Red Hat OpenShift Data Foundation 은 Red Hat OpenShift 의 핵심 스토리지 구성 요소입니다 . 다양한 애플리케이션을 지원하는 통합 블록, 파일 및 객체 스토리지 기능을 제공합니다.
OpenShift Data Foundation 4.14의 새로운 흥미로운 기능 중 하나는 OpenShift Data Foundation Regional Disaster Recovery (RDR)로, Rados Block Device pools (RBD pools) 및 Ceph File System (CephFS)(volsync 복제를 통해) 풀에 대한 RDR 기능을 제공합니다. 클러스터 간에 복제된 RBD 이미지를 통해 OpenShift Data Foundation RDR은 치명적인 장애로부터 고객을 보호합니다. OpenShift Data Foundation RDR을 통해 다음과 같은 이점을 얻을 수 있습니다:
- Red Hat OpenShift 클러스터 전반에서 애플리케이션과 해당 상태 관계를 보호합니다.
- 애플리케이션과 해당 상태를 피어 클러스터로 장애 조치합니다.
- 피어 클러스터 간에 애플리케이션과 해당 상태를 다시 배치합니다.
이 문서에서는 OpenShift Data Foundation RDR 테스트 중 수집된 테스트 결과를 리소스 활용도 관점에서 요약하고, OpenShift Data Foundation RDR 환경의 규모 조정 시 모범 사례로 활용할 수 있는 권장 사항을 정의합니다. 테스트는 주로 OpenShift Data Foundation RDR 솔루션의 확장성에 중점을 두었습니다. Red Hat OpenShift 및 OpenShift Data Foundation RDR에 대한 자세한 내용과 구성 지침은 공식 OpenShift Data Foundation 재해 복구(DR) 문서 에서 확인할 수 있습니다 .
목표 요약
OpenShift Data Foundation 4.14에서는 최대 100개의 RBD 이미지가 기본 클러스터와 보조 클러스터 간에 복제되는 구성에 대한 성능 테스트를 중점적으로 진행했습니다. OpenShift Data Foundation DR 환경 계획 시 필요한 리소스 요구 사항을 예측하고 이러한 구성에 대한 모범 사례 권장 사항을 제시하는 것이 목표였습니다.
OpenShift Data Foundation DR이 활성화되면 drclusters 및 schedulinginterval을 정의하는 새로운 객체 DRPolicy가 도입됩니다. DRPolicy 내 drclusters는 OpenShift Data Foundation DR 솔루션에 포함될 클러스터를 정의하며, schedulingInterval은 클러스터 간 비동기 데이터 복제 빈도를 정의합니다.
DRPolicy 내에서 다양한 schedulinginterval을 테스트한 결과, schedulinginterval:15m이 최적의 스케줄링 간격임을 확인했습니다. 더 짧은 스케줄링 간격도 DRPolicy 생성 시 사용 가능하나, 이러한 고빈도 복제는 리소스 소모가 매우 크다는 점을 발견했습니다. 따라서 본 테스트에서는 해당 구성에 중점을 두지 않았습니다. OpenShift Data Foundation RDR 4.14에서 권장되는 schedulinginterval은 15분입니다.
확장성 관점에서, 본 문서 작성 시점 기준 100개의 RBD 이미지를 미러링하는 작업은 테스트에 사용된 schedulinginterval:15m로 처리 가능하다고 볼 수 있습니다. 향후 OpenShift Data Foundation DR 릴리스에서는 더 광범위한 테스트를 수행하고, 주 클러스터와 보조 클러스터 간에 복제되는 RBD 이미지를 100개 이상으로 확장할 계획입니다.
OpenShift Data Foundation DR 배포를 계획할 때는 클러스터의 스토리지 요구 사항과 rook-ceph-rbd-mirror 포드의 CPU/메모리 제한에 주의를 기울여야 합니다.
테스트 환경 구성
테스트에 사용된 소프트웨어:
- Red Hat OpenShift 4.14 클러스터의 일부인 OpenShift Data Foundation 4.14.
하드웨어 구성:
- Red Hat OpenShift 4.14를 베어 메탈 클러스터에 설치하고, 그 위에 Red Hat OpenShift Data Foundation 클러스터를 구성했습니다.
테스트 절차
테스트 시나리오에서는 100개의 포드가 생성되었으며, 각 포드는 하나의 지속적 볼륨 클레임(PVC)을 마운트했습니다. 테스트 중 읽기/쓰기 작업을 전송할 위치로 각 포드 내부에 마운트된 이 PVC를 사용했습니다. PVC 클레임은 기본 블록 스토리지 클래스인 ocs-storagecluster-ceph-rbd를 사용하여 생성되었습니다.
테스트 기간은 2시간이었습니다. 이 시간 동안 프라이머리 클러스터에서 광범위한 혼합 randrw(랜덤 읽기/쓰기) 작업(쓰기 70%, 읽기 30%)을 실행했으며, OpenShift Data Foundation DR이 클러스터 간 데이터 복제를 제공했습니다. 이 기간 동안 두 클러스터 모두 스토리지 공간 사용량, CPU 제한, 메모리 사용량을 모니터링했습니다. 부하를 생성하는 100개 포드의 전체 변경률은 schedulinginterval:15m 내에 약 400GB였습니다. 이는 생성/변경된 데이터 양을 파악하여 원하는 크기를 능동적으로 제안할 수 있도록 하기 위해 중요합니다.
OpenShift Data Foundation DR을 배포할 때 스토리지, CPU 및 메모리 리소스 측면에서 요구 사항을 파악하고자 했습니다. 테스트 시간을 2시간으로 설정하여 단기 테스트에서 발생할 수 있는 편향을 방지하고자 했습니다.
OpenShift Data Foundation 재해 복구는 어떻게 작동합니까?
OpenShift Data Foundation DR은 스케줄링 간격(schedulinginterval) 샘플에서 데이터를 비동기적으로(실시간 동기화가 아님) 복제합니다. 우리는 schedulinginterval:15m을 테스트했으며 스냅샷 관점에서 스토리지 요구 사항이 관찰되었습니다. 또한 OpenShift Data Foundation DR 클러스터 간 동기화 작업을 담당하는 rook-ceph-rbd-mirror 포드의 CPU 및 메모리 사용량을 모니터링했습니다.
복제는 보조 클러스터에서 “풀 모드”로 작동하며, 보조 클러스터의 rook-ceph-rbd-mirror 포드가 주 클러스터에서 데이터를 가져오는 역할을 담당합니다. OpenShift Data Foundation 스토리지 오퍼레이터는 PV(Persistent Volume)에 대한 볼륨 영구 데이터와 Kubernetes 메타데이터를 모두 동기화합니다.
현재 rook-ceph-rbd-mirror 리소스의 기본 제한은 CPU 1개와 메모리 2GB입니다. 본 테스트에서는 rook-ceph-rbd-mirror 포드의 다양한 구성을 검토하여 서로 다른 리소스 제한이 RBD 미러 성능에 도움이 되는지 비교 및 검증했습니다. 해당 결과는 문서 후반부에 제시할 예정입니다.
DRpolicy는 OpenShift Data Foundation DR 솔루션의 일부인 두 drCluster 간 비동기 정책을 정의하며, 주 클러스터와 보조 클러스터 간 데이터 복제 시 볼륨 복제에 비동기 스케줄링 간격이 사용됩니다.
특정 PVC에 대해 주 클러스터에서 볼륨 복제 객체가 생성되면, 해당 객체에 대한 OpenShift Data Foundation DR 프로세스가 시작됩니다. OpenShift Data Foundation DR 개념에 대한 자세한 내용은 OpenShift Data Foundation DR 문서에서 확인할 수 있습니다. Red Hat OpenShift 및 OpenShift Data Foundation DR의 개요는 그림 1과 같이 설명할 수 있습니다.
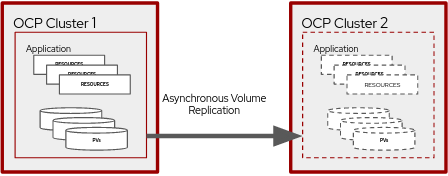
리소스 요구 사항
OpenShift Data Foundation DR 설치를 계획할 때 가장 중요한 고려 사항 중 하나는 OpenShift Data Foundation DR 설정에 필요한 요구 사항을 파악하는 것입니다. OpenShift Data Foundation DR 설정은 Red Hat OpenShift/OpenShift Data Foundation 설치를 기반으로 구축되며, 다음 섹션에서는 이러한 환경에서 OpenShift Data Foundation DR을 성공적으로 배포하는 데 필요한 리소스 요구 사항을 다룹니다. 다양한 리소스(스토리지, CPU, 메모리 등) 활용도를 설명하고 이를 효과적으로 활용하기 위한 모범 사례를 소개합니다.
저장 공간 요구 사항
일반적인 OpenShift Data Foundation DR 환경에서는 애플리케이션이 데이터를 기본 OpenShift Data Foundation 클러스터에 기록한 후, 이러한 업데이트가 주기적으로 보조 클러스터로 동기화됩니다. 주 클러스터의 경우, OpenShift Data Foundation DR이 보호되는 PVC(RBD 이미지)마다 5개의 미러 스냅샷을 생성하고 유지 관리하므로 클러스터 내 여유 공간에 미치는 영향을 고려해야 합니다. 이러한 스냅샷은 데이터 세트에 변경 사항이 있을 때마다(예: 애플리케이션이 주 클러스터에 새 데이터를 작성하는 경우) schedulinginterval 간격으로 생성됩니다.
OpenShift Data Foundation DR은 기본 클러스터에 5개의 미러 스냅샷을 보관하며, 미러 스냅샷 5개 제한에 도달하면 가장 오래된 이미지 스냅샷이 자동으로 제거됩니다. OpenShift Data Foundation DR의 경우 기본값인 5개의 미러 스냅샷을 유지하는 것이 좋습니다.
OpenShift Data Foundation DR이 비활성화되거나 해당 이미지가 제거되면 OpenShift Data Foundation DR은 자동으로 미러 스냅샷을 정리합니다.
많은 PVC에 큰 데이터 세트가 포함된 특정 풀에서 OpenShift Data Foundation DR이 활성화되면 OpenShift Data Foundation DR 미러 스냅샷 생성으로 인해 기본 Ceph 클러스터의 여유 공간에 영향을 미칠 수 있다는 점을 이해하는 것이 중요합니다.
또한 현재 기본값인 5개의 미러 스냅샷이 향후 OpenShift Data Foundation DR 릴리스에서 생성되는 미러 스냅샷의 수가 더 적어질 수 있다는 점을 지적하고 싶습니다.
기본 클러스터 스토리지 요구 사항
위에서 언급한 대로 기본 OpenShift Data Foundation DR 클러스터는 데이터 세트가 변경되는 동안과 보조 클러스터에 복제해야 할 차이점이 있는 경우 데이터 세트의 미러 스냅샷을 5개 유지합니다.
보조 클러스터 스토리지 요구 사항
기본 클러스터에서 보조 클러스터로 데이터 세트를 복제한 후 보조 클러스터는 데이터 세트의 단일 스냅샷을 생성하며 보조 클러스터의 저장 공간 요구 사항을 계산할 때 이 점도 고려해야 합니다.
위의 설명을 바탕으로 저장 공간 요구 사항을 보여주는 아래 표를 만들었습니다.
표 1: OpenShift Data Foundation DR 기본 및 보조 클러스터에 대한 스토리지 요구 사항.
| 보관 요구 사항 | 기본 클러스터 | 2차 클러스터 |
| 데이터 세트 | 5 x 데이터 세트 | 2 x 데이터 세트 |
일부에서는 기본 클러스터에 5개의 미러 스냅샷이 너무 많다고 생각할 수 있지만, 이는 데이터 안전과 지속성을 염두에 두고 선택한 것이며, 풀 매개변수 rbd_mirror_concurrent_image_syncs에 기본값을 사용하는 것이 좋습니다 .
보조 클러스터의 경우 이 요구 사항이 그다지 엄격하지 않으며 데이터 세트 위에 하나의 미러 스냅샷만 생성됩니다. 또한 적절한 모니터링을 구축하고 OpenShift Data Foundation DR과 별도로 OpenShift Data Foundation 클러스터의 여유 공간을 모니터링하는 것이 좋습니다.
일반적인 권장 사항으로, OpenShift Data Foundation DR이 활성화되고 미러 스냅샷 생성이 시작되면 기본 스토리지 시스템이 사용 가능한 최대 스토리지에 가까워져서는 안 됩니다.
특히 OpenShift Data Foundation DR이 활성화된 후에는 full_ratio, backfillfull_ratio, nearfull_ratio 매개변수 중 어떤 것도 알림을 발생시키지 않도록 해야 합니다 . Ceph 알림에 대한 자세한 내용은 Ceph 설명서 를 참조하세요 .
이러한 매개변수의 현재 값은 아래와 같습니다.
full_ratio 0.85 backfillfull_ratio 0.8 nearfull_ratio 0.7
무료 스토리지 용량 관점에서 볼 때, 고객 사이트에 OpenShift Data Foundation DR 배포를 계획할 때 위의 권장 사항을 고려해야 한다고 말할 수 있습니다.
CPU 권장 사항
OpenShift Data Foundation DR은 풀 모드에서 작동하며, 여기서 변경 사항은 보조 클러스터에서 기본 클러스터로 schedulinginterval 마다 끌어옵니다. 따라서 보조 클러스터에서 RBD 미러 포드 CPU 사용량을 모니터링하는 것이 매우 중요합니다.
OpenShift Data Foundation DR의 rbd 미러 포드에 대한 기본 CPU 제한은 1CPU이고 메모리 제한은 2GB RAM입니다.
대부분의 경우 rook-ceph-rbd-mirror 포드당 CPU 1개면 충분하지만, 보조 클러스터의 rbd-mirror 포드에 CPU 2개가 할당된 경우 기본 클러스터에서 보조 클러스터로의 데이터 동기화가 더 빨라지는 것으로 나타났습니다. rook-ceph-rbd-mirror 포드의 요청/한도를 CPU 1개에서 2개로 늘리면 동기화 속도가 약 20% 향상됩니다. 그림 2에서 이 테스트의 비교를 확인할 수 있습니다.
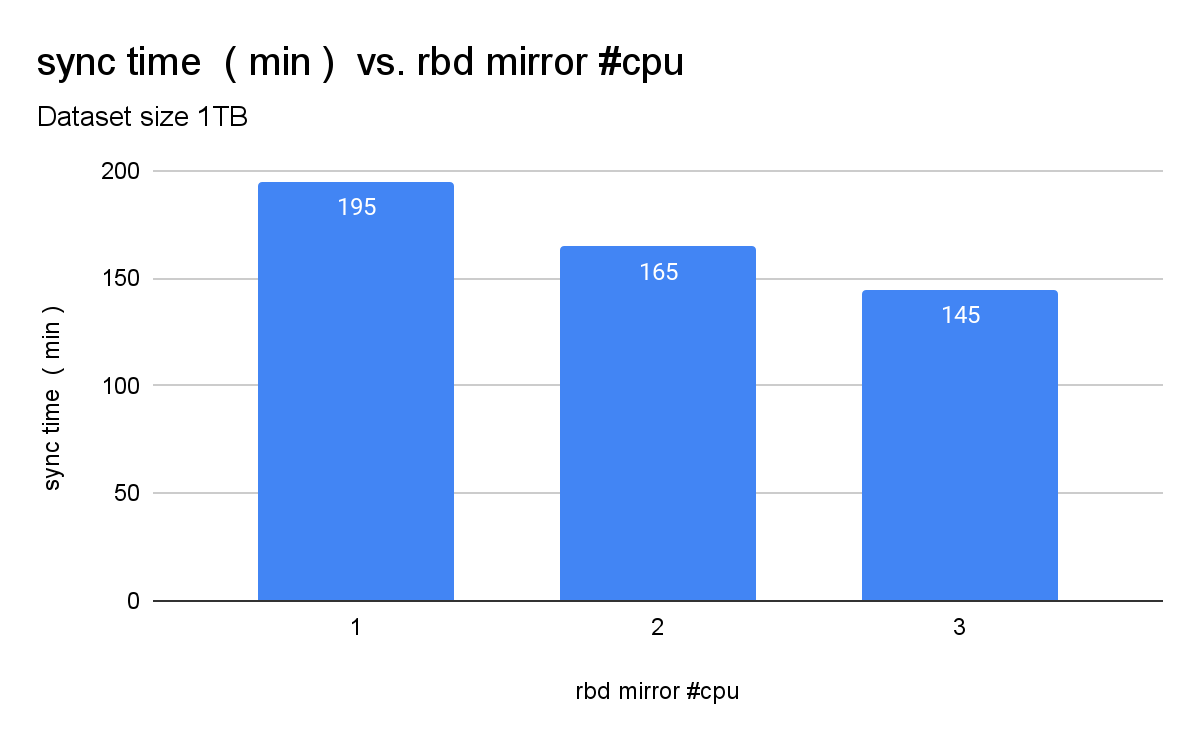
rbd-mirror 포드의 CPU 제한이 2개이므로 데이터 복제가 더 빨라지고 클러스터 용량이 허용한다면 rbd-mirror CPU 제한을 2 CPU로 늘리는 것이 좋습니다.
또한 rook-ceph-rbd-mirror 포드에 3개의 CPU 제한을 적용하여 추가 테스트를 실행했습니다. 이 테스트 사례에서 기본 클러스터와 보조 클러스터 간의 데이터 동기화가 더 빠른 것을 확인했습니다. rook-ceph-rbd-mirror 포드에 권장되는 CPU 제한인 2개의 CPU가 부족하고 여유 리소스가 충분한 경우, rook-ceph-rbd-mirror 포드에 3개의 CPU 제한을 할당하는 것이 유용할 수 있습니다. 테스트 결과, rook-ceph-rbd-mirror 포드 제한을 3개 이상으로 늘려도 동기화 시간이 선형적으로 단축되지 않았습니다.
미러 포드의 CPU 제한을 1에서 2로 늘리면 rook-ceph-rbd-mirror 포드의 CPU 제한을 1개로 늘릴 때와 비교했을 때 동기화 시간이 약 20% 빨라지고 , rook-ceph-rbd-mirror 포드의 CPU 제한을 3개로 늘리면 동기화 시간이 추가로 10% 단축됩니다.
위 데이터를 기반으로 볼 때, rook-ceph-rbd-mirror 포드의 CPU 제한을 1 CPU에서 2 CPU로 변경하면 동기화 시간이 단축되고, 사용량이 많은 환경에서는 rook-ceph-rbd-mirror 포드의 CPU 제한을 늘리기 위해 이 옵션을 고려하는 것이 좋습니다 .
테스트 결과, rook-ceph-rbd-mirror Pod의 메모리 제한 문제는 발견되지 않았습니다. 현재 기본 제한인 2GiB는 테스트한 워크로드에 충분한 것으로 나타났으며, 이 제한을 유지할 것을 권장합니다.
결론
- 기본 및 보조 클러스터의 저장 공간을 적절히 계획해야 합니다. 기본 클러스터는 현재 OpenShift Data Foundation DR이 생성하는 5개의 미러 스냅샷으로 인해 저장 공간 요구 사항이 더 큰 영향을 받고 있습니다. OpenShift Data Foundation DR이 활성화되면 이 작업으로 인해
full_ratio,backfillfull_ratio,nearfull_ratioCeph 알림에서 오류가 보고되지 않으므로 이에 따라 계획을 수립해야 합니다. - 큰 데이터 세트를 높은 변경률로 복제하는 경우
schedulinginterval의 기본값인 15m보다 짧은 값을 사용하기로 결정하면 기본 클러스터의 저장 공간과 관련된 문제가 발생할 수 있다는 점을 이해하는 것이 중요합니다. rook-ceph-rbd-mirror포드의 CPU 한도를 2로 늘리면 이점이 있습니다. OpenShift Data Foundation DR에는 여러 가지 구성이 있을 수 있습니다. 예를 들어, 보조 클러스터가 일부 PVC의 기본 클러스터 역할을 하는 경우 전체 OpenShift Data Foundation DR 설정에서 rbd-mirror 포드의 CPU 한도를 2로 정의하는 것이 좋습니다.- 테스트 중에는 rbd-mirror 포드의 현재 메모리 한도인 2GB가 충분했습니다. Prometheus와 같은 Red Hat OpenShift 통합 도구나 기타 맞춤형 관측 도구 를 사용하여 이러한 테스트 사례를 모니터링할 수 있었습니다. 메모리 사용량을 모니터링하고 필요에 따라 요청/한도를 조정하는 것이 좋습니다.
- 클러스터에서 사용 가능한 OSD가 많고 네트워크 지연 시간이 낮을수록 OpenShift Data Foundation의 성능이 향상됩니다.


