Ceph Blog(https://ceph.io/en/news/blog/)를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://ceph.io/en/news/blog/2025/stretch-cluuuuuuuuusters-part3/
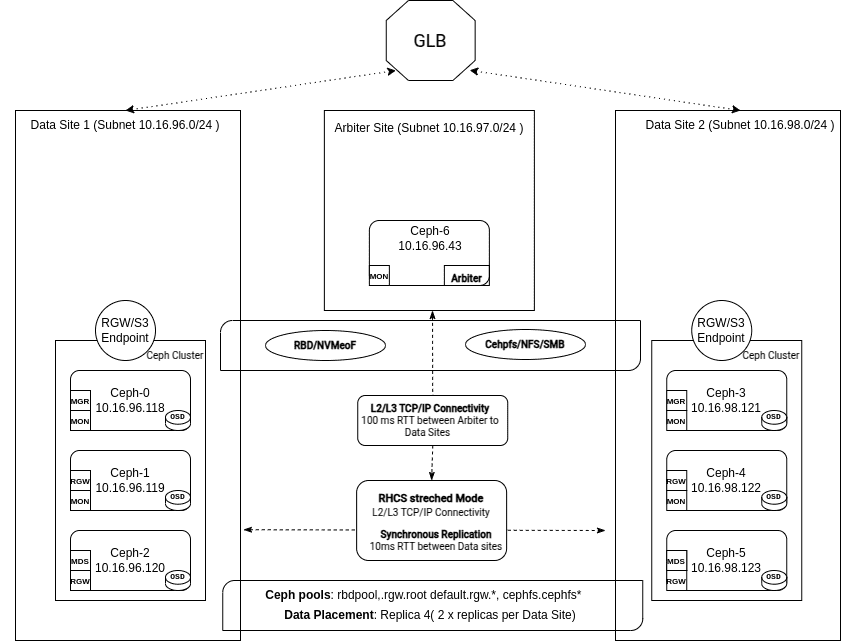
2개 사이트 스트레치 클러스터: 실패 처리¶
2부 에서는 사용자 지정 서비스 정의 파일, CRUSH 규칙 및 서비스 배치를 사용하여 타이브레이커 사이트와 모니터가 있는 2개 사이트 Ceph 클러스터의 실제 배포를 살펴보았습니다.
이 마지막 부분에서는 전체 데이터 센터에 장애가 발생할 때 어떤 일이 발생하는지 살펴보며 해당 구성을 테스트해보겠습니다.
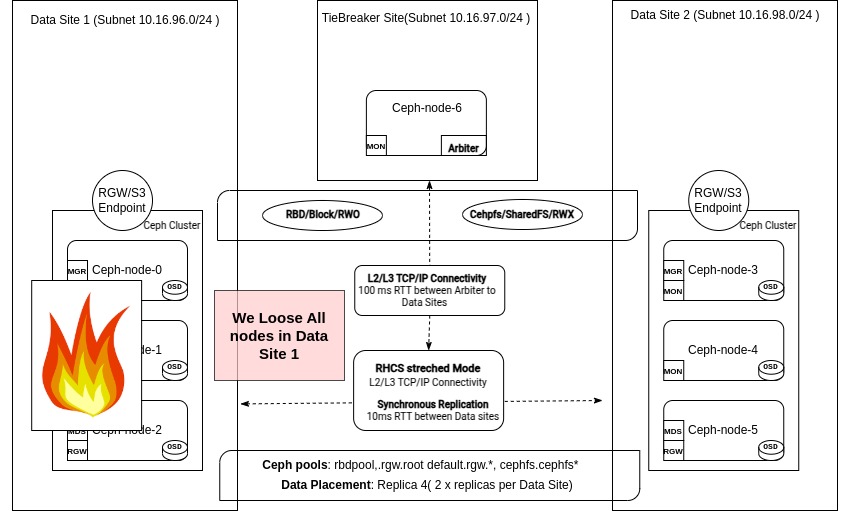
소개¶
두 사이트로 구성된 스트레치 클러스터 설계의 핵심 목표는 한 데이터 센터가 오프라인 상태가 되더라도 애플리케이션이 완벽하게 작동하도록 보장하는 것입니다. 동기식 복제를 통해 클러스터는 클라이언트 요청을 투명하게 처리하여 복구 지점 목표(RPO)를 0으로 유지하고 사이트 전체에 장애가 발생하더라도 데이터 손실을 방지할 수 있습니다.
이 시리즈의 세 번째이자 마지막 게시물에서는 Ceph가 장애가 발생한 데이터 센터를 자동으로 감지하고 격리하는 방법을 살펴보겠습니다. 클러스터는 ‘스트레치 저하 모드’ 로 전환되고 , 타이브레이커 모니터는 쿼럼을 확보합니다. 이 시간 동안 복제 제약 조건은 정상적으로 작동하는 사이트에서 서비스를 계속 사용할 수 있도록 일시적으로 조정됩니다.
오프라인 데이터 센터가 복구되면 클러스터가 어떻게 완벽한 스트레치 구성을 원활하게 복구하고, 수동 개입 없이 완전한 중복성 및 동기화 작업을 복원하는지 보여드리겠습니다. 최종 사용자와 스토리지 관리자는 이 프로세스 전반에 걸쳐 최소한의 중단과 데이터 손실을 경험하게 됩니다.
데이터 센터 전체를 잃었어요!¶
클러스터는 예상대로 작동 중이며, 모니터는 쿼럼 상태를 유지하고 있습니다. PG의 실행 세트에는 각 사이트에서 두 개씩 총 네 개의 OSD가 포함됩니다. 풀은 복제 규칙(size=4, min_size=2)으로 구성되었습니다.
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_OK
services:
mon: 5 daemons, quorum ceph-node-00,ceph-node-06,ceph-node-04,ceph-node-03,ceph-node-01 (age 43h)
mgr: ceph-node-01.osdxwj(active, since 10d), standbys: ceph-node-04.vtmzkz
osd: 12 osds: 12 up (since 10d), 12 in (since 2w)
data:
pools: 2 pools, 33 pgs
objects: 23 objects, 42 MiB
usage: 1.4 GiB used, 599 GiB / 600 GiB avail
pgs: 33 active+clean
# ceph quorum_status --format json-pretty | jq .quorum_names
[
"ceph-node-00",
"ceph-node-06",
"ceph-node-04",
"ceph-node-03",
"ceph-node-01"
]
# ceph pg map 2.1
osdmap e264 pg 2.1 (2.1) -> up [1,3,9,11] acting [1,3,9,11]
# ceph osd pool ls detail | tail -2
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
장애 발생 시 다양한 단계를 설명하기 위해 각 단계에 대한 다이어그램을 표시합니다.
이 시점에서 예상치 못한 일이 발생하고 DC1의 모든 노드에 대한 액세스 권한을 잃게 됩니다.
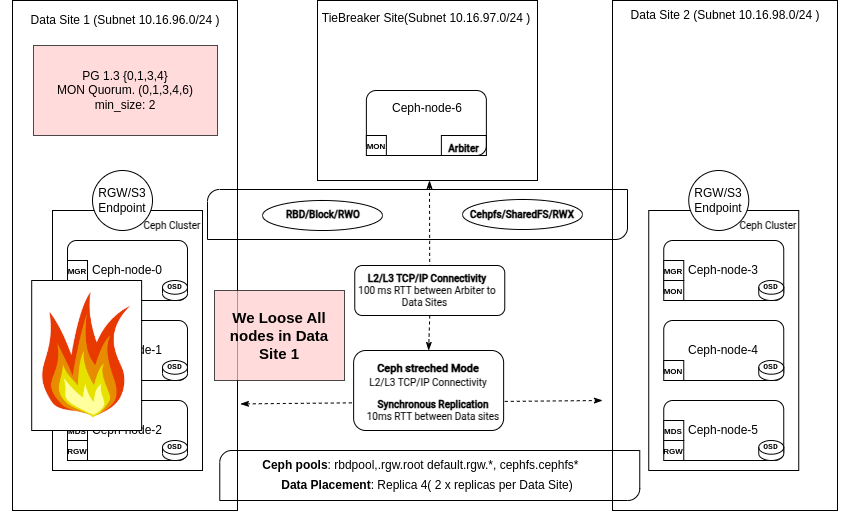
다음은 남아 있는 사이트 중 하나의 모니터 로그에서 발췌한 내용입니다. 모니터는 DC1은 down으로 간주되어 정족수에서 제거됩니다.
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : [WRN] MON_DOWN: 2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03 2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-00 (rank 0) addr [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] is down (out of quorum) 2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-01 (rank 4) addr [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] is down (out of quorum)
선거를 앞둔 DC2의 ceph-node-03 모니터는 모니터 선거를 요구하고 자신을 제안하며 새로운 리더로 승인되었습니다.
2025-02-18T14:14:33.087+0000 7f0548201640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 calling monitor election 2025-02-18T14:14:33.087+0000 7f0548201640 1 paxos.3).electionLogic(141) init, last seen epoch 141, mid-election, bumping 2025-02-18T14:14:38.098+0000 7f054aa06640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 is new leader, mons ceph-node-06,ceph-node-04,ceph-node-03 in quorum (ranks 1,2,3)
각 Ceph OSD는 6초 미만의 무작위 간격으로 다른 OSD에 하트비트를 전송합니다. 피어 OSD가 20초의 유예 기간 내에 하트비트를 전송하지 않으면, 확인 중인 OSD는 해당 피어 OSD가 down된 것으로 간주하고 이를 모니터에 보고합니다. 그러면 모니터는 클러스터 맵을 업데이트합니다.
기본적으로 서로 다른 호스트에 있는 두 OSD는 다른 OSD의 작동이 중단되었음을 모니터에 보고해야 모니터가 장애를 인식합니다. 이를 통해 오경보, 플래핑, 그리고 연쇄적인 문제 발생을 방지할 수 있습니다. 그러나 모든 보고 OSD는 다른 OSD와의 연결에 영향을 미치는 스위치가 오작동하는 랙에 호스팅될 수 있습니다. 오경보를 방지하기 위해 보고 피어를 문제가 발생할 가능성이 있는 하위 클러스터 로 간주합니다 .
Monitors OSD Reporter 하위 트리 수준에서는 CRUSH 맵에서 공통 조상 유형을 기준으로 피어를 하위 클러스터 로 그룹화합니다 . 기본적으로 OSD 다운을 선언하려면 서로 다른 하위 트리에 있는 두 개의 Report가 필요합니다.
2025-02-18T14:14:29.233+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 prepare_failure osd.0 [v2:192.168.122.12:6804/636515504,v1:192.168.122.12:6805/636515504] from osd.10 is reporting failure:1 2025-02-18T14:14:29.235+0000 7f0548201640 0 log_channel(cluster) log [DBG] : osd.0 reported failed by osd.10 2025-02-18T14:14:31.792+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 we have enough reporters to mark osd.0 down 2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 2 osds down (OSD_DOWN) 2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 host (2 osds) down (OSD_HOST_DOWN)
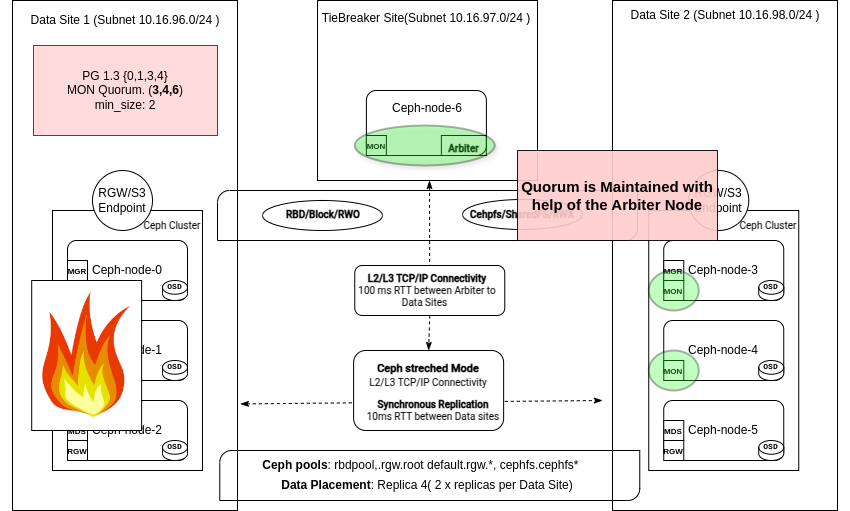
ceph status 명령어의 출력에서, 쿼럼이 ceph-node-06, ceph-node-04 및 ceph-node-03에 의해 유지되고 있음을 확인할 수 있습니다:
# ceph -s | grep mon
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
mon: 5 daemons, quorum ceph-node-06,ceph-node-04,ceph-node-03 (age 10s), out of quorum: ceph-node-00, ceph-node-01
ceph osd tree 명령을 통해 DC1의 OSD가 down으로 표시되어 있는 것을 볼 수 있습니다 .
# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.58557 root default -3 0.29279 datacenter DC1 -2 0.09760 host ceph-node-00 0 hdd 0.04880 osd.0 down 1.00000 1.00000 1 hdd 0.04880 osd.1 down 1.00000 1.00000 -4 0.09760 host ceph-node-01 3 hdd 0.04880 osd.3 down 1.00000 1.00000 7 hdd 0.04880 osd.7 down 1.00000 1.00000 -5 0.09760 host ceph-node-02 2 hdd 0.04880 osd.2 down 1.00000 1.00000 5 hdd 0.04880 osd.5 down 1.00000 1.00000 -7 0.29279 datacenter DC2 -6 0.09760 host ceph-node-03 4 hdd 0.04880 osd.4 up 1.00000 1.00000 6 hdd 0.04880 osd.6 up 1.00000 1.00000 -8 0.09760 host ceph-node-04 10 hdd 0.04880 osd.10 up 1.00000 1.00000 11 hdd 0.04880 osd.11 up 1.00000 1.00000 -9 0.09760 host ceph-node-05 8 hdd 0.04880 osd.8 up 1.00000 1.00000 9 hdd 0.04880 osd.9 up 1.00000 1.00000
Ceph는 전체 사이트에 장애가 발생하면 OSD_DATACENTER_DOWN 상태 경고를 발생시킵니다. 이는 datacenter네트워크 중단, 정전 또는 기타 문제로 인해 CRUSH 하나를 사용할 수 없음을 나타냅니다. 모니터 로그에서:
2025-02-18T14:14:32.910+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 datacenter (6 osds) down (OSD_DATACENTER_DOWN)
ceph status명령에서도 같은 내용을 볼 수 있습니다 .
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_WARN
3 hosts fail cephadm check
We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
1 datacenter (6 osds) down
6 osds down
3 hosts (6 osds) down
Degraded data redundancy: 46/92 objects degraded (50.000%), 18 pgs degraded, 33 pgs undersized
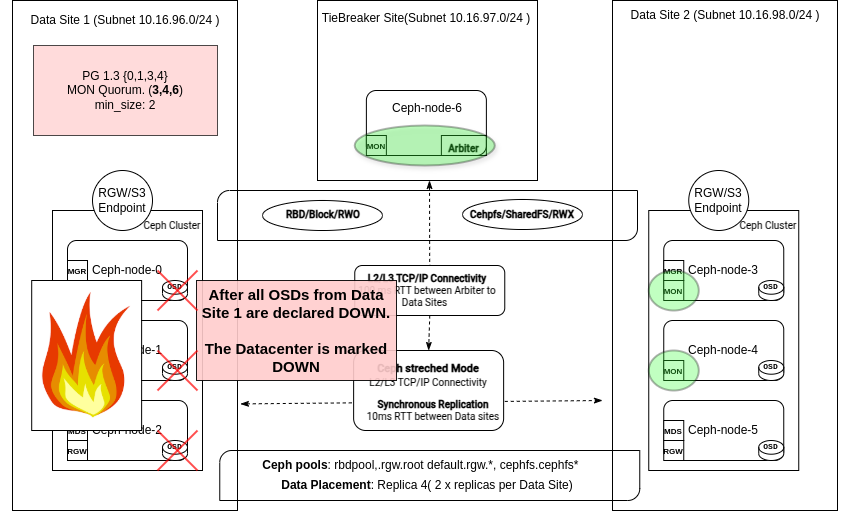
두 사이트로 구성된 확장 시나리오에서 전체 데이터 센터에 장애가 발생하면 Ceph는 확장 성능 저하 모드로 전환됩니다. 다음과 같은 Monitor 로그 항목이 표시됩니다.
2025-02-18T14:14:32.992+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : Health check failed: We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer (DEGRADED_STRETCH_MODE)
스트레치 저하 모드¶
스트레치 저하 모드는 자체 관리됩니다. 모니터에서 CRUSH 데이터센터 전체에 접근할 수 없음을 확인하면 활성화됩니다. 관리자는 사이트나 데이터센터를 수동으로 승격 또는 강등할 필요가 없습니다. Ceph의 오케스트레이터는 OSD 맵과 PG 상태를 자동으로 업데이트합니다. 클러스터가 저하 스트레치 모드 로 전환되면 작업이 자동으로 진행됩니다.
스트레치 저하 모드는 Ceph가 더 이상 실패한 데이터 센터의 오프라인 OSD로부터 확인을 요구하지 않고도 쓰기를 완료하거나 배치 그룹(PG)을 활성 상태로 전환할 수 있음을 의미합니다.
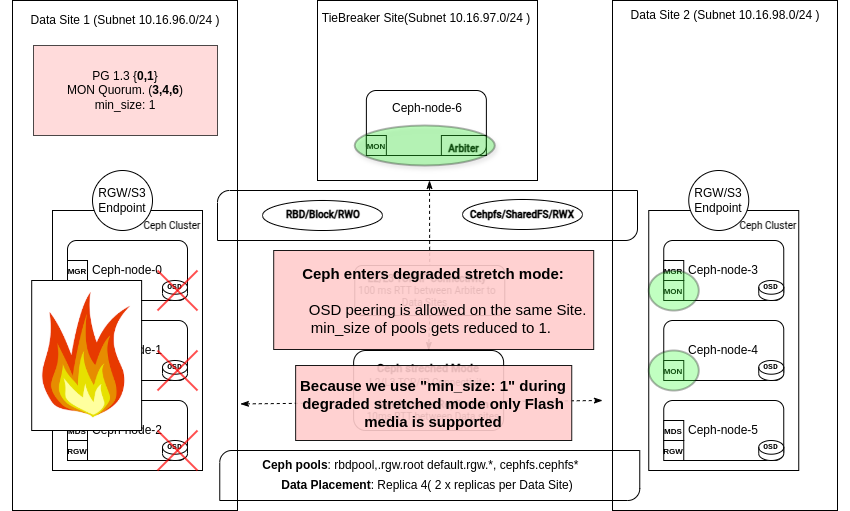
스트레치 모드 피어링 규칙이 완화되었습니다.¶
스트레치 모드에서 Ceph는 배치 그룹(PG)이 피어링에서 active+clean로 전환되기 전에 동작 세트의 각 사이트에서 최소 하나의 OSD가 참여하도록 요구하는 특정 스트레치 피어링 규칙을 구현합니다. 이 규칙은 한 사이트가 완전히 오프라인 상태일 경우 새로운 쓰기 작업이 확인되지 않도록 하여 스플릿 브레인(split-brain) 시나리오를 방지하고 일관된 사이트 복제를 보장합니다.
저하 모드에 들어가면 Ceph는 CRUSH 규칙을 일시적으로 수정하여 PG를 활성화하는 데 남은 사이트만 필요하도록 하여 클라이언트 작업을 원활하게 계속할 수 있도록 합니다.
# ceph pg dump pgs_brief | grep 2.11 dumped pgs_brief 2.11 active+undersized+degraded [8,11] 8 [8,11] 8
모든 풀의 min_size가 1로 줄어듭니다.¶
한 사이트가 오프라인 상태가 되면 Ceph는 풀의 min_size속성을 2에서 1로 자동 으로 낮춰 각 배치 그룹(PG)이 사용 가능한 복제본을 하나만 사용하여 활성 상태를 유지하고 정리할 수 있도록 합니다. min_size를 2로 유지하면, 살아남은 사이트는 로컬 복제본의 절반을 손실하여 활성 PG를 유지할 수 없게 되고, 이로 인해 클라이언트 I/O가 중단됩니다. Ceph는 min_size를 일시적으로 1로 낮춤으로써 클러스터가 나머지 사이트에서 OSD 장애를 허용하고 오프라인 사이트가 복구될 때까지 읽기/쓰기를 계속 제공할 수 있도록 합니다.
임시로 min_size=1로 실행하면 오프라인 사이트가 복구될 때까지 데이터 사본을 하나만 사용할 수 있다는 점에 유의해야 합니다. 이렇게 하면 서비스 운영은 유지되지만, 기존 사이트에 추가 장애가 발생할 경우 데이터 손실 위험이 증가합니다. SSD 미디어를 사용하는 Ceph 클러스터는 빠른 복구를 보장하고 stretch degraded 운영 중 추가 구성 요소에 장애가 발생하더라도 데이터 사용 불가 또는 손실 위험을 최소화합니다.
# ceph osd pool ls detail pool 1 '.mgr' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 11.76 pool 2 'rbdpool' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 2.62
기본 OSD에 장애가 발생한 모든 PG는 영향을 받는 OSD가 down 선언되고 스트레치 모드별로 작동 세트가 수정될 때까지 클라이언트 작업에서 짧은 중단을 경험하게 됩니다.
클라이언트는 남아 있는 사이트의 두 사본에서 데이터를 계속 읽고 쓰면서 모든 쓰기에 대한 서비스 가용성과 RPO=0을 보장합니다.
스트레치 저하 모드에서 복구¶
오프라인 데이터 센터가 서비스로 복귀하면 OSD가 클러스터에 다시 합류하고 Ceph는 자동으로 저하된 스트레치 모드에서 전체 스트레치 모드로 전환됩니다. 이 프로세스에는 각 배치 그룹(PG)의 복제본 수를 4개로 복원하기 위한 복구 및 백필 작업이 포함됩니다.
OSD에 유효한 PG 로그가 있고 잠시만 다운된 경우, Ceph는 다른 복제본에서 새 업데이트만 복사하여 증분 복구를 수행합니다. OSD가 장시간 다운되고 PG 로그에 전체 델타 세트가 포함되지 않은 경우, Ceph는 OSD 백필 작업을 시작하여 전체 PG를 복사합니다. 이 작업은 권한 복제본의 모든 RADOS 객체를 체계적으로 검사하고, 반환된 OSD를 사용할 수 없었던 동안 발생한 변경 사항으로 업데이트합니다.
복구 및 백필은 완전한 중복성을 복원하기 위해 사이트 간에 데이터가 전송됨에 따라 추가 I/O를 수반합니다. 따라서 네트워크 계산 및 계획에 복구 처리량을 포함하는 것이 필수적입니다. Ceph는 구성 가능한 mClock 복구/백필 설정을 통해 이러한 작업을 제한하여 클라이언트 I/O에 과부하가 걸리지 않도록 설계되었습니다. 데이터 가용성과 내구성을 보장하기 위해 가능한 한 빨리 HEALTH_OK 상태로 복귀해야 하므로, 충분한 사이트 간 대역폭이 매우 중요합니다. 이는 일상적인 읽기/쓰기 작업뿐만 아니라 구성 요소 장애 발생 시 또는 클러스터 확장 시 발생하는 피크 트래픽을 처리할 수 있는 대역폭을 의미합니다.
영향을 받은 모든 PG가 복구 또는 백필을 완료하면, 각 사이트별로 필요한 두 개의 복사본이 최신 상태로 유지되고 사용 가능해지면서 active+clean 상태로 복귀합니다. 이후 Ceph는 저하 모드 동안 적용된 임시 변경 사항(예: min_size=1을 표준값인 min_size=2로 복원)을 원상 복구합니다. 이 과정이 완료되면 클러스터의 저하된 스트레치 모드 경고가 사라지며, 이는 완전한 중복성이 복원되었음을 의미합니다.
사이트 장애 및 복구에 대한 간단한 데모¶
이 간단한 데모에서는 RBD 블록 볼륨에서 지속적으로 읽기와 쓰기를 수행하는 애플리케이션을 실행합니다. 파란색과 녹색 점은 애플리케이션의 읽기 및 쓰기 시간과 지연 시간을 나타냅니다. 대시보드의 왼쪽과 오른쪽에는 DC의 상태가 표시되며, 개별 서버는 액세스할 수 없는 경우 다운된 것으로 표시됩니다. 데모에서는 전체 사이트가 손실되는 과정을 확인할 수 있으며, 애플리케이션은 OSD가 다운되었음을 감지하고 확인하는 데 걸리는 시간인 27초의 지연된 I/O만 보고합니다. 사이트가 복구되면 나머지 사이트의 복제본을 사용하여 PG가 복구되는 것을 확인할 수 있습니다.
결론¶
이 마지막 회에서는 두 사이트로 구성된 스트레치 클러스터가 데이터 센터 장애 발생 시 어떻게 대응하는지 살펴보았습니다. 이 클러스터는 자동으로 성능 저하 상태로 전환되어 서비스를 온라인 상태로 유지하고, 장애 발생 사이트가 복구되면 원활하게 복구됩니다. Ceph는 자동 다운 마킹, 완화된 피어링 규칙, 낮춰진 min_size values, 그리고 연결 복구 시 수정된 데이터의 동기화를 통해 최소한의 수동 개입으로 이러한 이벤트를 처리하고 데이터 손실을 방지합니다.
저자는 이 게시물을 작성하는 데 시간을 할애하여 커뮤니티를 지원해 준 IBM에 감사드리고 싶습니다.
