Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://notes.xeome.dev/notes/Zram
소개
Zram은 압축된 가상 메모리 블록 장치를 활용하여 효율적인 메모리 관리를 가능하게 하는 커널 모듈입니다. 이 문서에서는 Zram에 사용되는 다양한 압축 알고리즘의 성능과 시스템에 미치는 영향을 분석합니다. 또한, 다양한 페이지 클러스터 값이 시스템 지연 시간과 처리량에 미치는 영향도 살펴봅니다.
압축 알고리즘 비교
다음 표는 Zram에 사용된 다양한 압축 알고리즘의 성능을 압축 시간, 데이터 크기, 압축 크기, 전체 크기 및 압축 비율 측면에서 비교한 것입니다.
Linux 리뷰 의 데이터 :
| 연산 | Cp 시간 | 데이터 | 압축됨 | 총 | 비율 |
|---|---|---|---|---|---|
| lzo | 4.571초 | 1.1G | 3억 8780만 | 4억 980만 | 2.689 |
| lzo-rle | 4.471초 | 1.1G | 388M | 4억 1천만 | 2.682 |
| lz4 | 4.467초 | 1.1G | 403.4M | 4억 2640만 | 2.582 |
| lz4hc | 14.584초 | 1.1G | 3억 6280만 | 3억 8,320만 | 2.872 |
| 842 | 22.574초 | 1.1G | 5억 3860만 | 5억 7,050만 | 1.929 |
| zstd | 7.897초 | 1.1G | 2억 8530만 | 2억 9,880만 | 3.961 |
u/VenditatioDelendaEst의 데이터:
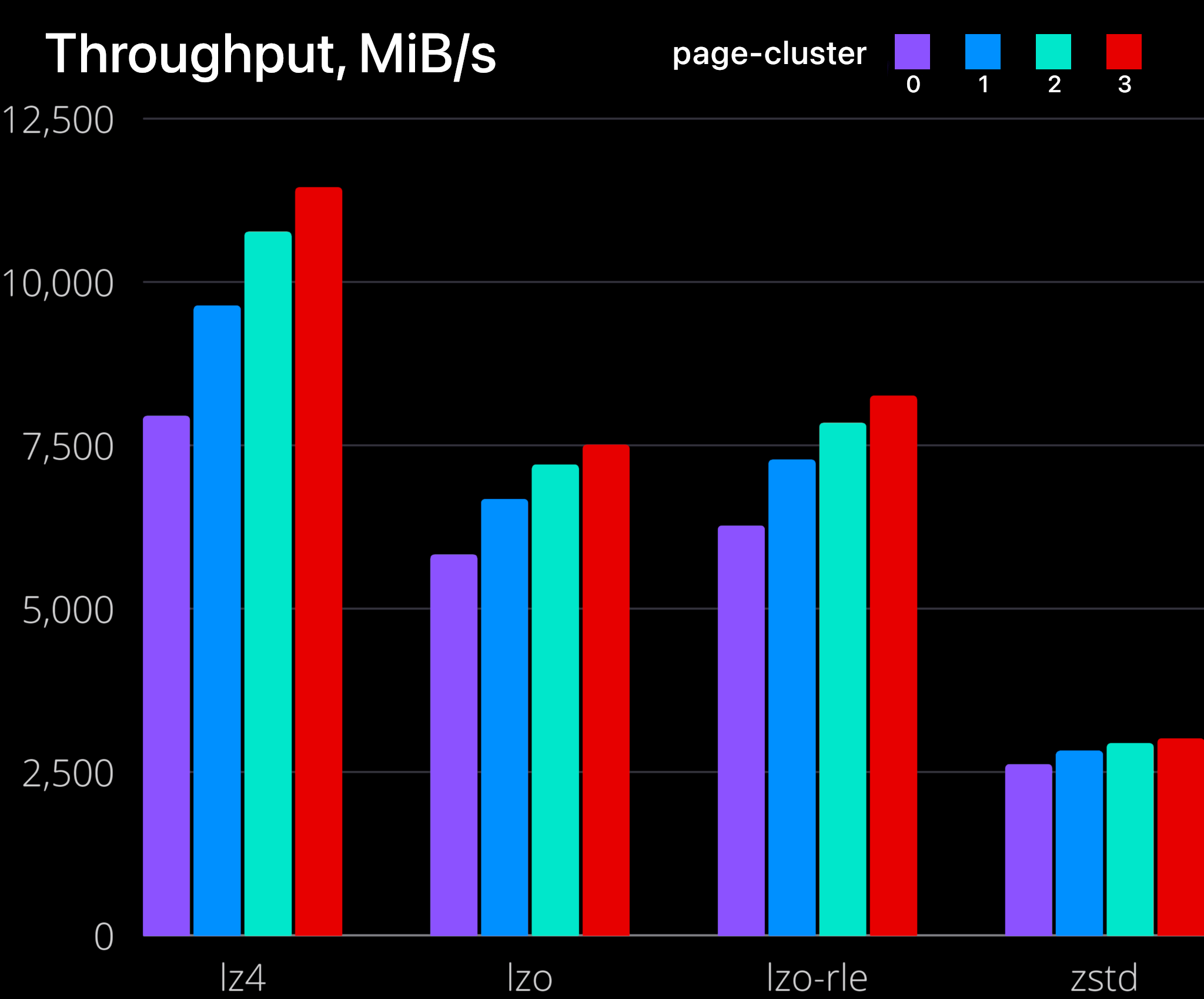
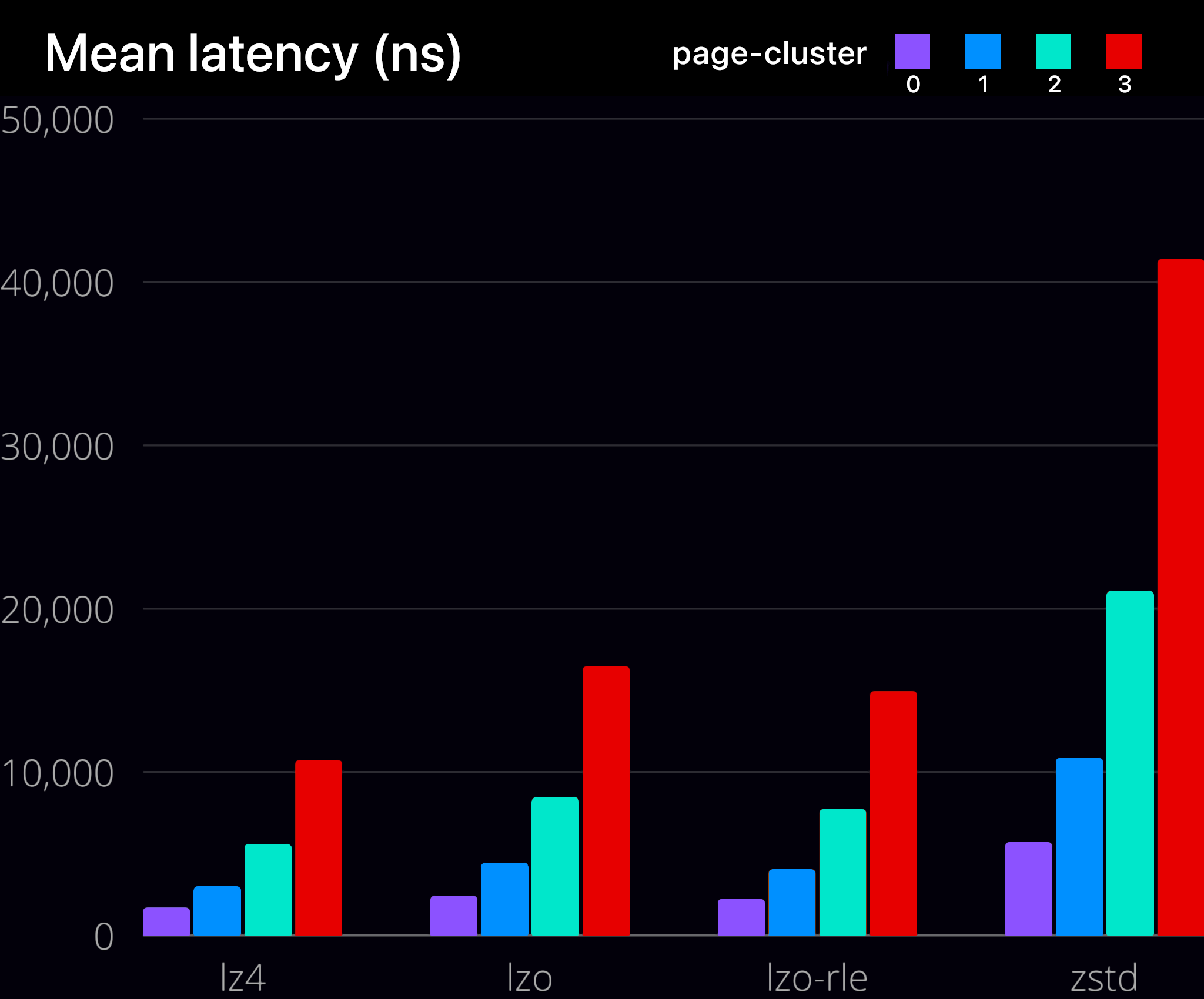
| 알고리즘 | 페이지 클러스터 | MiB/초 | 아이옵스 | 평균 지연 시간(ns) | 99% 지연 시간(ns) | 보상 비율 |
|---|---|---|---|---|---|---|
| lzo | 0 | 5821 | 1490274 | 2428 | 7456 | 2.77 |
| lzo | 1 | 6668 | 853514 | 4436 | 11968 | 2.77 |
| lzo | 2 | 7193 | 460352 | 8438 | 21120 | 2.77 |
| lzo | 3 | 7496 | 239875 | 16426 | 39168 | 2.77 |
| lzo-rle | 0 | 6264 | 1603776 | 2235 | 6304 | 2.74 |
| lzo-rle | 1 | 7270 | 930642 | 4045 | 10560 | 2.74 |
| lzo-rle | 2 | 7832 | 501248 | 7710 | 19584 | 2.74 |
| lzo-rle | 3 | 8248 | 263963 | 14897 | 37120 | 2.74 |
| lz4 | 0 | 7943 | 2033515 | 1708 | 3600 | 2.63 |
| lz4 | 1 | 9628 | 1232494 | 2990 | 6304 | 2.63 |
| lz4 | 2 | 10756 | 688430 | 5560 | 11456 | 2.63 |
| lz4 | 3 | 11434 | 365893 | 10674 | 21376 | 2.63 |
| zstd | 0 | 2612 | 668715 | 5714 | 13120 | 3.37 |
| zstd | 1 | 2816 | 360533 | 10847 | 24960 | 3.37 |
| zstd | 2 | 2931 | 187608 | 21073 | 48896 | 3.37 |
| zstd | 3 | 3005 | 96181 | 41343 | 95744 | 3.37 |
내 라즈베리파이 4, 2GB 모델의 데이터:
| 알고리즘 | 페이지 클러스터 | MiB/초 | 아이옵스 | 평균 지연 시간(ns) | 99% 지연 시간(ns) | 보상 비율 |
|---|---|---|---|---|---|---|
| lzo | 0 | 1275.19 | 326448.93 | 9965.14 | 18816.00 | 1.62 |
| lzo | 1 | 1892.08 | 242186.68 | 14178.77 | 31104.00 | 1.62 |
| lzo | 2 | 2451.65 | 156905.52 | 23083.55 | 56064.00 | 1.62 |
| lzo | 3 | 2786.33 | 89162.46 | 42224.49 | 107008.00 | 1.62 |
| lzo-rle | 0 | 1271.53 | 325511.42 | 9997.72 | 20096.00 | 1.62 |
| lzo-rle | 1 | 1842.69 | 235863.95 | 14627.23 | 34048.00 | 1.62 |
| lzo-rle | 2 | 2404.35 | 153878.65 | 23592.19 | 60160.00 | 1.62 |
| lzo-rle | 3 | 2766.61 | 88531.46 | 42579.14 | 114176.00 | 1.62 |
| lz4 | 0 | 1329.87 | 340447.83 | 9421.35 | 15936.00 | 1.59 |
| lz4 | 1 | 2004.43 | 256567.19 | 13238.78 | 25216.00 | 1.59 |
| lz4 | 2 | 2687.75 | 172015.93 | 20807.00 | 43264.00 | 1.59 |
| lz4 | 3 | 3157.29 | 101033.42 | 36901.36 | 80384.00 | 1.59 |
| zstd | 0 | 818.88 | 209633.97 | 16672.13 | 38656.00 | 1.97 |
| zstd | 1 | 1069.07 | 136840.50 | 26777.05 | 69120.00 | 1.97 |
| zstd | 2 | 1286.17 | 82314.84 | 46059.39 | 127488.00 | 1.97 |
| zstd | 3 | 1427.75 | 45688.14 | 84876.56 | 246784.00 | 1.97 |
이 표는 LZO, LZO-RLE, LZ4, ZSTD를 포함한 다양한 압축 알고리즘의 성능 지표를 보여줍니다. 이 지표에는 처리량, 압축률, 지연 시간이 포함되며, 이는 최적의 압축 알고리즘을 선택하는 데 중요한 요소입니다. 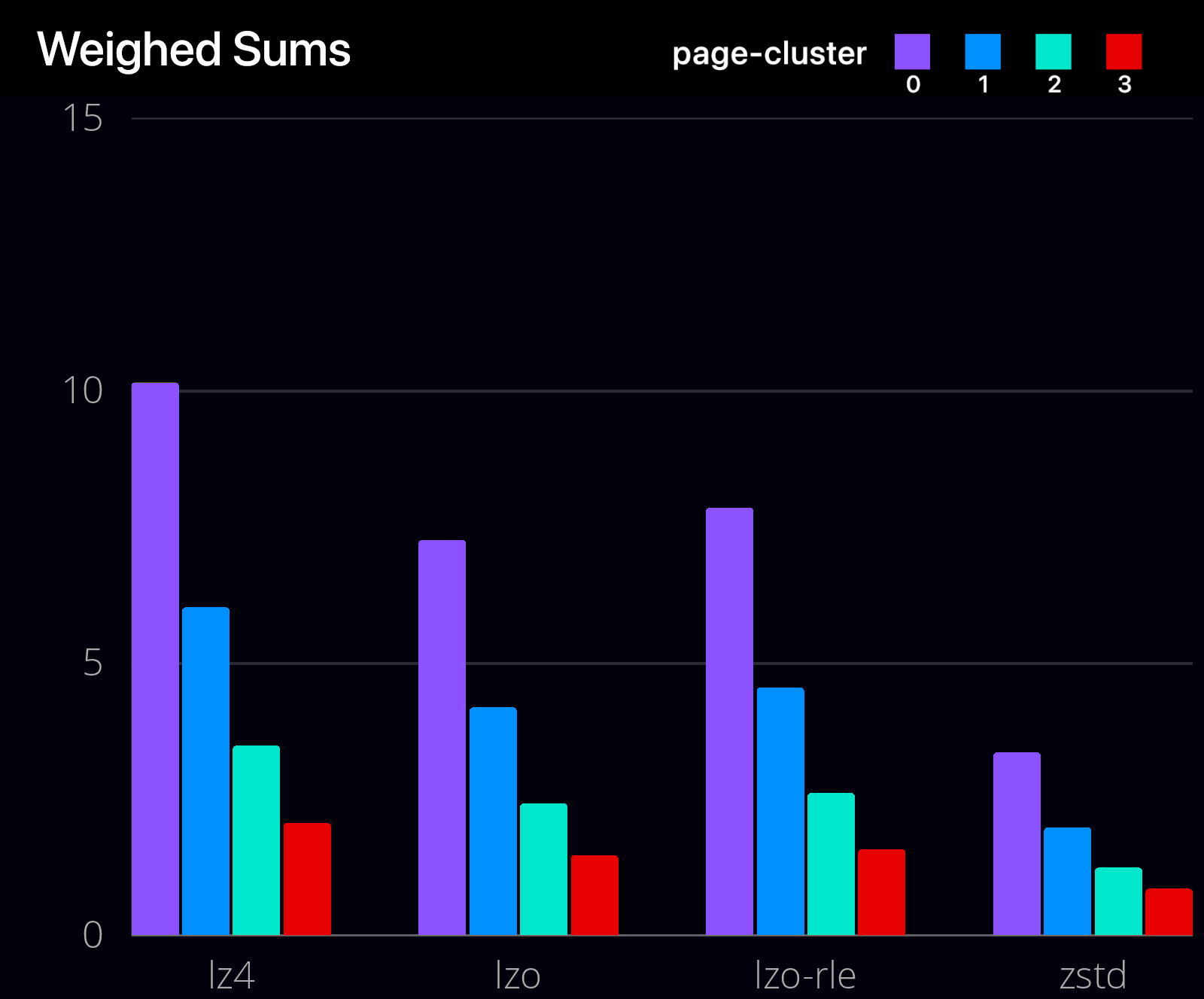
각 알고리즘과 페이지 클러스터 조합의 성능을 평가하기 위해 가중치 합을 사용했으며, 지연 시간에는 0.4, 압축률에는 0.4, 처리량에는 0.2의 가중치를 적용했습니다. 그 결과, 페이지 클러스터가 0인 LZ4가 가장 높은 가중치 합을 달성하여 이 데이터 세트에 최적의 선택임을 보여주었습니다. 전반적으로 이 평가는 데이터 저장 및 처리에 가장 적합한 압축 알고리즘을 선택하고 압축률, 처리량, 지연 시간 간의 균형을 맞추는 데 귀중한 통찰력을 제공합니다.
가중치 합계를 계산하는 데 사용되는 코드:
data = {
('lzo', 0): (5821, 2.77, 2428),
('lzo', 1): (6668, 2.77, 4436),
('lzo', 2): (7193, 2.77, 8438),
('lzo', 3): (7496, 2.77, 16426),
('lzo-rle', 0): (6264, 2.74, 2235),
('lzo-rle', 1): (7270, 2.74, 4045),
('lzo-rle', 2): (7832, 2.74, 7710),
('lzo-rle', 3): (8248, 2.74, 14897),
('lz4', 0): (7943, 2.63, 1708),
('lz4', 1): (9628, 2.63, 2990),
('lz4', 2): (10756, 2.63, 5560),
('lz4', 3): (11434, 2.63, 10674),
('zstd', 0): (2612, 3.37, 5714),
('zstd', 1): (2816, 3.37, 10847),
('zstd', 2): (2931, 3.37, 21073),
('zstd', 3): (3005, 3.37, 41343),
}
weights = {'latency': 0.4, 'ratio': 0.4, 'throughput': 0.2}
# Find the maximum value for each metric
max_throughput = max(x[0] for x in data.values())
max_ratio = max(x[1] for x in data.values())
max_latency = max(x[2] for x in data.values())
best_score = 0
best_algo = None
best_page_cluster = None
for (algo, page_cluster), (throughput, ratio, latency) in data.items():
throughput_norm = throughput / max_throughput
ratio_norm = ratio / max_ratio
latency_norm = latency / max_latency
score = weights['latency'] * (1 / latency_norm) + weights['ratio'] * ratio_norm + weights['throughput'] * throughput_norm
print(f"{algo}, pagecluster {page_cluster}: {score:.4f}")
if score > best_score:
best_score = score
best_algo = algo
best_page_cluster = page_cluster
print(f"Best algorithm: {best_algo}")
print(f"Best page cluster: {best_page_cluster}")나의 데이터:
메모리 집약적인 코드( vtm )를 컴파일하고 있습니다. 테스트는 라즈베리파이 4b, 2GB RAM에서 진행되었습니다.
| 알고 | 시간 |
|---|---|
| 엘지4 | 433.63초 |
| zstd | 459.34초 |
페이지 클러스터 값 및 대기 시간
페이지 클러스터 값은 스왑에서 한 번에 읽어들이는 페이지 수를 제어하며, 이는 페이지 캐시 미리 읽기와 유사합니다. 연속된 페이지는 가상 주소나 물리적 주소를 기준으로 하지 않고 스왑 공간을 기준으로 연속됩니다. 즉, 함께 스왑 아웃되었음을 의미합니다.
페이지 클러스터 값은 로그 값입니다. 0으로 설정하면 1페이지, 1로 설정하면 2페이지, 2로 설정하면 4페이지 등을 의미합니다. 0으로 설정하면 스왑 미리 읽기가 완전히 비활성화됩니다.
기본값은 3(한 번에 8페이지)입니다. 하지만 스왑 작업이 많은 경우 이 값을 다른 값으로 조정하면 약간의 이점을 얻을 수 있습니다. 값이 낮을수록 초기 오류 발생 시 지연 시간이 짧아지지만, 연속된 페이지 미리 읽기를 통해 발생한 후속 오류로 인해 추가 오류와 I/O 지연이 발생할 수 있습니다.
결론
Zram 성능 분석 결과, zstd 알고리즘은 허용 가능한 속도를 유지하면서도 가장 높은 압축률을 제공하는 것으로 나타났습니다. 높은 압축률 덕분에 더 많은 작업 집합을 비압축 메모리에 저장할 수 있어 스왑 필요성이 줄어들고 궁극적으로 성능이 향상됩니다.
일상적인 사용(지연 시간에 민감하지 않은 경우)의 경우, 스왑된 데이터의 대부분이 오래된 데이터(오래된 브라우저 탭)일 가능성이 높으므로 page-cluster=0 와 함께 zstd를 사용하는 것이 좋습니다. 하지만 지속적인 스왑이 필요한 시스템은 높은 처리량과 낮은 지연 시간을 제공하는 lz4 알고리즘을 사용하는 것이 좋습니다.
zstd의 압축 해제 속도가 느리고 미리 읽기를 통한 처리량 증가가 부족하다는 점에 유의해야 합니다. 따라서 zstd에는 page-cluster=0를 사용해야 합니다. 이는 ChromeOS 의 기본 설정이며 Android 에서는 표준 설정으로 보입니다 .
page-cluster 기본값은 3으로 설정되어 있으며, 이는 물리적 스왑에 더 적합합니다. 이 값은 커널이 git으로 전환된 2005년부터 사용되었으며, SSD가 널리 사용되기 이전부터 사용되었을 가능성이 있습니다. Zram을 구성할 때는 시스템 및 워크로드의 특정 요구 사항을 고려하는 것이 좋습니다.
