상 투표수를 1로 설정할 수 있습니다:
pvecm expected 1
그런 다음 pvecm delnode 명령을 반복합니다.
이제 분리된 노드로 다시 전환하여 노드에 남아 있는 모든 클러스터 파일을 삭제합니다. 이렇게 하면 노드를 문제 없이 다른 클러스터에 다시 추가할 수 있습니다.
rm /var/lib/corosync/*
다른 노드의 구성 파일이 여전히 클러스터 파일 시스템에 있으므로 이 파일도 정리해야 할 수 있습니다. 노드 이름이 올바른지 확실히 확인한 후 /etc/pve/nodes/NODENAME에서 전체 디렉터리를 재귀적으로 제거하면 됩니다.
주의: 노드의 SSH 키는 authorized_key 파일에 남아 있습니다. 즉, 노드는 여전히 공개 키 인증을 통해 서로 연결할 수 있습니다. 이 문제는 /etc/pve/priv/authorized_keys 파일에서 해당 키를 제거하여 해결해야 합니다.
5.6 쿼럼(Quorum)
Proxmox VE는 쿼럼 기반 기술을 사용하여 모든 클러스터 노드 간에 일관된 상태를 제공합니다.
쿼럼은 분산 시스템에서 작업을 수행하기 위해 분산 트랜잭션이 획득해야 하는 최소 투표 수입니다.
쿼럼(분산 컴퓨팅) – Wikipedia에서
네트워크 파티셔닝의 경우 상태를 변경하려면 과반수의 노드가 온라인 상태여야 합니다. 클러스터가 쿼럼을 잃으면 클러스터는 읽기 전용 모드로 전환됩니다.
참고: Proxmox VE는 기본적으로 각 노드에 단일 투표를 할당합니다.
5.7. 클러스터 네트워크
클러스터 네트워크는 클러스터의 핵심입니다. 이 네트워크를 통해 전송되는 모든 메시지는 모든 노드에 각각의 순서대로 안정적으로 전달되어야 합니다. Proxmox VE에서 이 부분은 고성능, 낮은 오버헤드, 고가용성 개발 툴킷의 구현인 corosync에 의해 수행됩니다. 이는 당사의 분산형 구성 파일 시스템(pmxcfs)을 제공합니다.
5.7.1. 네트워크 요구 사항
Proxmox VE 클러스터 스택이 안정적으로 작동하려면 모든 노드 간에 5밀리초 미만의 지연 시간(LAN 성능)을 갖춘 안정적인 네트워크가 필요합니다. 노드 수가 적은 설정에서는 지연 시간이 더 긴 네트워크가 작동할 수 있지만, 노드 수가 3개 이상이고 지연 시간이 약 10ms를 초과하는 경우에는 보장되지 않으며 오히려 가능성이 낮아집니다.
corosync는 대역폭을 많이 사용하지 않지만 지연 시간에 민감하므로 다른 멤버가 네트워크를 많이 사용해서는 안 되며, 이상적으로는 물리적으로 분리된 자체 네트워크에서 코로싱크를 실행하는 것이 좋습니다. 특히 중복 구성에서 우선순위가 낮은 폴백을 위한 경우를 제외하고는 corosync 및 스토리지에 공유 네트워크를 사용하지 마세요.
클러스터를 설정하기 전에 네트워크가 해당 목적에 적합한지 확인하는 것이 좋습니다. 클러스터 네트워크에서 노드가 서로 연결될 수 있는지 확인하기 위해 핑 도구를 사용하여 노드 간의 연결을 테스트할 수 있습니다.
Proxmox VE 방화벽이 사용 설정되어 있으면 corosync에 대한 수락 규칙이 자동으로 생성되므로 수동 작업이 필요하지 않습니다.
참고: corosync는 버전 3.0 이전에는 멀티캐스트를 사용했습니다(Proxmox VE 6.0에 도입됨). 최신 버전은 클러스터 통신을 위해 Kronosnet을 사용하며, 현재로서는 일반 UDP 유니캐스트만 지원합니다.
주의: corosync.conf에서 전송을 udp 또는 udpu로 설정하여 멀티캐스트 또는 레거시 유니캐스트를 계속 사용할 수 있지만 이렇게 하면 모든 암호화 및 중복성 지원이 비활성화된다는 점에 유의하세요. 따라서 이 방법은 권장하지 않습니다.
5.7.2. 별도의 클러스터 네트워크
매개 변수 없이 클러스터를 생성할 때 일반적으로 corosync 클러스터 네트워크는 웹 인터페이스 및 VM의 네트워크와 공유됩니다. 설정에 따라 스토리지 트래픽도 동일한 네트워크를 통해 전송될 수 있습니다. corosync는 시간이 중요한 실시간 애플리케이션이므로 이를 변경하는 것이 좋습니다.
새 네트워크 설정
먼저 새 네트워크 인터페이스를 설정해야 합니다. 이 인터페이스는 물리적으로 분리된 네트워크에 있어야 합니다. 네트워크가 클러스터 네트워크 요구 사항을 충족하는지 확인하세요.
클러스터 생성 시 분리
이는 새 클러스터를 만들 때 사용하는 pvecm create 명령의 linkX 매개 변수를 통해 가능합니다.
10.10.10.1/25에 고정 주소가 있는 추가 NIC를 설정하고 이 인터페이스를 통해 모든 클러스터 통신을 주고받으려는 경우 이 명령을 실행합니다:
pvecm create test --link0 10.10.10.1
모든 것이 제대로 작동하는지 확인하려면 실행하세요:
systemctl status corosync
그런 다음 위에서 설명한 대로 진행하여 분리된 클러스터 네트워크로 노드를 추가합니다.
클러스터 생성 후 분리
이미 클러스터를 만든 상태에서 전체 클러스터를 재구축하지 않고 통신을 다른 네트워크로 전환하려는 경우 이 작업을 수행할 수 있습니다. 이 변경으로 인해 노드가 corosync를 다시 시작하고 새 네트워크에 차례로 올라와야 하므로 클러스터의 쿼럼이 잠시 손실될 수 있습니다.
먼저 corosync.conf 파일을 편집하는 방법을 확인하세요. 그런 다음 파일을 열면 다음과 유사한 파일이 표시됩니다:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: due
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: tre
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: uno
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 3
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
}참고: ringX_addr은 실제로 corosync 링크 주소를 지정합니다. “ring”이라는 이름은 이전 버전과의 호환성을 위해 유지되는 이전 corosync 버전의 잔재입니다.
가장 먼저 해야 할 일은 노드 항목에 이름 속성이 아직 표시되지 않는 경우 추가하는 것입니다. 이 속성은 노드 이름과 일치해야 합니다.
그런 다음 모든 노드의 ring0_addr 속성에 있는 모든 주소를 새 주소로 바꿉니다. 여기에는 일반 IP 주소나 호스트 이름을 사용할 수 있습니다. 호스트명을 사용하는 경우 모든 노드에서 호스트명을 확인할 수 있는지 확인하세요(링크 주소 유형 참조).
이 예에서는 클러스터 통신을 10.10.10.0/25 네트워크로 전환하고자 하므로 각 노드의 ring0_addr을 각각 변경합니다.
참고: 동일한 절차를 사용하여 다른 ringX_addr 값도 변경할 수 있습니다. 그러나 한 번에 하나의 링크 주소만 변경하는 것이 문제 발생 시 복구가 더 쉽기 때문에 권장합니다.
config_version 속성을 변경한 후 새 구성 파일은 다음과 같아야 합니다:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: 10.10.10.2
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: 10.10.10.3
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: 10.10.10.1
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 4
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
}그런 다음 변경된 모든 정보가 올바른지 최종 확인한 후 저장하고 다시 한 번 corosync.conf 파일 편집 섹션에 따라 적용합니다.
변경 사항은 실시간으로 적용되므로 corosync를 반드시 다시 시작할 필요는 없습니다. 다른 설정도 변경했거나 corosync가 불평하는 경우 선택적으로 재시작을 트리거할 수 있습니다.
단일 노드에서 실행합니다:
systemctl restart corosync
이제 모든 것이 정상인지 확인하세요:
systemctl status corosync
corosync가 다시 작동하기 시작하면 다른 모든 노드에서도 다시 시작합니다. 그러면 새 네트워크에서 클러스터 멤버십에 하나씩 가입하게 됩니다.
5.7.3. corosync 주소
corosync 링크 주소(이전 버전과의 호환성을 위해 corosync.conf에서 ringX_addr로 표시됨)는 두 가지 방법으로 지정할 수 있습니다:
- IPv4/v6 주소를 직접 사용할 수 있습니다. 정적이며 일반적으로 부주의하게 변경되지 않으므로 이 방법을 권장합니다.
- 호스트 이름은 getaddrinfo를 사용하여 확인되므로 기본적으로 사용 가능한 경우 IPv6 주소가 먼저 사용됩니다(man gai.conf 참조). 특히 기존 클러스터를 IPv6로 업그레이드할 때는 이 점을 염두에 두세요.
주의: 호스트명은 corosync나 실행 중인 노드를 건드리지 않고도 확인 주소가 변경될 수 있으므로, corosync에 미치는 영향을 고려하지 않고 주소를 변경하는 상황이 발생할 수 있으므로 주의해서 사용해야 합니다.
호스트 네임이 필요한 경우 별도의 정적 호스트 네임을 사용하는 것이 좋습니다. 또한 클러스터의 모든 노드가 모든 호스트 이름을 올바르게 확인할 수 있는지 확인하세요.
Proxmox VE 5.1부터 지원되는 동안 호스트명은 진입 시점에 확인됩니다. 확인된 IP만 구성에 저장됩니다.
이전 버전에서 클러스터에 참여한 노드는 여전히 corosync.conf에서 확인되지 않은 호스트 이름을 사용할 가능성이 높습니다. 위에서 언급한 대로 IP 또는 별도의 호스트 이름으로 대체하는 것이 좋습니다.
5.8. Corosync 리던던시
Corosync는 기본적으로 통합 Kronosnet 계층을 통해 이중화 네트워킹을 지원합니다(레거시 udp/udpu 전송에서는 지원되지 않음). 클러스터를 생성하거나 새 노드를 추가하는 동안 GUI에서 pvecm의 –linkX 매개변수를 통해 Link 1로 지정하거나 corosync.conf에 둘 이상의 ringX_addr을 지정하여 둘 이상의 링크 주소를 지정하여 이 기능을 활성화할 수 있습니다.
참고: 유용한 장애 조치를 제공하려면 모든 링크가 자체 물리적 네트워크 연결에 있어야 합니다.
링크는 우선순위 설정에 따라 사용됩니다. 이 우선 순위는 corosync.conf의 해당 인터페이스 섹션에서 knet_link_priority를 설정하여 구성하거나, pvecm으로 클러스터를 생성할 때 우선 순위 매개 변수를 사용하여 구성할 수 있습니다:
# pvecm create CLUSTERNAME --link0 10.10.10.1,priority=15 --link1 10.20.20.1,priority=20
이렇게 하면 우선순위가 더 높은 link1이 먼저 사용됩니다.
우선순위를 수동으로 구성하지 않은 경우(또는 두 링크의 우선순위가 동일한 경우) 링크는 번호가 낮은 순서대로 사용되며, 낮은 번호가 높은 우선순위를 갖습니다.
모든 링크가 작동하더라도 우선순위가 가장 높은 링크에만 corosync 트래픽이 표시됩니다. 링크 우선순위는 혼합할 수 없으므로 우선순위가 다른 링크는 서로 통신할 수 없습니다.
우선순위가 낮은 링크는 우선순위가 높은 모든 링크가 실패하지 않는 한 트래픽을 볼 수 없으므로 다른 작업(VM, 스토리지 등)에 사용되는 네트워크를 우선순위가 낮은 링크로 지정하는 것이 유용한 전략이 될 수 있습니다. 최악의 경우 지연 시간이 길거나 혼잡한 연결이 전혀 연결되지 않는 것보다 나을 수 있습니다.
5.8.1. 기존 클러스터에 중복 링크 추가하기
실행 중인 구성에 새 링크를 추가하려면 먼저 corosync.conf 파일을 편집하는 방법을 확인하세요.
그런 다음 nodelist 섹션의 모든 노드에 새 ringX_addr을 추가합니다. 추가하는 모든 노드에서 X가 동일해야 하며, 각 노드마다 고유해야 합니다.
마지막으로 totem 섹션에 아래 그림과 같이 새 interface를 추가하고 X를 위에서 선택한 링크 번호로 바꿉니다.
번호가 1번인 링크를 추가했다고 가정하면 새 구성 파일은 다음과 같이 보일 수 있습니다:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: 10.10.10.2
ring1_addr: 10.20.20.2
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: 10.10.10.3
ring1_addr: 10.20.20.3
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: 10.10.10.1
ring1_addr: 10.20.20.1
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 4
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
interface {
linknumber: 1
}
}마지막 단계에 따라 corosync.conf 파일을 편집하는 즉시 새 링크가 활성화됩니다. 다시 시작할 필요는 없습니다. 다음을 사용하여 corosync가 새 링크를 로드했는지 확인할 수 있습니다:
journalctl -b -u corosync
한 노드에서 이전 링크를 일시적으로 연결 해제하고 연결이 해제된 상태에서 온라인 상태가 유지되는지 확인하여 새 링크를 테스트하는 것이 좋습니다:
pvecm status
클러스터 상태가 정상으로 표시되면 새 링크가 사용 중이라는 뜻입니다.
5.9. Proxmox VE 클러스터에서 SSH의 역할
Proxmox VE는 다양한 기능에 SSH 터널을 활용합니다.
- 콘솔/셸 세션 프록시(노드 및 게스트)
- 노드 A에 연결되어 있는 상태에서 노드 B의 셸을 사용하는 경우, 노드 A의 터미널 프록시에 연결되며, 이 터미널 프록시는 비대화형 SSH 터널을 통해 노드 B의 로그인 셸에 연결됩니다.
- 보안 모드에서 VM 및 CT 메모리와 로컬 스토리지 마이그레이션. 마이그레이션하는 동안 마이그레이션 정보를 교환하고 메모리 및 디스크 콘텐츠를 전송하기 위해 소스 노드와 대상 노드 간에 하나 이상의 SSH 터널이 설정됩니다.
- 스토리지 복제
중요: .bashrc 및 형제자매의 자동 실행으로 인한 함정
구성된 셸에 의해 로그인 시 실행되는 사용자 지정 .bashrc 또는 이와 유사한 파일이 있는 경우 세션이 성공적으로 설정되면 ssh가 자동으로 실행됩니다. 이러한 명령은 위에서 설명한 작업 중 하나에 대해 root 권한으로 실행될 수 있으므로 예기치 않은 동작이 발생할 수 있습니다. 이로 인해 문제가 될 수 있는 부작용이 발생할 수 있습니다!
이러한 문제를 방지하려면 /root/.bashrc를 추가하여 세션이 대화형인지 확인한 다음 .bashrc 명령만 실행하는 것이 좋습니다.
이 스니펫은 .bashrc 파일의 시작 부분에 추가할 수 있습니다:
# Early exit if not running interactively to avoid side-effects!
case $- in
*i*) ;;
*) return;;
esac이 섹션에서는 Proxmox VE 클러스터에 외부 투표기를 배포하는 방법에 대해 설명합니다. 이 방법을 구성하면 클러스터 통신의 안전 속성을 위반하지 않고 더 많은 노드 오류를 견딜 수 있습니다.
이 기능이 작동하려면 두 가지 서비스가 필요합니다:
- 각 Proxmox VE 노드에서 실행되는 QDevice 데몬
- 독립 서버에서 실행되는 외부 투표 데몬
결과적으로 소규모 설정(예: 2+1 노드)에서도 더 높은 가용성을 달성할 수 있습니다.
5.10.1. QDevice 기술 개요
Corosync Quorum Device(QDevice)는 각 클러스터 노드에서 실행되는 데몬입니다. 이 장치는 외부에서 실행되는 타사 중재자의 결정에 따라 클러스터의 쿼럼 하위 시스템에 구성된 투표 수를 제공합니다. 주요 용도는 클러스터가 표준 쿼럼 규칙이 허용하는 것보다 더 많은 노드 장애를 견딜 수 있도록 하는 것입니다. 외부 장치가 모든 노드를 볼 수 있으므로 투표할 노드 집합을 하나만 선택할 수 있으므로 안전하게 수행할 수 있습니다. 이는 타사 투표를 받은 후 해당 노드 세트가 다시 정족수를 확보할 수 있는 경우에만 수행됩니다.
현재 타사 중재자로는 QDevice Net만 지원됩니다. 이 데몬은 네트워크를 통해 파티션 멤버에게 도달할 수 있는 경우 클러스터 파티션에 투표권을 제공하는 데몬입니다. 한 번에 클러스터의 한 파티션에만 투표권을 부여합니다. 여러 클러스터를 지원하도록 설계되었으며 구성 및 상태가 거의 필요하지 않습니다. 새 클러스터는 동적으로 처리되며 QDevice를 실행하는 호스트에는 구성 파일이 필요하지 않습니다.
외부 호스트에 대한 유일한 요구 사항은 클러스터에 대한 네트워크 액세스 권한이 있어야 하고 corosync-qnetd 패키지를 사용할 수 있어야 한다는 것입니다. 저희는 Debian 기반 호스트를 위한 패키지를 제공하며, 다른 Linux 배포판도 해당 패키지 관리자를 통해 패키지를 사용할 수 있어야 합니다.
참고 corosync 자체와 달리, QDevice는 TCP/IP를 통해 클러스터에 연결합니다. 이 데몬은 클러스터의 LAN 외부에서도 실행할 수 있으며 corosync의 낮은 지연 시간 요구 사항에 제한되지 않습니다.
5.10.2. 지원되는 설정
노드 수가 짝수인 클러스터에는 QDevices를 지원하며, 더 높은 가용성을 제공해야 하는 경우 2노드 클러스터에 권장합니다. 노드 수가 홀수인 클러스터의 경우 현재 QDevices 사용을 권장하지 않습니다. 그 이유는 각 클러스터 유형에 대해 QDevice가 제공하는 투표의 차이 때문입니다. 짝수 클러스터는 하나의 추가 투표를 얻게 되므로 가용성만 증가하지만, QDevice 자체에 장애가 발생하면 QDevice가 전혀 없는 것과 같은 위치에 놓이게 됩니다.
반면, 클러스터 크기가 홀수인 경우, QDevice는 (N-1)의 투표를 제공하며, 여기서 N은 클러스터 노드 수에 해당합니다. 만약 추가 투표가 하나만 더 있다면 클러스터는 두뇌가 분할되는 상황에 처할 수 있기 때문에 이 대안적인 동작이 합리적입니다. 이 알고리즘은 한 노드를 제외한 모든 노드(그리고 당연히 QDevice 자체)가 실패할 수 있도록 허용합니다. 그러나 여기에는 두 가지 단점이 있습니다:
- QNet 데몬 자체가 실패하면 다른 노드는 실패하지 않거나 클러스터가 즉시 쿼럼을 잃을 수 있습니다. 예를 들어 15개의 노드가 있는 클러스터에서 클러스터가 쿼럼에 도달하기 전에 7개가 실패할 수 있습니다. 그러나 여기에 QDevice가 구성되어 있고 그 자체에 장애가 발생하면 15개 노드 중 단 하나의 노드도 장애가 발생하지 않을 수 있습니다. 이 경우 QDevice는 거의 단일 장애 지점처럼 작동합니다.
- 한 노드와 QDevice를 제외한 모든 노드가 장애를 일으킬 수 있다는 사실은 언뜻 그럴듯하게 들리지만, 이로 인해 HA 서비스가 대량으로 복구되어 남은 단일 노드에 과부하가 걸릴 수 있습니다. 또한 Ceph 서버는 ((N-1)/2) 노드 이하만 온라인 상태가 유지되면 서비스 제공을 중단합니다.
이러한 단점과 의미를 이해했다면 홀수 클러스터 설정에서 이 기술을 사용할지 여부를 직접 결정할 수 있습니다.
5.10.3. QDevice-Net 설정
권한이 없는 사용자로 corosync-qdevice에 투표를 제공하는 데몬을 실행하는 것이 좋습니다. Proxmox VE 및 Debian은 이미 그렇게 하도록 구성된 패키지를 제공합니다. 데몬과 클러스터 간의 트래픽을 암호화해야 Proxmox VE에서 QDevice를 안전하게 통합할 수 있습니다.
먼저, 외부 서버에 corosync-qnetd 패키지를 설치합니다.
external# apt install corosync-qnetd
그리고 모든 클러스터 노드에 corosync-qdevice 패키지를 설치합니다.
pve# apt install corosync-qdevice
이 작업을 완료한 후 클러스터의 모든 노드가 온라인 상태인지 확인합니다.
이제 Proxmox VE 노드 중 하나에서 다음 명령을 실행하여 QDevice를 설정할 수 있습니다:
pve# pvecm qdevice setup <QDEVICE-IP>
클러스터의 SSH 키가 QDevice에 자동으로 복사됩니다.
참고: 외부 서버에서 root 사용자에 대한 키 기반 액세스를 설정하거나 설정 단계에서 일시적으로 비밀번호로 root 로그인을 허용해야 합니다. 이 단계에서 호스트 키 확인에 실패했습니다와 같은 오류가 발생하면 pvecm 업데이트 인증서를 실행하면 문제를 해결할 수 있습니다.
모든 단계가 성공적으로 완료되면 “Done”가 표시됩니다. QDevice가 설정되었는지 확인할 수 있습니다:
pve# pvecm status
...
Votequorum information
~~~~~~~~~~~~~~~~~~~~~
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate Qdevice
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Qdevice Name
0x00000001 1 A,V,NMW 192.168.22.180 (local)
0x00000002 1 A,V,NMW 192.168.22.181
0x00000000 1 QdeviceQDevice 상태 플래그
위와 같이 QDevice의 상태 출력은 일반적으로 세 개의 열로 구성됩니다:
- A / NA: 살아있음 또는 살아있지 않음. 외부 corosync-qnetd 데몬과의 통신이 작동하는지 여부를 나타냅니다.
- V / NV: QDevice가 노드에 투표할 경우. 노드 간의 corosync 연결이 끊어졌지만 둘 다 외부 corosync-qnetd 데몬과 통신할 수 있는 스플릿 브레인 상황에서는 한 노드만 투표를 하게 됩니다.
- MW/NMW: 마스터가 승리(MV) 또는 승리하지 않음(NMW). 기본값은 NMW입니다([11] 참조).
- NR: QDevice가 등록되지 않았습니다.
참고: QDevice가 Not Alive(위 출력에서 NA)로 표시되는 경우 외부 서버의 포트 5403(qnetd 서버의 기본 포트)이 TCP/IP를 통해 연결 가능한지 확인하세요!
5.10.4. 자주 묻는 질문
타이 브레이킹
동점인 경우, 같은 크기의 클러스터 파티션 두 개가 서로를 볼 수 없지만 QDevice는 볼 수 있는 경우, QDevice는 해당 파티션 중 하나를 무작위로 선택하여 투표를 제공합니다.
가능한 부정적인 영향
노드 수가 짝수인 클러스터의 경우, QDevice를 사용할 때 부정적인 영향은 없습니다. 작동에 실패하면 QDevice가 전혀 없는 것과 마찬가지입니다.
QDevice 설정 후 노드 추가/삭제하기
QDevice가 설정된 클러스터에서 새 노드를 추가하거나 기존 노드를 제거하려면 먼저 QDevice를 제거해야 합니다. 그런 다음 정상적으로 노드를 추가하거나 제거할 수 있습니다. 노드 수가 다시 짝수인 클러스터가 되면 앞서 설명한 대로 QDevice를 다시 설정할 수 있습니다.
QDevice 제거하기
공식 pvecm 도구를 사용하여 QDevice를 추가한 경우, 실행하여 제거할 수 있습니다:
pve# pvecm qdevice remove
5.11. Corosync 구성
/etc/pve/corosync.conf 파일은 Proxmox VE 클러스터에서 중심적인 역할을 합니다. 이 파일은 클러스터 멤버십과 네트워크를 제어합니다. 이에 대한 자세한 내용은 corosync.conf 매뉴얼 페이지를 참조하세요:
man corosync.conf
노드 멤버십의 경우 항상 Proxmox VE에서 제공하는 pvecm 도구를 사용해야 합니다. 다른 변경 사항을 적용하려면 구성 파일을 수동으로 편집해야 할 수도 있습니다. 이를 수행하기 위한 몇 가지 모범 사례 팁은 다음과 같습니다.
5.11.1. corosync.conf 편집
corosync.conf 파일을 편집하는 것이 항상 간단한 것은 아닙니다. 각 클러스터 노드에는 두 개가 있으며, 하나는 /etc/pve/corosync.conf에 있고 다른 하나는 /etc/corosync/corosync.conf에 있습니다. 클러스터 파일 시스템에서 이를 편집하면 변경 사항이 로컬 파일 시스템에 전파되지만 그 반대의 경우는 전파되지 않습니다.
파일이 변경되는 즉시 구성이 자동으로 업데이트됩니다. 즉, 실행 중인 corosync에 통합할 수 있는 변경 사항이 즉시 적용됩니다. 따라서 편집하는 동안 파일을 저장할 때 의도하지 않은 변경이 발생하지 않도록 항상 복사하고 편집해야 합니다.
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.new
그런 다음 모든 Proxmox VE 노드에 사전 설치되어 있는 nano 또는 vim.tiny와 같은 즐겨 사용하는 편집기를 사용하여 구성 파일을 엽니다.
참고: 구성이 변경된 후에는 항상 config_version 번호를 늘리십시오. 이를 생략하면 문제가 발생할 수 있습니다.
필요한 변경을 수행한 후 현재 작업 구성 파일의 또 다른 복사본을 만듭니다. 이는 새 구성이 적용되지 않거나 다른 문제가 발생할 경우 백업 역할을 합니다.
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak
그런 다음 모든 Proxmox VE 노드에 사전 설치되어 있는 nano 또는 vim.tiny와 같은 즐겨 사용하는 편집기를 사용하여 구성 파일을 엽니다.
참고: 구성이 변경된 후에는 항상 config_version 번호를 늘리십시오. 이를 생략하면 문제가 발생할 수 있습니다.
필요한 변경을 수행한 후 현재 작업 구성 파일의 또 다른 복사본을 만듭니다. 이는 새 구성이 적용되지 않거나 다른 문제가 발생할 경우 백업 역할을 합니다.
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak
그런 다음 이전 구성 파일을 새 구성 파일로 바꿉니다.
mv /etc/pve/corosync.conf.new /etc/pve/corosync.conf
다음 명령을 사용하여 변경 사항이 자동으로 적용될 수 있는지 확인할 수 있습니다.
systemctl status corosync journalctl -b -u corosync
변경 사항을 자동으로 적용할 수 없는 경우 다음을 통해 corosync 서비스를 다시 시작해야 할 수 있습니다.
systemctl restart corosync
오류가 발생하면 아래 문제 해결 섹션을 확인하세요.
5.11.2. 문제 해결
문제: quorum.expected_votes를 구성해야 합니다.
corosync가 실패하기 시작하고 시스템 로그에 다음 메시지가 표시됩니다.
[...]
corosync[1647]: [QUORUM] Quorum provider: corosync_votequorum failed to initialize.
corosync[1647]: [SERV ] Service engine 'corosync_quorum' failed to load for reason
'configuration error: nodelist or quorum.expected_votes must be configured!'
[...]이는 구성에서 corosync ringX_addr에 대해 설정한 호스트 이름을 확인할 수 없음을 의미합니다.
할당되지 않은 경우 구성 쓰기
쿼럼이 없는 노드에서 /etc/pve/corosync.conf를 변경해야 하고 수행 중인 작업을 이해하는 경우 다음을 사용하십시오.
pvecm expected 1
그러면 예상 투표 수가 1로 설정되고 클러스터가 할당됩니다. 그런 다음 구성을 수정하거나 마지막 작업 백업으로 되돌릴 수 있습니다.
corosync를 더 이상 시작할 수 없으면 이것만으로는 충분하지 않습니다. 이 경우 corosync가 다시 시작될 수 있도록 /etc/corosync/corosync.conf에서 corosync 구성의 로컬 복사본을 편집하는 것이 가장 좋습니다. 브레인 분할 상황을 방지하려면 모든 노드에서 이 구성의 콘텐츠가 동일한지 확인하세요.
5.11.3. Corosync 구성 용어집
ringX_addr
이는 노드 간 Kronosnet 연결을 위한 다양한 링크 주소의 이름을 지정합니다.
5.12. 클러스터 콜드 스타트
모든 노드가 오프라인일 때 클러스터가 할당되지 않는다는 것은 명백합니다. 이는 정전 후 일반적인 경우입니다.
참고: 특히 HA를 원하는 경우 이러한 상태를 방지하려면 항상 무정전 전원 공급 장치(“UPS”, “배터리 백업”이라고도 함)를 사용하는 것이 좋습니다.
노드 시작 시 pve-guests 서비스가 시작되고 쿼럼을 기다립니다. 할당되면 onboot 플래그가 설정된 모든 게스트가 시작됩니다.
노드를 켜거나 정전 후 전원이 다시 들어올 때 일부 노드는 다른 노드보다 빠르게 부팅될 가능성이 높습니다. 정족수에 도달할 때까지 게스트 시작이 지연된다는 점에 유의하세요.
5.13. 게스트 VMID 자동 선택
새 게스트를 생성할 때 웹 인터페이스는 백엔드에 무료 VMID를 자동으로 요청합니다. 검색의 기본 범위는 100~1000000(스키마에서 적용되는 최대 허용 VMID보다 낮음)입니다.
때때로 관리자는 임시 VM을 VMID를 수동으로 선택하는 VM과 쉽게 분리하기 위해 별도의 범위에 새 VMID를 할당하려고 합니다. 다른 경우에는 안정적인 길이의 VMID를 제공하기를 원했는데, 이 경우 하한 경계를 예를 들어 100000으로 설정하면 훨씬 더 많은 공간이 제공됩니다.
이 사용 사례를 수용하려면 datacenter.cfg 구성 파일을 통해 하한, 상한 또는 두 경계를 모두 설정할 수 있습니다. 이 구성 파일은 웹 인터페이스의 Datacenter → 옵션에서 편집할 수 있습니다.
참고: 범위는 next-id API 호출에만 사용되므로 엄격한 제한은 아닙니다.
5.14. 게스트 마이그레이션
가상 게스트를 다른 노드로 마이그레이션하는 것은 클러스터의 유용한 기능입니다. 이러한 마이그레이션 동작을 제어하는 설정이 있습니다. 이는 구성 파일 datacenter.cfg를 통해 수행하거나 API 또는 명령줄 매개변수를 통해 특정 마이그레이션을 수행할 수 있습니다.
게스트가 온라인인지 오프라인인지, 또는 로컬 리소스(예: 로컬 디스크)가 있는지에 따라 차이가 있습니다.
가상 머신 마이그레이션에 대한 자세한 내용은 QEMU/KVM 마이그레이션 장을 참조하세요.
컨테이너 마이그레이션에 대한 자세한 내용은 컨테이너 마이그레이션 장을 참조하세요.
5.14.1. 마이그레이션 유형
마이그레이션 유형은 마이그레이션 데이터를 암호화된(보안) 채널 또는 암호화되지 않은(안전하지 않은) 채널을 통해 전송해야 하는지 정의합니다. 마이그레이션 유형을 안전하지 않음으로 설정하면 가상 게스트의 RAM 콘텐츠도 암호화되지 않은 상태로 전송되므로 게스트 내부에서 중요한 데이터(예: 비밀번호 또는 암호화 키)의 정보가 공개될 수 있습니다.
따라서 네트워크에 대한 완전한 제어 권한이 없고 누구도 네트워크를 도청하지 않는다는 것을 보장할 수 없는 경우 보안 채널을 사용하는 것이 좋습니다.
참고: 스토리지 마이그레이션은 이 설정을 따르지 않습니다. 현재는 항상 보안 채널을 통해 스토리지 콘텐츠를 보냅니다.
암호화에는 많은 컴퓨팅 성능이 필요하므로 더 나은 성능을 얻기 위해 이 설정을 안전하지 않음으로 변경하는 경우가 많습니다. 최신 시스템은 하드웨어에 AES 암호화를 구현하기 때문에 영향이 더 적습니다. 성능에 미치는 영향은 10Gbps 이상을 전송할 수 있는 빠른 네트워크에서 특히 두드러집니다.
5.14.2. 마이그레이션 네트워크
기본적으로 Proxmox VE는 클러스터 통신이 이루어지는 네트워크를 사용하여 마이그레이션 트래픽을 보냅니다. 민감한 클러스터 트래픽이 중단될 수 있고 이 네트워크가 노드에서 사용 가능한 최상의 대역폭을 갖지 못할 수 있기 때문에 이는 최적이 아닙니다.
마이그레이션 네트워크 매개변수를 설정하면 모든 마이그레이션 트래픽에 전용 네트워크를 사용할 수 있습니다. 이는 메모리 외에도 오프라인 마이그레이션을 위한 스토리지 트래픽에도 영향을 미칩니다.
마이그레이션 네트워크는 CIDR 표기법을 사용하여 네트워크로 설정됩니다. 이는 각 노드에 개별 IP 주소를 설정할 필요가 없다는 장점이 있습니다. Proxmox VE는 CIDR 형식에 지정된 네트워크에서 대상 노드의 실제 주소를 결정할 수 있습니다. 이를 활성화하려면 각 노드가 해당 네트워크에서 정확히 하나의 IP를 갖도록 네트워크를 지정해야 합니다.
예
우리는 3개의 별도 네트워크를 갖춘 3노드 설정이 있다고 가정합니다. 하나는 인터넷을 통한 공용 통신용, 하나는 클러스터 통신용, 그리고 매우 빠른 하나는 마이그레이션을 위한 전용 네트워크로 사용하려고 합니다.
이러한 설정을 위한 네트워크 구성은 다음과 같습니다.
iface eno1 inet manual
# public network
auto vmbr0
iface vmbr0 inet static
address 192.X.Y.57/24
gateway 192.X.Y.1
bridge-ports eno1
bridge-stp off
bridge-fd 0
# cluster network
auto eno2
iface eno2 inet static
address 10.1.1.1/24
# fast network
auto eno3
iface eno3 inet static
address 10.1.2.1/24여기서는 10.1.2.0/24 네트워크를 마이그레이션 네트워크로 사용하겠습니다. 단일 마이그레이션의 경우 명령줄 도구의 migration_network 매개변수를 사용하여 이 작업을 수행할 수 있습니다.
# qm migrate 106 tre --online --migration_network 10.1.2.0/24
이를 클러스터의 모든 마이그레이션에 대한 기본 네트워크로 구성하려면 /etc/pve/datacenter.cfg 파일의 마이그레이션 속성을 설정합니다.
# use dedicated migration network migration: secure,network=10.1.2.0/24
참고: 마이그레이션 유형은 항상 마이그레이션 네트워크가 /etc/pve/datacenter.cfg에 설정되어 있을 때 설정해야 합니다.



