Ceph Blog(https://ceph.io/en/news/blog/)를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://ceph.io/en/news/blog/2025/nvme-gateway-perf-mb/
NVMe over TCP를 통한 확장 가능한 성능¶
TCP를 통한 NVMe 성능 살펴보기: 데이터 스토리지 혁신¶
데이터 중심 세계에서 더 빠르고 효율적인 스토리지 솔루션에 대한 수요가 급증하고 있습니다. 기업, 클라우드 제공업체, 데이터 센터가 끊임없이 증가하는 데이터 볼륨을 처리해야 함에 따라 스토리지 성능은 중요한 요소가 되고 있습니다. 이 분야에서 가장 유망한 혁신 중 하나는 NVMe over TCP(NVMe/TCP, 일명 NVMeoF)로, 기존 TCP/IP 네트워크를 통해 고성능 NVMe(Non-Volatile Memory Express) 스토리지 장치를 구축할 수 있도록 지원합니다. 이 블로그에서는 Ceph와 최신 블록 프로토콜인 NVMe over TCP의 성능, 그 이점, 과제, 그리고 이 기술의 전망을 심층적으로 살펴봅니다. 또한, NVMe SSD로 구성된 노드와 성능 프로필을 살펴보고 고성능에 최적화된 설계를 자세히 설명합니다.
NVMe 및 TCP 이해: 간단한 개요¶
성능에 대한 세부 사항을 살펴보기 전에, 관련된 핵심 기술을 명확히 알아보겠습니다.
- NVMe(Non-Volatile Memory Express)는 고속 PCIe(Peripheral Component Interconnect Express) 버스를 활용하여 저장 매체에 대한 빠른 데이터 액세스를 제공하도록 설계된 프로토콜입니다. NVMe는 SATA 및 SAS와 같은 기존 스토리지에 비해 지연 시간을 줄이고 처리량을 향상시키며 전반적인 스토리지 성능을 향상시키는 동시에, TB당 $(달러) 기준으로 최대 소폭 상승하는 가격대를 유지합니다. 성능, 확장성, 처리량 측면에서 NVMe 드라이브는 이 분야에서 비용 대비 성능이 뛰어난 제품입니다.
- TCP/IP(Transmission Control Protocol/Internet Protocol) 는 현대 네트워킹의 핵심 요소 중 하나입니다. 네트워크 간 데이터 전송을 보장하는 안정적인 연결 지향 프로토콜입니다. TCP는 견고성과 광범위한 사용으로 잘 알려져 있어, NVMe 장치를 장거리 및 클라우드 환경에서 연결하는 데 적합한 옵션입니다.
Ceph는 NVMe over TCP를 시장에 출시하여 Fibre Channel, InfiniBand 또는 RDMA와 같은 특수 하드웨어가 필요 없이 네트워크 스토리지 솔루션에 NVMe 속도와 저지연 액세스를 제공합니다.
NVMe over TCP 성능: 기대할 수 있는 것¶
NVMe over TCP의 성능은 기반 네트워크 인프라, 스토리지 아키텍처 및 설계, 그리고 처리되는 워크로드에 따라 크게 달라집니다. 하지만 몇 가지 주요 요소를 염두에 두어야 합니다.
- 지연 시간 및 처리량 : NVMe는 지연 시간을 최소화하도록 설계되었으며, 이러한 이점은 NVMe over TCP에도 적용됩니다. TCP 자체는 연결 관리 기능으로 인해 약간의 지연 시간을 발생시키지만(RDMA와 같은 지연 시간이 짧은 프로토콜과 비교했을 때), NVMe over TCP는 기존 네트워크 스토리지 프로토콜보다 훨씬 우수한 지연 시간을 제공합니다. Ceph와 관련하여 주목할 점은 이 글에서 확인할 수 있듯이 규모에 따라 지연 시간과 처리량 사이에 명확한 상충 관계가 있다는 것입니다. 정의된 아키텍처의 성능 한계에 도달하면 Ceph는 불안정해지거나 실패하지 않고, 처리량 증가에 대한 수요를 충족할 때 지연 시간이 증가하는 것을 볼 수 있습니다. 특정 워크로드에 대한 IOPS와 지연 시간을 설계할 때 이 점을 명심하는 것이 매우 중요합니다.
- 네트워크 혼잡 및 패킷 손실 : TCP는 내장된 오류 정정 및 재전송 메커니즘 덕분에 네트워크 혼잡 및 패킷 손실 시에도 안정적인 성능을 제공하는 것으로 알려져 있습니다. 그러나 이러한 기능은 특히 트래픽이 많거나 네트워크 연결이 불안정한 환경에서 성능 병목 현상을 유발할 수 있습니다. 예를 들어, 네트워크 혼잡이 발생하면 TCP의 흐름 제어 메커니즘이 데이터 무결성을 보장하기 위해 성능을 제한할 수 있습니다. 이러한 문제를 해결하기 위해 기업은 네트워크 매개변수를 미세 조정하고 원활한 데이터 전송을 보장하기 위해 서비스 품질(QoS) 및 서비스 등급(CoS) 메커니즘을 구축하는 경우가 많습니다.
- CPU 오버헤드 : NVMe over TCP는 특수 하드웨어의 필요성을 없애지만, TCP/IP 스택에서 요구하는 프로토콜 처리로 인해 CPU 오버헤드가 발생할 수 있습니다. NVMe/TCP는 스토리지 워크로드 처리가 이루어지는 CPU에서 더 많은 부하를 발생시킵니다. 그러나 워크로드 요구량 증가에 따라 CPU 코어 사용량을 확장하면 성능상의 이점을 얻을 수 있으며, 이를 통해 지연 시간을 줄이고 처리량을 향상시킬 수 있습니다.
- 최적화 및 튜닝 : NVMe over TCP에서 최상의 성능을 얻으려면 네트워크 관리자가 TCP 윈도우 크기, 버퍼 크기, 혼잡 제어 설정 등 여러 매개변수를 미세 조정해야 하는 경우가 많습니다. TCP 오프로드 및 TCP/UDP 기반 혼잡 제어와 같은 최적화를 통해 NVMe over TCP의 성능을 향상시켜 까다로운 워크로드의 요구 사항을 더욱 효과적으로 충족할 수 있습니다. Ceph의 경우, 하드웨어 플랫폼에 맞춰 크기를 조정하면 추가 비용이나 하드웨어 복잡성 없이 성능을 극대화할 수 있는 소프트웨어 매개변수를 심층적으로 살펴볼 수 있습니다.
정의¶
Ceph 세계에서 몇 가지 중요한 용어를 정의하여 성능과 확장성에 있어 어떤 매개변수가 영향을 미치는지 알아보겠습니다.
OSD (Object Storage Daemon)는 Ceph 소프트웨어 정의 스토리지 시스템을 위한 객체 스토리지 데몬입니다. 물리적 스토리지 드라이브의 데이터를 이중화하여 관리하고 네트워크를 통해 해당 데이터에 대한 액세스를 제공합니다. 이 글에서는 OSD를 특정 물리적 장치의 디스크 I/O를 관리하는 소프트웨어 서비스라고 정의할 수 있습니다.
Reactor/Reactor Core : 소프트웨어 개발에서 NVMe/TCP에 대한 IO 요청을 처리하는 단일 스레드를 실행하는 이벤트 루프로 구성된 이벤트 처리 모델입니다. 기본적으로 4개의 Reactor Core 스레드로 시작하지만, 이 모델은 소프트웨어 매개변수를 통해 조정할 수 있습니다.
BDevs_per_cluster : BDev는 Block Device의 약자로, NVMe 게이트웨이가 Ceph RBD 이미지와 통신하는 데 사용되는 드라이버입니다. 이는 기본적으로 NVMe/TCP 게이트웨이가 librbd 클라이언트( bdevs_per_cluster=32) 또는 기본 볼륨에 연결하는 스토리지 클라이언트당 단일 클러스터 컨텍스트에서 32개의 BDev를 활용하기 때문에 중요합니다. 이 조정 가능한 매개변수는 NVMe 볼륨과 librbd 클라이언트 간의 컨텍스트를 1:1로 확장할 수 있도록 조정하여 더 많은 컴퓨팅 리소스를 희생하더라도 주어진 볼륨의 성능을 극대화할 수 있는 확실한 경로를 제공합니다.
성능¶
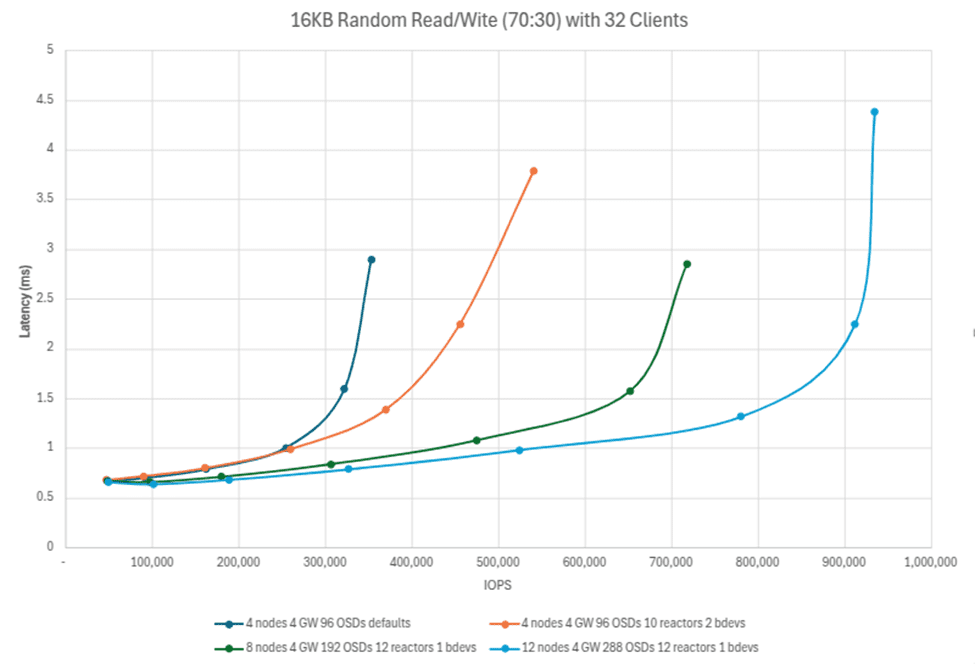
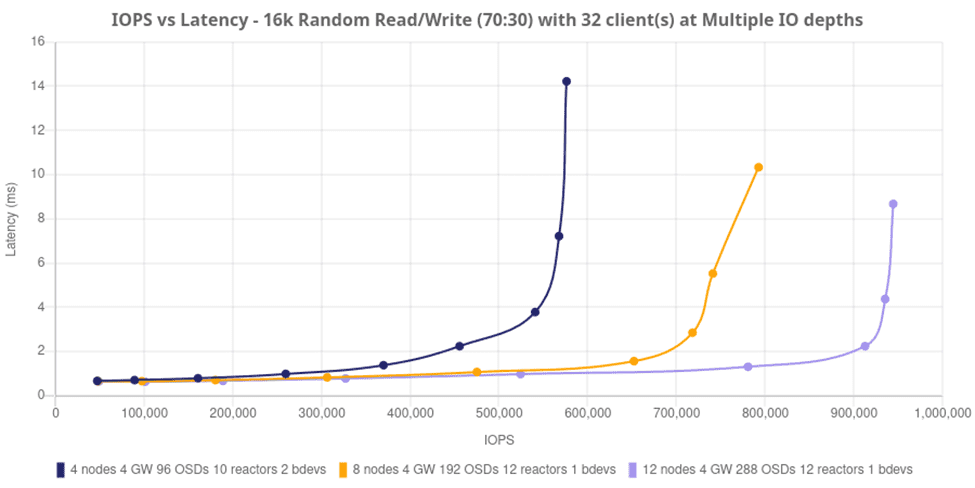
강력하게 시작하여 아래에서 Ceph 클러스터에 드라이브(OSD)와 노드를 추가하면 전반적으로 IO 성능이 어떻게 향상되는지 살펴봅니다. 노드당 24개 드라이브가 있는 4노드 Ceph 클러스터는 32개 FIO 클라이언트와 함께 16k 블록 크기를 사용하여 70:30 읽기/쓰기 프로필로 450,000 IOPS 이상을 제공할 수 있습니다. 이는 노드당 평균 100K IOPS 이상입니다! 이러한 추세는 노드와 드라이브가 추가됨에 따라 선형적으로 확장되어 12개 노드, 288개 OSD 클러스터로 거의 1,000,000 IOPS의 최고 성능을 보여줍니다. 주목할 점은 네임스페이스당 12개의 리액터와 1개의 librbd 클라이언트로 더 높은 수치가 표시된다는 것입니다( bdevs_per_cluster=1). 이는 librbd 클라이언트를 추가하면 기본 RBD 이미지와 매핑된 NVMe 네임스페이스를 제공하는 OSD에 더 많은 처리량이 제공되는 방식을 보여줍니다.
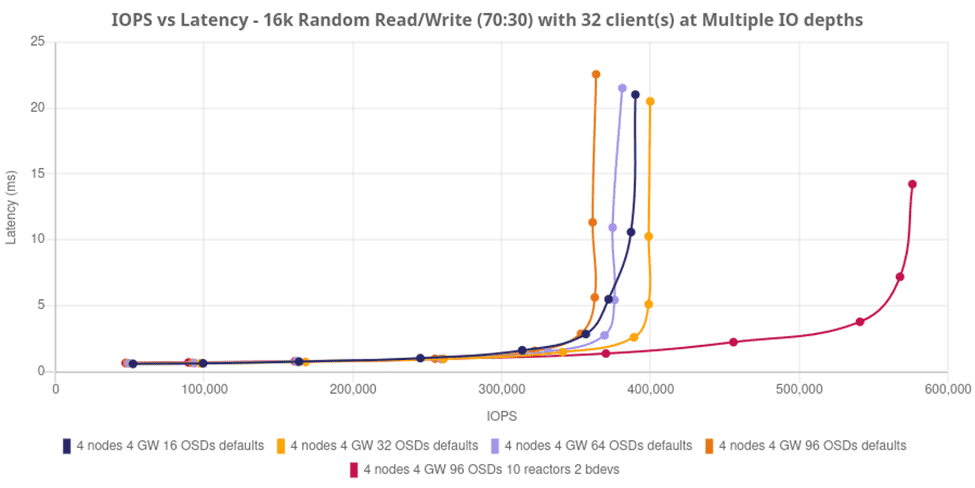
아래 테스트는 기본 하드웨어에 맞춰 환경을 조정함으로써 소프트웨어 정의 스토리지의 엄청난 성능 향상을 어떻게 보여주는지 보여줍니다. 간단한 4노드 클러스터로 시작하여 16, 32, 64, 96개의 OSD를 확장 지점으로 설정했습니다. 이 테스트에서 Ceph Object Storage Daemon은 물리적 NVMe 드라이브에 1:1로 직접 매핑되었습니다.
드라이브와 노드를 추가하는 것만으로는 성능이 약간만 향상되는 것처럼 보일 수 있지만, 소프트웨어 정의 스토리지를 사용하면 서버 활용도와 스토리지 성능 간에 항상 상충 관계가 존재하며, 이 경우에는 오히려 더 나은 결과를 가져옵니다. 동일한 클러스터의 기본 리액터 코어를 4개에서 10개로 늘리고(따라서 CPU 사이클 소모량이 증가함), librbd 클라이언트를 추가하여 소프트웨어 처리량을 높이도록 “bdevs_per_cluster“를 구성하면 성능이 거의 두 배로 향상됩니다. 이 모든 것은 기본 하드웨어에 맞춰 환경을 조정하고 Ceph가 이러한 처리 능력을 활용할 수 있도록 활성화하기만 하면 됩니다.
아래 차트는 튜닝된 4노드, 8노드, 12노드 구성의 세 가지 “티셔츠” 크기 구성과 비교를 위해 기본값을 활성화한 4노드 클러스터에서 제공되는 IOPS를 보여줍니다. 2ms 미만의 지연 시간 워크로드에서 Ceph는 선형적으로 확장되며 안정적이고 예측 가능한 방식으로 확장됨을 다시 한번 확인할 수 있습니다. 참고: I/O가 혼잡해지면 특정 시점에 워크로드는 여전히 서비스 가능하지만 지연 응답 시간이 길어집니다. Ceph는 필요한 읽기 및 쓰기를 계속 수행하며, 기존 플랫폼 설계 경계가 포화 상태가 되면 정체됩니다.
TCP를 통한 NVMe의 미래¶
스토리지 요구가 지속적으로 발전함에 따라, NVMe over TCP는 고성능 스토리지 환경의 핵심 요소로 자리매김할 것입니다. 이더넷 속도, TCP 최적화 및 네트워크 인프라의 지속적인 발전과 함께, NVMe over TCP는 엔터프라이즈 데이터 센터에서 엣지 컴퓨팅 환경에 이르기까지 다양한 애플리케이션에 매력적인 이점을 지속적으로 제공할 것입니다.
Ceph는 고성능, 확장형 NVMe 스토리지 플랫폼을 구현할 뿐만 아니라 사용자가 제어하는 소프트웨어 향상 및 구성을 통해 플랫폼의 성능을 향상시킴으로써 NVMe over TCP를 위한 소프트웨어 정의 스토리지 분야에서 최고의 성능을 발휘할 수 있는 위치에 있습니다.
결론¶
Ceph의 NVMe over TCP Target은 고성능 스토리지 네트워크를 위한 강력하고 확장 가능하며 비용 효율적인 솔루션을 제공합니다.
저자는 이 게시물을 작성하는 데 시간을 할애하여 커뮤니티를 지원해 준 IBM에 감사드리고 싶습니다.
