Ceph Blog(https://ceph.io/en/news/blog/)를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://ceph.io/en/news/blog/2025/benchmarking-object-part2/

소개
이 게시물은 올플래시 IBM Storage Ceph (Dell) Ready Node에서 Ceph Object Gateway(RGW) 벤치마킹에 대한 블로그 시리즈의 두 번째 글입니다. 1부를 아직 읽지 않으셨다면 1부부터 읽어보시길 권장합니다. 1부에서는 하드웨어 및 소프트웨어 구성, 네트워크 아키텍처, 벤치마킹 방법론을 포함하여 테스트 환경에 대한 포괄적인 정보를 제공합니다.
이번 기사에서는 최대 처리량, 최대 IOPS, 수평적 확장성 결과에 초점을 맞춰 주요 성능 결과를 살펴보겠습니다.
리소스 병치에 대한 참고 사항: 모든 서비스(RGW, Monitor, Manager, OSD, Ingress)는 모든 노드에 병치 방식으로 배포되었습니다. 이는 일반적인 실제 배포 패턴을 반영하지만, 리소스 공유로 인해 내부 경합이 발생할 수 있음을 의미합니다. 이러한 결과는 이러한 상충 관계를 고려하여 수집되었으며, 서비스를 추가로 분리하면 특정 워크로드에서 더 높은 성능을 얻을 수 있습니다.
최대 처리량 성능 하이라이트
Ceph Object Gateway(RGW)의 상한선을 찾아내기 위한 노력의 일환으로, 우리는 이상적인 조건에서 12노드 All-NVMe(288 OSD) 클러스터를 테스트했습니다. 이 클러스터에서는 최적화된 EC 프로필, 대용량 객체 크기, 높은 클라이언트 동시성을 통해 플랫폼의 성능을 최대치로 끌어올렸습니다.
최대 GET 처리량
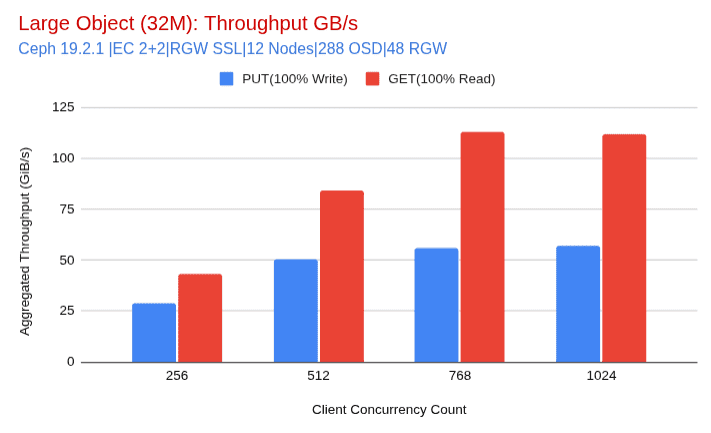
- 32 MiB 객체(EC 2+2, RGW SSL 활성화, 12개 노드, 1024개 클라이언트 스레드)를 사용하여 111 GiB/s의 총 GET 처리량을 달성했습니다.
- 이는 노드당 9.25GiB/s에 해당하며 Ceph 노드 하드웨어의 물리적 네트워크 용량의 한계를 뛰어넘습니다.
- 제한 요인: 네트워크. 각 노드에는 LACP를 통해 연결된 듀얼 100 GE NIC가 장착되어 있습니다. 그러나 사용되는 Intel 카드는 각 카드의 모든 포트에 대해 총 대역폭이 100Gbps(12.5GiB/s)로 제한됩니다. 이러한 점을 고려할 때, 클러스터 전체에서 약 111GiB/s의 결과는 프레이밍 오버헤드를 고려할 때 회선 속도 포화 상태에 매우 근접했음을 보여줍니다.
최대 PUT 처리량
- 비슷한 테스트 조건에서 총 PUT 처리량은 65.8GiB/s에 도달했습니다.
- PUT 작업은 복제를 위해 본질적으로 추가 I/O를 필요로 하며, 특히 EC의 경우 클러스터 내 데이터 이동량이 증가합니다. 이것이 PUT 처리량이 GET보다 낮은 이유입니다.
- 이러한 사실에도 불구하고 각 노드는 여전히 평균적으로 ~5.5GiB/s를 전달했습니다. 복제 트래픽을 고려하면 이는 다시 노드의 효과적인 NIC 제한에 가까워진다는 것을 의미합니다.
CPU 및 메모리 사용률
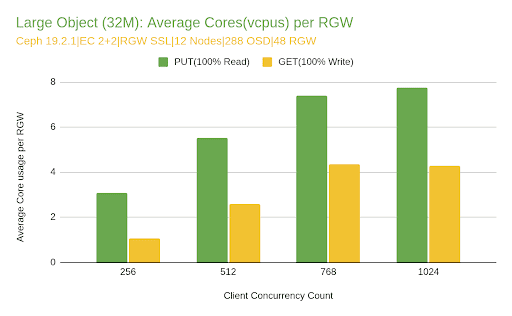
- RGW 프로세스의 CPU 사용률은 범위 내에 머물렀습니다(768개 vCPU에 걸쳐 클러스터 전체 RGW CPU의 8~14%). 이는 RGW나 CPU 리소스가 대규모 개체 작업 부하에서 병목 현상이 아니라는 것을 확인시켜 주었습니다.
- 지연 시간은 EC 프로필(2+2, 4+2, 8+3) 전체에서 일관되게 유지되었으며, 이는 테스트 중에 컴퓨팅 리소스가 아닌 네트워크가 제한 요소였음을 더욱 잘 보여줍니다.
최대 IOPS 성능 하이라이트
대형 객체 테스트는 클러스터의 원시 처리량 잠재력을 보여주었지만, 소형 객체 워크로드(64KiB)는 메타데이터 및 IOPS 확장성의 한계를 드러내는 데 도움이 되었습니다. 12노드 All-NVMe 클러스터와 높은 클라이언트 동시성을 사용하여 여러 EC 구성에서 GET 및 PUT 작업을 모두 테스트하여 플랫폼이 소형 객체 크기에서 감당할 수 있는 초당 최대 작업량을 분리했습니다.
최대 GET IOPS
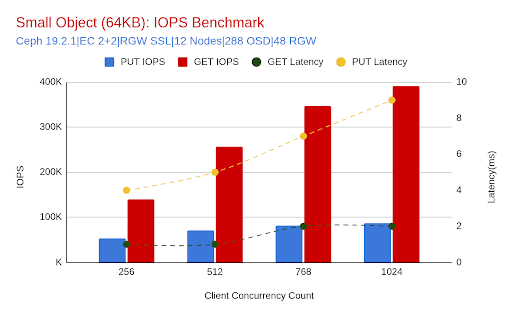
- 64KiB 객체(EC 2+2, SSL 없음, 노드 12개, 클라이언트 스레드 1024개)를 사용하여 약 391K GET IOPS를 달성했습니다. 이는 총 GET 처리량 약 24.4GiB/s와 평균 지연 시간 약 2ms에 해당합니다.
- 제한 요인: RGW의 CPU 사용량이 증가하기 시작했지만(768개 vCPU에서 약 9.8%), 시스템에는 여전히 여유 공간이 있었습니다. 낮은 지연 시간과 클라이언트 스레드 전반의 일관된 확장성은 클러스터가 클라이언트 측 리소스/동시성을 추가로 확보할 경우 더 높은 IOPS를 제공할 수 있음을 시사합니다.
최대 PUT IOPS
- 동일한 구성(64KiB, EC 2+2, SSL이 적용된 RGW, 12개 노드, 1024개 클라이언트 스레드)에서 약 86.6K PUT IOPS가 기록되었습니다. PUT 처리량은 최대 약 5.4GiB/s였으며, 완전 동시성(1024개 클라이언트 스레드)에서 평균 지연 시간은 약 8ms였습니다.
- 제한 요인: PUT 작업은 삭제 코딩 쓰기로 인해 백엔드 조정이 더 많이 필요합니다. RGW CPU 사용량은 낮은 수준(~2.9%)을 유지했지만, OSD 계층과 I/O 복잡성이 추가적인 성능 향상을 제한했을 가능성이 높습니다. GET과 PUT IOPS 간의 차이는 워크로드 비용의 이러한 본질적인 비대칭성을 반영합니다.
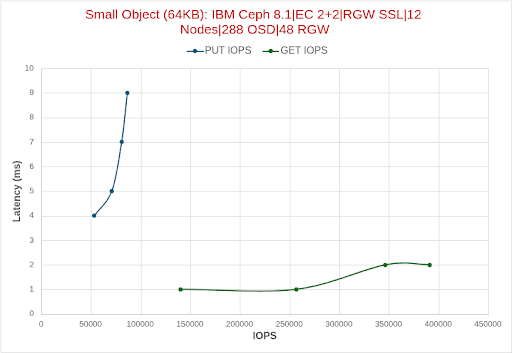
CPU 및 메모리 사용률
소규모 객체 워크로드(64KB)의 경우, RGW CPU 사용량은 GET 작업과 PUT 작업 간에 뚜렷한 차이를 보였습니다. GET 워크로드는 RGW 데몬당 CPU 사용량이 상당히 높았는데, 낮은 동시성에서는 약 3코어에서 8개의 클라이언트(1,024개 스레드)를 사용하는 경우 RGW당 거의 10코어로 증가했습니다. 반면, PUT 워크로드는 지속적으로 더 가벼웠으며, 최대 동시성에서도 RGW당 최대 3코어 미만으로 나타났습니다.
이러한 동작은 GET 요청의 양이 많기 때문입니다(아래 그래프 참조). 최대 39만 IOPS가 넘는 GET 요청은 개별적으로는 가볍지만, 엄청난 빈도로 인해 더 많은 CPU 사이클을 요구합니다. 또한, PUT 요청은 더 많은 I/O 경로를 사용하지만, 더 낮은 속도(약 8만 7천 IOPS)로 발생하며 쓰기 경로 최적화의 이점을 제공합니다.
참고: 프로덕션 환경의 객체 스토리지 워크로드는 읽기 중심(GET 중심)인 경향이 있습니다. 이 패턴은 분석 파이프라인, 데이터 레이크, 미디어 전송 시스템 등의 일반적인 사용 사례와 일치합니다.
RGW 데몬 전체의 메모리 사용량은 테스트 내내 안정적으로 유지되었으며, 메모리 부족이나 누수의 징후는 없었습니다. 각 RGW 데몬은 PUT 시 170~260MiB, GET 시 205~260MiB의 메모리를 사용했으며, 동시성이 증가함에 따라 점진적으로 증가하는 경향을 보였습니다.
이러한 결과는 CPU 가용성이 소규모 객체 워크로드, 특히 높은 GET 요청 빈도에서 주요 성능 요인임을 보여줍니다. IOPS가 수십만 대까지 확장됨에 따라, 낮은 지연 시간과 높은 처리량을 유지하기 위해서는 충분한 CPU 리소스를 프로비저닝하는 것이 매우 중요합니다.
EC 2+2(4MB 객체)를 통한 수평적 확장성¶
Ceph 객체 게이트웨이(RGW) 확장의 영향을 평가하기 위해, 삭제 코딩 2+2 프로파일, 4MB 객체 크기, 그리고 RGW 계층에서 활성화된 SSL을 사용하여 통제된 테스트를 수행했습니다. 이 특정 EC 프로파일은 4, 8, 12노드 배포에 모두 유효하여 공정한 비교가 가능하기 때문에 선택되었습니다.
노드와 OSD의 수를 점진적으로 늘려가면서 동일한 클라이언트 동시성과 요청 크기에서 시스템이 처리량, 지연 시간, 리소스 소비 측면에서 어떻게 반응하는지 관찰했습니다.
분석¶
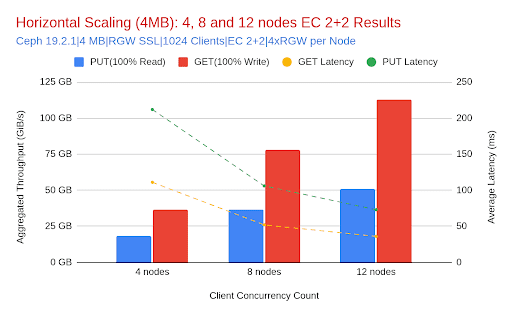
- 예측 가능한 선형 확장: 클러스터가 4개 노드에서 12개 노드로 확장됨에 따라 GET 처리량은 약 39GiB/s에서 약 113GiB/s로 거의 세 배 증가했습니다. PUT 처리량도 약 15.5GiB/s에서 50GiB/s 이상으로 3배 이상 증가했습니다. 이러한 선형적인 확장은 Ceph Object Gateway의 읽기 및 쓰기 작업 모두에 대한 수평 확장성의 효율성을 더욱 강화합니다.
- 지연 시간, 안정성 및 개선: GET 지연 시간은 클러스터 확장 시에도 안정적으로 유지되고 개선되었습니다. 12노드 배포는 처리량이 상당히 증가했음에도 불구하고 8노드 배포(52ms)보다 지연 시간(36ms)이 더 짧았습니다. 이는 대규모 환경에서 경합이 감소하고 병렬 처리가 향상되었음을 나타냅니다.
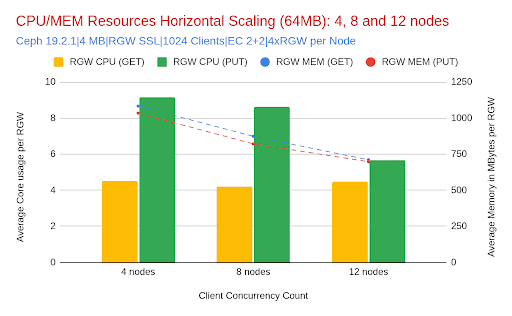
- CPU 및 메모리 리소스:
Ceph 분산 아키텍처의 주요 장점 중 하나는 클러스터 크기가 증가함에 따라 서비스별 리소스를 분할 상환할 수 있다는 것입니다. 64MiB 객체와 1024개의 동시 스레드를 사용하는 테스트 결과, 노드를 추가할수록 데몬당 RGW CPU 및 메모리 사용량이 감소하는 반면, 처리량은 3배 이상 증가했습니다. 삭제 코딩 계산으로 인해 일반적으로 리소스 사용량이 높은 PUT 작업의 경우, RGW CPU 사용량이 4노드에서 데몬당 약 9.2코어에서 12노드에서는 5.7코어로 감소했습니다. 마찬가지로 RGW 메모리 사용량은 클러스터가 확장됨에 따라 약 1035MiB에서 약 698MiB로 감소했습니다. GET 작업도 비슷한 추세를 보였습니다. 메모리는 RGW당 약 35% 감소했지만 CPU는 지속적으로 낮은 수준을 유지했습니다.
이 테스트는 Ceph 클러스터에 노드를 추가하면 원시 스토리지 용량이 증가할 뿐만 아니라 그에 비례하여 처리량과 효율성도 향상됨을 보여줍니다. 백업, 미디어 파이프라인, AI 학습 세트 스테이징 등 대용량 객체 워크로드의 경우 이러한 수평적 확장 패턴이 필수적입니다. 일관된 구성과 적절한 튜닝을 통해 Ceph 객체 게이트웨이(RGW)는 증가하는 성능 요구를 충족하기 위해 선형적이고 예측 가능한 확장을 지원합니다.
Replica 3 vs EC 2+2: 성능에 미치는 객체 크기의 영향¶
다양한 객체 크기에 따른 복제 및 삭제 코딩의 비교를 더 잘 이해하기 위해, 게이트웨이 수준에서 SSL을 활성화한 4노드 클러스터에서 복제본 3과 EC 2+2 프로필을 모두 사용하여 Ceph RGW를 테스트했습니다. 이상적으로는 12개 노드로 비교 범위를 확장하는 것이 좋겠지만, 시간 제약으로 인해 복제본 3은 4개 노드에서만 테스트했습니다. Tentacle이 출시되어 빠른 EC 개선 사항이 도입되면 더 큰 규모의 배포 환경에서 이 벤치마크를 다시 검토할 계획입니다.
각 시나리오는 4노드 클러스터의 포화 상태를 방지하기 위해 512개의 클라이언트 스레드를 사용하여 테스트되었습니다. 객체 크기는 64KiB에서 256MiB까지 다양했으며, 다양한 I/O 프로필에서 복제 및 삭제 코딩이 어떻게 확장되는지 관찰했습니다.
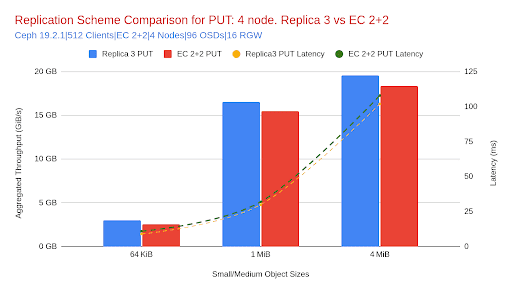
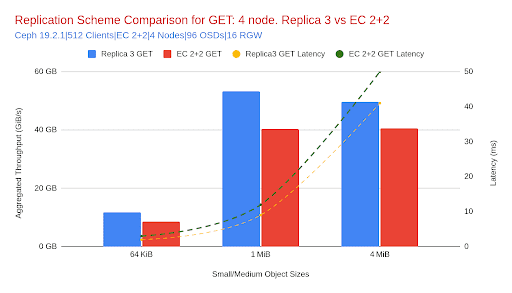
표 1: 처리량 및 지연 시간의 상대적 차이: 복제본 3 대 EC 2+2
긍정적 = 복제본 3의 성능이 더 좋습니다(처리량 증가, 지연 시간 감소)
| 객체 크기 | PUT 처리량 증가 | GET 처리량 증가 | PUT 지연 시간 개선 | GET 지연 시간 개선 |
|---|---|---|---|---|
| 64키로바이트 | +18% | +37% | +18% | +33% |
| 4미비 | +6% | +22% | +6% | +16% |
| 64미비 | +1% | +21% | +2% | +16% |
| 256MiB | +1% | +21% | +2% | +17% |
분석: 처리량 및 지연 시간 비교
- 더 작은 객체(64KiB)를 사용하는 경우, 복제본 3은 EC 2+2보다 훨씬 우수한 성능을 보였으며, PUT 처리량은 18%, GET 처리량은 37% 증가했습니다. 이는 예상과 일치합니다. EC의 인코딩/디코딩 오버헤드는 지연 시간과 연산 비용을 증가시키므로, 복제본 3은 높은 연산량을 요구하는 작은 객체 워크로드에 더 적합합니다.
- 객체 크기가 커짐에 따라 복제본 3의 처리량 이점은 줄어듭니다. 1MiB와 4MiB에서는 성능 차이가 눈에 띄지만 그 차이는 작습니다. 복제본 3은 GET 처리량이 8~9%, PUT 처리량이 6~7% 더 높습니다.
- 그러나 64MiB와 같이 더 큰 클라이언트 객체 크기에서는 두 방식 모두 4노드 클러스터의 네트워크 포화점에 도달하여 처리량이 정체됩니다. 결과적으로 성능 차이는 미미해지고 두 방식 모두 아키텍처상의 이점을 충분히 활용할 수 없습니다. 따라서 복제 효율성을 비교하는 데 있어 64MiB 결과의 신뢰성이 떨어집니다.
- 지연 시간 추세는 처리량을 반영합니다. Replica 3은 모든 크기에서 더 낮은 PUT 및 GET 지연 시간을 유지하지만, 상대적인 개선 효과는 객체 크기에 따라 감소하여 64KiB에서는 GET 속도가 33% 빨라졌지만 64MiB에서는 약 16%로 감소했습니다.
앞으로의 전망: EC 성능 향상
작은 객체 크기에서의 성능 격차는 향후 릴리스에서 줄어들 것으로 예상됩니다. Ceph Tentacle은 삭제 코딩 패딩의 비효율성을 해결하고 작은 객체의 성능을 향상시키는 Fast EC를 도입했습니다 . 이러한 향상된 기능 덕분에 삭제 코딩은 빈도가 높은 작은 객체 워크로드에서도 더욱 매력적인 옵션이 될 것입니다.
Ceph Day London 슬라이드 자료 와 영상 에서 Fast EC 개선 사항에 대한 자세한 내용을 확인해 보세요 . FastEC 초기 벤치마크 결과 그래프를 추가하여 여러분의 흥미를 더할 예정입니다.
다음에 나올 내용
다음 게시물에서는 TLS/SSL, SSE-S3, msgr v2 등 다양한 보안 구성으로 인해 발생하는 장단점을 살펴보고, 이러한 장단점이 소규모 및 대규모 객체 워크로드에서 Ceph 객체 게이트웨이(RGW) 성능에 미치는 영향을 살펴보겠습니다. 또한 실제 벤치마킹 결과를 심층적으로 분석하면서 최적의 Ceph 객체 게이트웨이 대 CPU 비율을 분석해 보겠습니다.
3부를 여기에서 읽어보세요
저자는 이 게시물을 작성하는 데 시간을 할애하여 커뮤니티를 지원해 준 IBM에 감사드리고 싶습니다.
