Ceph Blog(https://ceph.io/en/news/blog/)를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://ceph.io/en/news/blog/2025/crimson-balance-cpu-part1/
Crimson: 새로운 OSD 고성능 아키텍처¶
Crimson 은 새로운 OSD 고성능 아키텍처의 프로젝트 이름입니다. Crimson은 최신 하드웨어에서 고성능 서버 애플리케이션을 위한 고급 오픈소스 C++ 프레임워크인 Seastar 프레임워크를 기반으로 구축되었습니다 . Seastar는 퓨처, 프라미스, 코루틴과 같은 비동기 계산 기본 요소를 사용하여 아무것도 공유하지 않는 아키텍처에서 I/O 리액터를 구현합니다. I/O 리액터 스레드는 일반적으로 시스템의 특정 CPU 코어에 고정됩니다. 그러나 기존 소프트웨어, 즉 리액터가 아닌 블로킹 작업과의 상호 작용을 지원하기 위해 Seastar에서는 Alien 스레드 메커니즘을 사용할 수 있습니다. 이를 통해 리액터가 아닌 아키텍처와 I/O 리액터 아키텍처 간의 인터페이스가 가능합니다. Crimson에서 Alien 스레드는 Bluestore를 지원하는 데 사용됩니다.
이 프로젝트에 대한 매우 좋은 소개가 있는데, 특히 Ceph 커뮤니티 Youtube 채널에서 Sam Just 와 Matan Breizman 이 만든 다음 영상을 확인해 보세요.
성능 관점에서 중요한 질문은 Seastar 리액터 스레드를 사용 가능한 CPU 코어에 할당하는 것입니다. 이는 특히 최신 NUMA (Non-Uniform Memory Access) 아키텍처에서 중요한데, 스레드가 실행 중인 동일한 CPU 소켓에 속한 로컬 메모리와 달리 다른 CPU 소켓에서 메모리에 액세스하는 경우 지연 시간 페널티가 발생합니다. 또한, 동일 CPU 코어 내에서 리액터와 다른 비리액터 스레드 간의 상호 배제를 보장해야 합니다. 주된 이유는 Seastar 리액터 스레드는 비차단형인 반면, 비리액터 스레드는 차단이 허용되기 때문입니다.
이 PR 의 일환으로 우리는 OSD 스레드에 대한 CPU 할당 전략을 설정하기 위한 스크립트 vstart.sh에 새로운 옵션을 도입했습니다 .
- OSD 기반 : 동일한 NUMA 소켓의 CPU 코어를 동일한 OSD에 할당하는 방식입니다. 간단히 설명하자면, OSD ID가 짝수이면 모든 리액터 스레드가 NUMA 소켓 0에 할당되고, OSD ID가 홀수이면 모든 리액터 스레드가 NUMA 소켓 1에 할당됩니다. 다음 그림은 이 전략을 보여줍니다(‘R’은 ‘Reactor’ 스레드를 의미하며, 숫자 ID는 OSD ID에 해당).

- NUMA 소켓 기반 : 이는 각 NUMA 소켓에서 리액터로 CPU 코어를 균등하게 할당하여 모든 OSD가 두 NUMA 소켓 모두에 할당된 리액터로 끝나도록 합니다.

기본적으로 옵션이 지정되지 않으면 vstart는 다음과 같이 연속된 순서로 반응기 스레드를 할당합니다.

vstart.sh 스크립트는 개발자 모드에서만 사용되며, 이 경우처럼 실험에 매우 유용하다는 점을 언급할 가치가 있습니다 .
이 블로그 게시물의 구조는 다음과 같습니다.
- 먼저, 실행한 하드웨어 및 성능 테스트를 간략하게 설명하고, 몇 가지 예시를 들어 설명하겠습니다. Ceph에 익숙한 독자라면 이 섹션은 건너뛰어도 좋습니다.
- 두 번째 섹션에서는 세 가지 CPU 할당 전략을 비교하는 성능 테스트 결과를 보여줍니다. Crimson에서 지원하는 세 가지 백엔드 클래스를 사용했는데, 다음과 같습니다.
- Cyanstore : 시스템의 물리적 드라이브를 사용하지 않는 메모리 내 순수 리액터 OSD 클래스입니다. 이 OSD 클래스를 사용하는 이유는 시스템의 메모리 액세스 속도를 포화시켜 물리적 드라이브의 간섭(즉, 지연 시간) 없이 Crimson에서 가능한 가장 높은 I/O 속도를 파악하기 위해서입니다.
- Seastore : 이 역시 머신의 물리적 NVMe 드라이브를 구동하는 순수 리액터 OSD 클래스입니다. 이 클래스의 전반적인 성능은 Cyanstore의 성능에 비해 극히 미미할 것으로 예상됩니다.
- Bluestore : Crimson의 기본 OSD 클래스이자 Ceph의 Classic OSD 클래스입니다. 이 클래스는 Alien 스레드의 참여를 필요로 하는데, 이는 Seastore에서 블로킹 스레드 풀을 처리하는 기술입니다.
비교 결과는 성능 최적화에 대한 한계와 기회를 모두 강조하기 때문에 흥미롭습니다.
성능 테스트 계획¶
간단히 말해서, 고정된 수의 OSD를 포함하고 여러 I/O 리액터(암묵적으로 해당 CPU 코어 수에 해당)를 사용하는 여러 클러스터 구성에 대해 일반적인 클라이언트 워크로드(임의 4K 쓰기, 임의 4K 읽기; 순차적 64K 쓰기, 순차적 64K 읽기)를 사용하여 성능을 측정하고자 합니다. 기존 객체 저장소인 Cyanstore(메모리 내), Seastore, Bluestore를 비교하고자 합니다. 전자와 후자는 “순수 리액터”이고, 후자는 (차단) Alien 스레드 풀을 사용합니다.
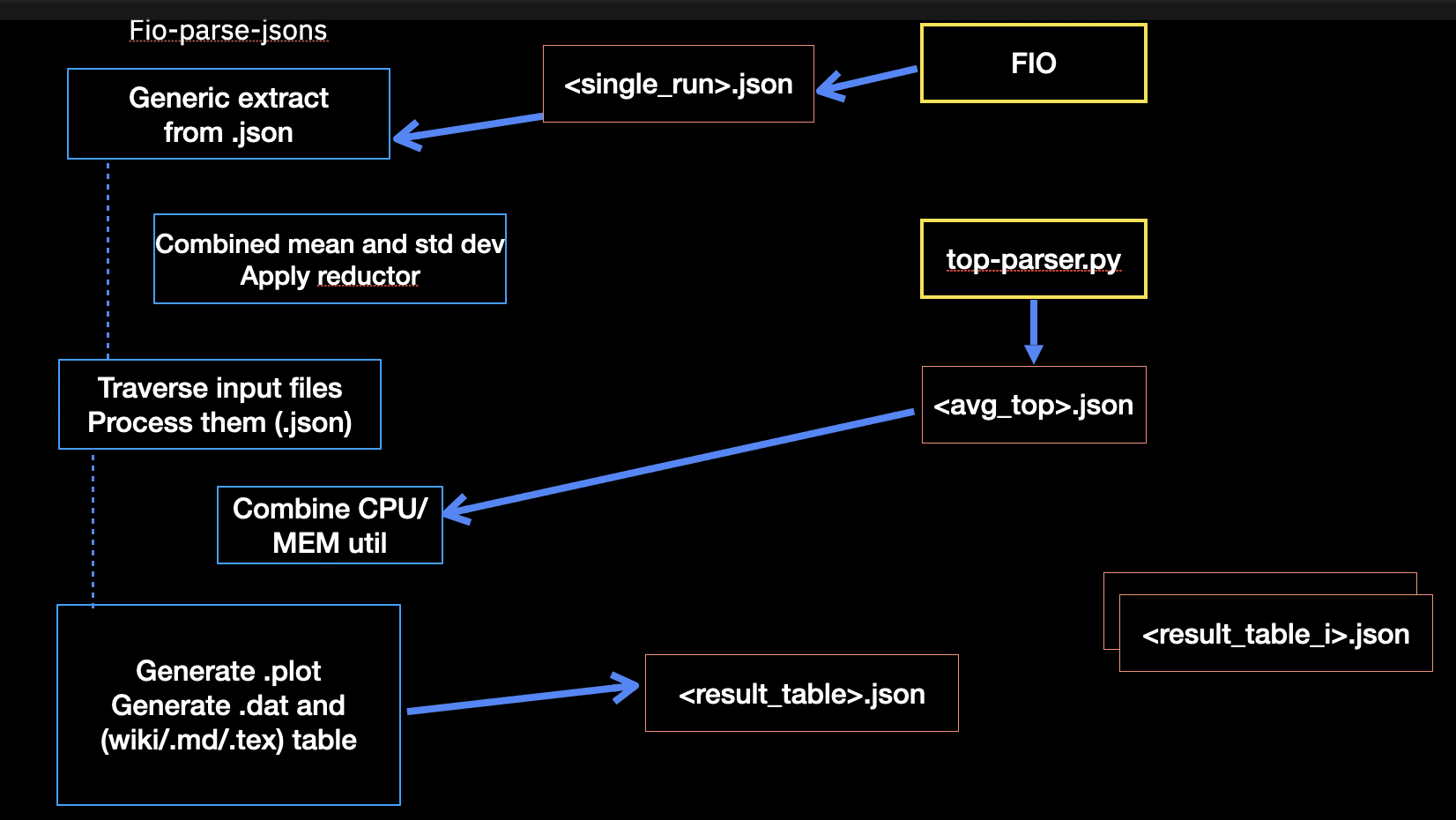
클라이언트 측면에서는 앞서 언급한 일반적인 워크로드에 대해 FIO를 사용하여 10GiB 크기의 RBD 볼륨을 실행합니다. FIO .json 파일 출력(I/O 처리량 및 지연 시간)에서 클라이언트 결과를 합성하고 OSD 프로세스의 측정값과 통합합니다. 여기에는 일반적으로 CPU 및 메모리 사용률(Linux 명령 top에서 사용)이 포함됩니다. 이 워크플로는 다음 다이어그램에 설명되어 있습니다.
실제 실험에서는 OSD 개수(1, 3, 5, 8)와 리액터 개수(1, 2, 4, 6)에 대해 범위를 설정했습니다. 결과 개수가 상당히 많아 이 블로그를 읽는 것이 다소 지루할 수 있으므로, 대표적인 OSD 8개와 I/O 리액터 5개만 표시하기로 했습니다.
우리는 다음과 같은 하드웨어와 시스템 구성을 갖춘 단일 노드 클러스터를 사용했습니다.
- CPU: 2 x Intel(R) Xeon(R) Platinum 8276M CPU @ 2.20GH(각 56코어)
- 메모리: 394GiB
- 드라이브: 8 x 93.1TB NVMe
- OS: 커널 5.14.0-511.el9.x86_64의 Centos 9.0
- Ceph: 버전 b2a220(bb2a2208867d7bce58b9697570c83d995a1c5976) squid(dev)
- podman 버전 5.2.2.
Ceph는 다음 옵션으로 구축됩니다.
# ./do_cmake.sh -DWITH_SEASTAR=ON -DCMAKE_BUILD_TYPE=RelWithDebInfo
높은 수준에서 우리는 다음과 같이 성능 테스트를 시작합니다.
/root/bin/run_balanced_crimson.sh -t cyan
이 명령은 Cyanstore 객체 백엔드에 대한 테스트 계획을 실행하여 세 가지 CPU 할당 전략에 대한 응답 곡선 데이터를 생성합니다. 인수 ‘ -t‘는 객체 스토리지 백엔드를 지정하는 데 사용됩니다. cyan, sea, blue는 각각 Cyanstore , Seastore, Bluestore를 지정합니다.
crimson_be_table["cyan"]="--cyanstore"
crimson_be_table["sea"]="--seastore --seastore-devs ${STORE_DEVS}"
crimson_be_table["blue"]="--bluestore --bluestore-devs ${STORE_DEVS}"
실행이 완료되면 결과는 작업 부하에 따라 .zip 파일로 보관되고 옵션 -d(기본값 /tmp)을 사용하여 지정할 수 있는 출력 디렉터리에 저장됩니다.생성된 결과의 스냅샷을 보려면 클릭하세요.
cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread.zip cyan_8osd_5reactor_8fio_bal_socket_rc_1procs_seqread.zip cyan_8osd_6reactor_8fio_bal_osd_rc_1procs_randread.zip cyan_8osd_6reactor_8fio_bal_socket_rc_1procs_seqread.zip cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randwrite.zip cyan_8osd_5reactor_8fio_bal_socket_rc_1procs_seqwrite.zip cyan_8osd_6reactor_8fio_bal_osd_rc_1procs_randwrite.zip cyan_8osd_6reactor_8fio_bal_socket_rc_1procs_seqwrite.zip cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_seqread.zip
각 아카이브에는 해당 워크로드 실행의 결과 출력 파일과 측정값이 포함되어 있습니다.클릭하면 결과 .zip 파일 내부를 볼 수 있습니다.더 중요한 파일은 다음과 같습니다.
cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread.json: I/O 처리량 및 지연 시간 측정값을 포함하는 (통합된) FIO 출력 파일입니다. OSD 프로세스의 CPU 및 MEM 사용률도 통합되어 있습니다.cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_cpu_avg.json: OSD 및 FIO CPU 및 MEM 사용률 평균입니다. 이 데이터는 OSD 프로세스와 FIO 클라이언트 프로세스에서 top 명령을 통해 수집되었습니다(5분 동안 30개 샘플).cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_diskstat.json: diskstat 출력. 테스트 전후에 샘플을 추출했으며, .json 파일에 차이점이 포함되어 있습니다.cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top.json: top의 출력을 jc를 통해 파싱하여 .json 파일을 생성합니다. 참고 : jc는 아직 개별 CPU 코어 사용률을 지원하지 않으므로, 스레드별 전체 CPU 사용률을 사용해야 합니다.new_cluster_dump.jsonceph tell ${osd_i} dump_metrics: 개별 OSD 성능 측정 항목을 포함하는 명령 의 출력입니다 .FIO_cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top_cpu.plot: FIO 클라이언트의 시간 경과에 따른 CPU 사용률을 보여주는 상단 출력에서 기계적으로 생성된 플롯입니다.OSD_cyan_8osd_5reactor_8fio_bal_osd_rc_1procs_randread_top_mem.plot: OSD 프로세스에 대한 시간 경과에 따른 MEM 활용도를 보여주는 상단 출력에서 기계적으로 생성된 플롯입니다.
후처리 및 나란히 비교를 생성하려면 다음 스크립트를 실행합니다.
# /root/bin/pp_balanced_cpu_cmp.sh -d /tmp/_seastore_8osd_5_6_reactor_8fio_rc_cmp \ -t sea -o seastore_8osd_5vs6_reactor_8fio_cpu_cmp.md
인수는 다음과 같습니다. 비교하려는 실행이 포함된 입력 디렉토리, 객체 저장소 백엔드의 유형, 생성할 출력은 .md입니다.
다음 섹션에서는 비교 결과를 보여드리겠습니다.
이 섹션을 마무리하면서 위 스크립트의 내부를 살펴보고 드라이브 사전 조정, 클러스터 생성, FIO 실행 및 수집된 메트릭에 대한 세부 정보를 보여드리겠습니다.
드라이브 사전 조정¶
드라이브의 일관된 상태를 보장하기 위해 FIO steadystate 옵션을 사용하여 쓰기 워크로드를 실행합니다. 이 옵션은 실제 성능 테스트를 실행하기 전에 드라이브가 안정적인 상태인지 확인합니다. 드라이브 전체 용량의 최대 70%까지 사전 조정합니다.
테스트 전후의 디스크 통계를 측정하고, diskstat_diff.py 스크립트를 사용하여 차이를 계산합니다. 스크립트는 저장소 ceph의 src/tools/contrib.
# jc --pretty /proc/diskstats > /tmp/blue_8osd_6reactor_192at_8fio_socket_cond.json
# fio rbd_fio_examples/randwrite64k.fio && jc --pretty /proc/diskstats \
| python3 diskstat_diff.py -d /tmp/ -a blue_8osd_6reactor_192at_8fio_socket_cond.json
Jobs: 8 (f=8): [w(8)][30.5%][w=24.3GiB/s][w=398k IOPS][eta 13m:41s]
nvme0n1p2: (groupid=0, jobs=8): err= 0: pid=375444: Fri Jan 31 11:43:35 2025
write: IOPS=397k, BW=24.2GiB/s (26.0GB/s)(8742GiB/360796msec); 0 zone resets
slat (nsec): min=1543, max=823010, avg=5969.62, stdev=2226.84
clat (usec): min=57, max=50322, avg=5152.50, stdev=2982.28
lat (usec): min=70, max=50328, avg=5158.47, stdev=2982.27
clat percentiles (usec):
| 1.00th=[ 281], 5.00th=[ 594], 10.00th=[ 1037], 20.00th=[ 2008],
| 30.00th=[ 3032], 40.00th=[ 4080], 50.00th=[ 5145], 60.00th=[ 6194],
| 70.00th=[ 7242], 80.00th=[ 8291], 90.00th=[ 9241], 95.00th=[ 9634],
| 99.00th=[10028], 99.50th=[10421], 99.90th=[14091], 99.95th=[16188],
| 99.99th=[19268]
bw ( MiB/s): min=15227, max=24971, per=100.00%, avg=24845.68, stdev=88.47, samples=5768
iops : min=243638, max=399547, avg=397527.12, stdev=1415.43, samples=5768
lat (usec) : 100=0.01%, 250=0.61%, 500=3.18%, 750=2.90%, 1000=2.88%
lat (msec) : 2=10.28%, 4=19.25%, 10=59.90%, 20=1.00%, 50=0.01%
lat (msec) : 100=0.01%
cpu : usr=19.80%, sys=15.60%, ctx=104026691, majf=0, minf=2647
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1%
issued rwts: total=0,143224767,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=256
steadystate : attained=yes, bw=24.3GiB/s (25.5GB/s), iops=398k, iops mean dev=1.215%
Run status group 0 (all jobs):
WRITE: bw=24.2GiB/s (26.0GB/s), 24.2GiB/s-24.2GiB/s (26.0GB/s-26.0GB/s), io=8742GiB (9386GB), run=360796-360796msec
클러스터 생성¶
Crimson에 적합한 옵션을 사용하여 클러스터를 생성하는 vstart.sh 스크립트를 사용합니다. CPU 할당 전략이 담긴 표는 다음과 같습니다.
# CPU allocation strategies declare -A bal_ops_table bal_ops_table["default"]="" bal_ops_table["bal_osd"]=" --crimson-balance-cpu osd" bal_ops_table["bal_socket"]="--crimson-balance-cpu socket"
각 Crimson 백엔드에 대해 CPU 전략의 순서를 기본적으로 탐색합니다. 스니펫에서는 OSD와 리액터의 개수를 반복하고, 새로운 옵션을 사용하여 CPU 할당 전략을 설정합니다.
중요 : vstart에 사용 가능한 CPU 코어 목록을 VSTART_CPU_CORES 변수로 설정했습니다. 이는 FIO 클라이언트에서 사용할 CPU를 “예약”하기 위해 사용됩니다(단일 노드 클러스터를 사용하고 있기 때문입니다).
# Run balanced vs default CPU core/reactor distribution in Crimson using either Cyan, Seastore or Bluestore
fun_run_bal_vs_default_tests() {
local OSD_TYPE=$1
local NUM_ALIEN_THREADS=7 # default
local title=""
for KEY in default bal_osd bal_socket; do
for NUM_OSD in 8; do
for NUM_REACTORS in 5 6; do
title="(${OSD_TYPE}) $NUM_OSD OSD crimson, $NUM_REACTORS reactor, fixed FIO 8 cores, response latency "
cmd="MDS=0 MON=1 OSD=${NUM_OSD} MGR=1 taskset -ac '${VSTART_CPU_CORES}' /ceph/src/vstart.sh \
--new -x --localhost --without-dashboard\
--redirect-output ${crimson_be_table[${OSD_TYPE}]} --crimson --crimson-smp ${NUM_REACTORS}\
--no-restart ${bal_ops_table[${KEY}]}"
# Alien setup for Bluestore, see below.
test_name="${OSD_TYPE}_${NUM_OSD}osd_${NUM_REACTORS}reactor_8fio_${KEY}_rc"
echo "${cmd}" | tee >> ${RUN_DIR}/${test_name}_cpu_distro.log
echo $test_name
eval "$cmd" >> ${RUN_DIR}/${test_name}_cpu_distro.log
echo "Sleeping for 20 secs..."
sleep 20
fun_show_grid $test_name
fun_run_fio $test_name
/ceph/src/stop.sh --crimson
sleep 60
done
done
done
}
Bluestore의 경우, 백엔드 CPU 코어 수의 4배로 외계인 스레드 수를 설정하는 특별한 사례가 있습니다(crimson-smp).
if [ "$OSD_TYPE" == "blue" ]; then
NUM_ALIEN_THREADS=$(( 4 *NUM_OSD * NUM_REACTORS ))
title="${title} alien_num_threads=${NUM_ALIEN_THREADS}"
cmd="${cmd} --crimson-alien-num-threads $NUM_ALIEN_THREADS"
test_name="${OSD_TYPE}_${NUM_OSD}osd_${NUM_REACTORS}reactor_${NUM_ALIEN_THREADS}at_8fio_${KEY}_rc"
fi
클러스터가 온라인 상태가 되면 풀과 RBD 볼륨을 생성합니다.
먼저 클러스터를 측정한 후, 필요에 따라 단일 RBD 풀과 볼륨을 생성합니다. 또한 클러스터, 풀, 그리고 PG의 상태도 표시합니다.
# Take some measurements
if pgrep crimson; then
bin/ceph daemon -c /ceph/build/ceph.conf osd.0 dump_metrics > /tmp/new_cluster_dump.json
else
bin/ceph daemon -c /ceph/build/ceph.conf osd.0 perf dump > /tmp/new_cluster_dump.json
fi
# Create the pools
bin/ceph osd pool create rbd
bin/ceph osd pool application enable rbd rbd
[ -z "$NUM_RBD_IMAGES" ] && NUM_RBD_IMAGES=1
for (( i=0; i<$NUM_RBD_IMAGES; i++ )); do
bin/rbd create --size ${RBD_SIZE} rbd/fio_test_${i}
rbd du fio_test_${i}
done
bin/ceph status
bin/ceph osd dump | grep 'replicated size'
# Show a pool’s utilization statistics:
rados df
# Turn off auto scaler for existing and new pools - stops PGs being split/merged
bin/ceph osd pool set noautoscale
# Turn off balancer to avoid moving PGs
bin/ceph balancer off
# Turn off deep scrub
bin/ceph osd set nodeep-scrub
# Turn off scrub
bin/ceph osd set noscrub
클러스터가 생성된 후 표시되는 기본 풀의 예는 다음과 같습니다. Crimson은 아직 Erasure Coding을 지원하지 않으므로 기본 복제본 집합을 참고하십시오.
pool 'rbd' created
enabled application 'rbd' on pool 'rbd'
NAME PROVISIONED USED
fio_test_0 10 GiB 0 B
cluster:
id: da51b911-7229-4eae-afb5-a9833b978a68
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 97s)
mgr: x(active, since 94s)
osd: 8 osds: 8 up (since 52s), 8 in (since 60s)
data:
pools: 2 pools, 33 pgs
objects: 2 objects, 449 KiB
usage: 214 MiB used, 57 TiB / 57 TiB avail
pgs: 27.273% pgs unknown
21.212% pgs not active
17 active+clean
9 unknown
7 creating+peering
pool 1 '.mgr' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode off last_change 15 flags hashpspool,nopgchange,crimson stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 7.89
pool 2 'rbd' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode off last_change 33 flags hashpspool,nopgchange,selfmanaged_snaps,crimson stripe_width 0 application rbd read_balance_score 1.50
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.mgr 449 KiB 2 0 6 0 0 0 41 35 KiB 55 584 KiB 0 B 0 B
rbd 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
total_objects 2
total_used 214 MiB
total_avail 57 TiB
total_space 57 TiB
noautoscale is set, all pools now have autoscale off
nodeep-scrub is set
noscrub is set
FIO 실행¶
저희는 Linux의 유연한 I/O 실행 도구인 FIO를 구동하기 위해 독립형 도구를 통해 몇 가지 기본 인프라를 개발했습니다 . 이 모든 도구는 제 github 프로젝트 저장소( 여기) 에서 공개적으로 사용할 수 있습니다 .
본질적으로 이 기본 인프라는 다음으로 구성됩니다.
- 다양한 워크로드(임의 4K 쓰기, 임의 4K 읽기, 순차적 64K 쓰기, 순차적 64K 읽기)에 대한 미리 정의된 FIO 구성 파일 세트입니다. 이러한 파일은 특히 여러 클라이언트, 여러 RBD 볼륨 등에 대해 필요에 따라 자동 생성될 수 있습니다.
- 다양한 I/O 깊이에 대한 처리량 및 지연 시간을 측정하는 응답 지연 곡선을 포함한 일련의 성능 테스트 프로파일을 제공하며, 리소스 사용률도 통합되어 있습니다. 또한 , 특정 지연 시간 목표에 대한 최대 I/O 처리량을 파악하는 데 유용한 빠른 지연 시간 목표 테스트도 생성할 수 있습니다.
- FIO 클라이언트와 OSD 프로세스의 리소스 사용률(CPU, MEM)을 측정하는 모니터링 루틴 세트입니다.
top명령을 사용하고 출력을jc로 구문 분석하여 .json 파일을 생성합니다. 이 파일을 FIO 출력과 통합하여 단일 .json 파일로 생성하고, gnuplot 스크립트를 동적으로 생성합니다. 또한 테스트 전후의 디스크 통계 스냅샷을 생성하여 차이를 계산합니다. 또한 gnuplot 차트를 통해 FIO 추적 결과를 집계합니다.
iodepth 옵션을 사용하여 장치에 전송되는 I/O 요청 수를 제어합니다. 응답 지연 시간 곡선 (하키 스틱 성능 곡선이라고도 함)에 관심이 있으므로 1에서 64까지 탐색합니다. RBD 볼륨당 하나의 작업을 사용하지만, 필요한 경우 가변적으로 사용할 수도 있습니다.
# Option -w (WORKLOAD) is used as index for these: declare -A m_s_iodepth=( [hockey]="1 2 4 8 16 24 32 40 52 64" ...) declare -A m_s_numjobs=( [hockey]="1" ... )
- 예비 단계로, 볼륨에 쓰기 워크로드를 준비합니다. 이 작업은 실제 성능 테스트를 실행하기 전에 수행됩니다. 볼륨당 하나의 클라이언트를 실행하여 실행이 동시에 이루어지도록 합니다.
# Prime the volume(s) with a write workloads
RBD_NAME=fio_test_$i RBD_SIZE="64k" fio ${FIO_JOBS}rbd_prime.fio 2>&1 >/dev/null &
echo "== priming $RBD_NAME ==";
...
wait;
- 메인 루프에서는 I/O 깊이 수를 반복하고, 미리 정의된 각 워크로드에 대해 FIO 명령을 실행합니다. 또한 테스트 전후의 디스크 통계 스냅샷을 생성하여 차이를 계산합니다. FIO 프로세스와 OSD 프로세스의 PID를 수집하여 리소스 사용률을 모니터링합니다. 지연 시간의 표준 편차가 중앙값에서 너무 크게 벗어나면 루프를 조기에 종료하는 휴리스틱을 적용합니다.
중요 : 주의 깊게 읽는 독자라면 FIO 클라이언트를 CPU 코어 세트에 바인딩하는 taskset 명령을 사용한다는 점을 알아차렸을 것입니다. 이는 FIO 클라이언트가 OSD 프로세스의 리액터를 방해하지 않도록 하기 위한 것입니다. 재현성을 보장하기 위해서는 워크로드 실행 순서가 중요합니다.
for job in $RANGE_NUMJOBS; do
for io in $RANGE_IODEPTH; do
# Take diskstats measurements before FIO instances
jc --pretty /proc/diskstats > ${DISK_STAT}
...
for (( i=0; i<${NUM_PROCS}; i++ )); do
export TEST_NAME=${TEST_PREFIX}_${job}job_${io}io_${BLOCK_SIZE_KB}_${map[${WORKLOAD}]}_p${i};
echo "== $(date) == ($io,$job): ${TEST_NAME} ==";
echo fio_${TEST_NAME}.json >> ${OSD_TEST_LIST}
fio_name=${FIO_JOBS}${FIO_JOB_SPEC}${map[${WORKLOAD}]}.fio
# Execute FIO
LOG_NAME=${log_name} RBD_NAME=fio_test_${i} IO_DEPTH=${io} NUM_JOBS=${job} \
taskset -ac ${FIO_CORES} fio ${fio_name} --output=fio_${TEST_NAME}.json \
--output-format=json 2> fio_${TEST_NAME}.err &
fio_id["fio_${i}"]=$!
global_fio_id+=($!)
done # loop NUM_PROCS
sleep 30; # ramp up time
...
fun_measure "${all_pids}" ${top_out_name} ${TOP_OUT_LIST} &
...
wait;
# Measure the diskstats after the completion of FIO
jc --pretty /proc/diskstats | python3 /root/bin/diskstat_diff.py -a ${DISK_STAT}
# Exit the loops if the latency disperses too much from the median
if [ "$RESPONSE_CURVE" = true ] && [ "$RC_SKIP_HEURISTIC" = false ]; then
mop=${mode[${WORKLOAD}]}
covar=$(jq ".jobs | .[] | .${mop}.clat_ns.stddev/.${mop}.clat_ns.mean < 0.5 and \
.${mop}.clat_ns.mean/1000000 < ${MAX_LATENCY}" fio_${TEST_NAME}.json)
if [ "$covar" != "true" ]; then
echo "== Latency std dev too high, exiting loops =="
break 2
fi
fi
done # loop IODEPTH
done # loop NUM_JOBS
FIO가 진행됨에 따라 동시에 실행되는 기본 모니터링 루틴은 아래와 같습니다.
fun_measure() {
local PID=$1 #comma separated list of pids
local TEST_NAME=$2
local TEST_TOP_OUT_LIST=$3
top -b -H -1 -p "${PID}" -n ${NUM_SAMPLES} >> ${TEST_NAME}_top.out
echo "${TEST_NAME}_top.out" >> ${TEST_TOP_OUT_LIST}
}
top에 대한 사용자 지정 프로필을 작성하여 부모 프로세스 ID, 스레드가 마지막으로 실행된 CPU 등에 대한 정보를 얻을 수 있도록 했습니다(일반적으로 기본적으로 표시되지 않음). 또한 jc를 확장하여 개별 CPU 코어 사용률을 지원할 계획입니다.
CBT(Ceph Benchmarking Tool)의 새로운 도구는 로컬 노트북과 클라이언트 엔드포인트 모두에서 사용할 수 있으므로 단독으로 확장하여 구현했습니다 . 추가적인 개념 증명이 진행 중입니다.
성능 결과 및 비교¶
이 섹션에서는 세 가지 객체 스토리지 백엔드에서 세 가지 CPU 할당 전략에 대한 성능 결과를 보여줍니다. 8개의 OSD와 5개의 리액터 구성에 대한 결과도 함께 제시합니다.
- 중요 : 이러한 결과는 단일 노드 클러스터를 기반으로 하며, 사용된 하드웨어의 특성과 한계로 인해 실험적 결과로 간주해야 하며 최종 기준으로 사용해서는 안 됩니다.
흥미로운 점은 특정 CPU 할당 전략이 다른 전략보다 유의미한 이점을 제공하는 것은 아니지만, 다양한 CPU 할당 전략의 이점을 얻는 워크로드가 있다는 것입니다. 이러한 결과는 대부분의 워크로드에서 다양한 객체 스토리지 백엔드에서 일관되게 나타났습니다.
응답 지연 곡선은 지연 시간의 표준 편차를 나타내는 오차 막대로 확장됩니다. 이는 지연 시간이 중앙값(평균 지연 시간)에서 어떻게 분산되는지 관찰하는 데 유용합니다. 표시된 모든 결과에 대해 위에서 언급한 휴리스틱을 비활성화하여 모든 데이터 포인트가 요청된 대로(iodepth 1부터 64까지) 표시되도록 했습니다.
각 워크로드에 대해 세 가지 객체 스토리지 백엔드에서 세 가지 CPU 할당 전략을 비교합니다. 마지막으로 세 가지 객체 스토리지 백엔드에서 단일 CPU 할당 전략에 대한 결과를 비교합니다.
무작위 4K 읽기¶
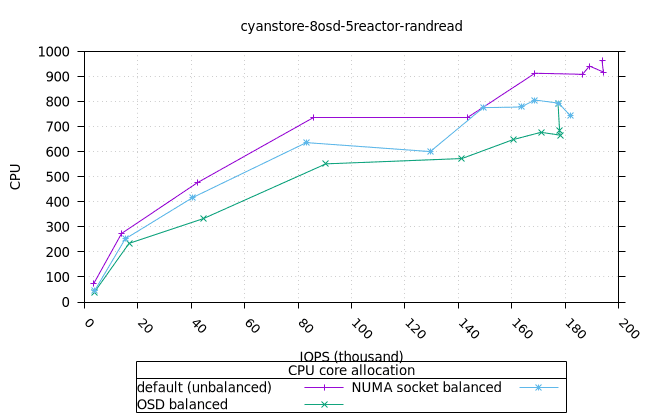
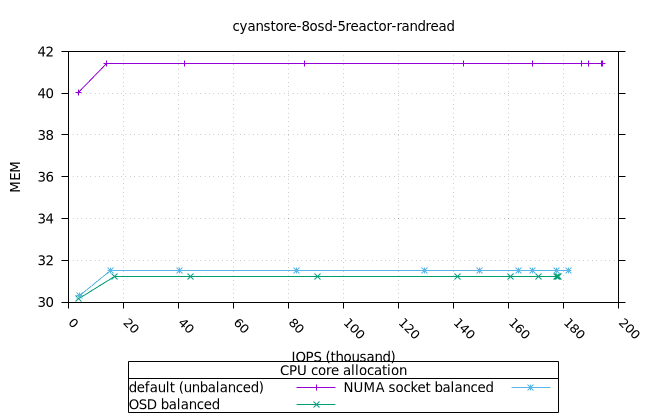
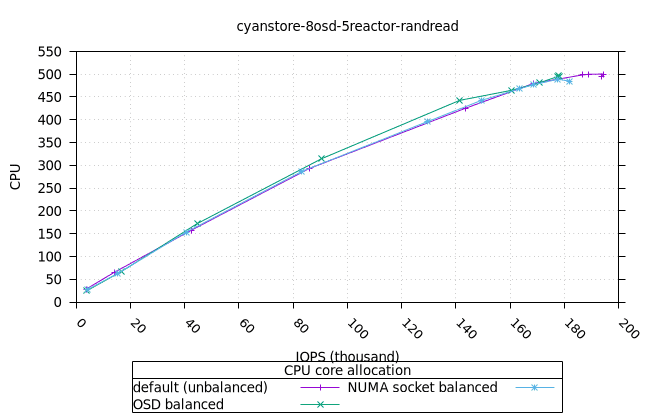
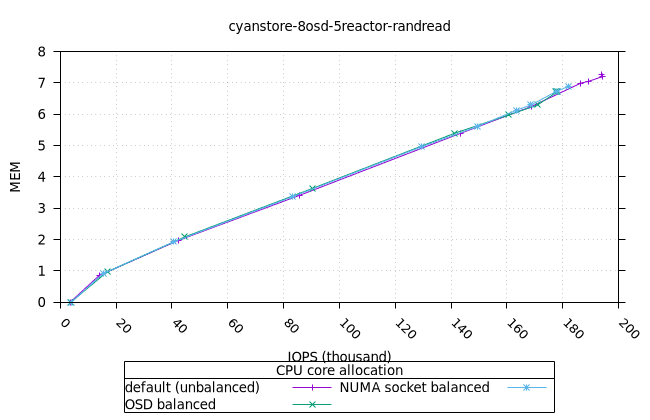
사이언스토어¶
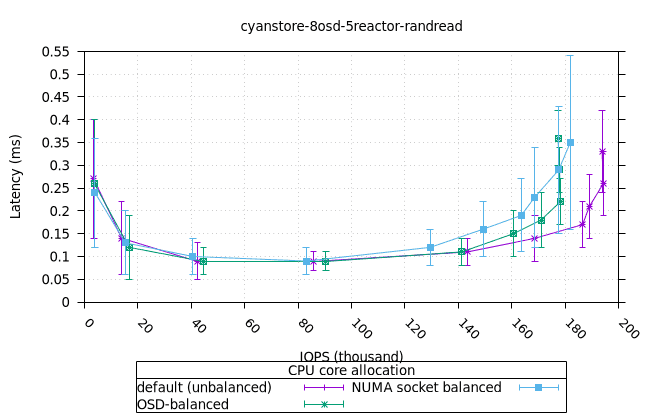
먼저 OSD 프로세스의 CPU와 MEM 활용도를 보여드리고, 그다음 FIO 클라이언트를 보여드리겠습니다.
- 기본 CPU 할당 전략은 균형 잡힌 CPU 할당 전략보다 메모리 사용률이 더 높다는 점이 흥미롭지만, 이는 Cyanstore에만 해당되므로 우려할 만한 문제는 아닙니다.
| OSD CPU | OSD 메모리 |
|---|---|
 |  |
| FIO CPU | 피오 멤 |
|---|---|
 |  |
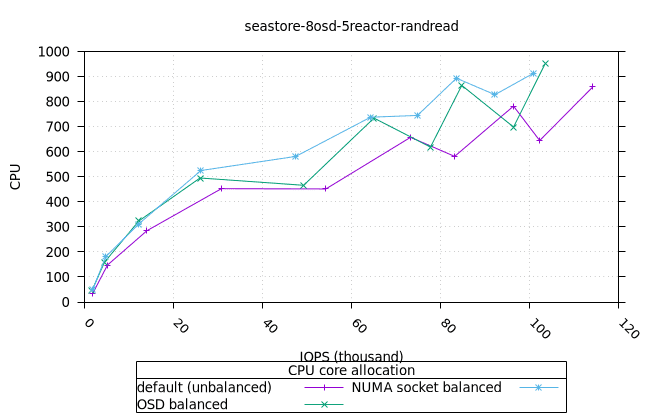
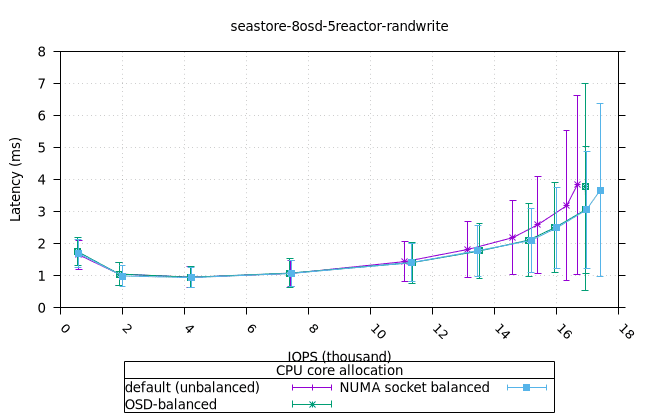
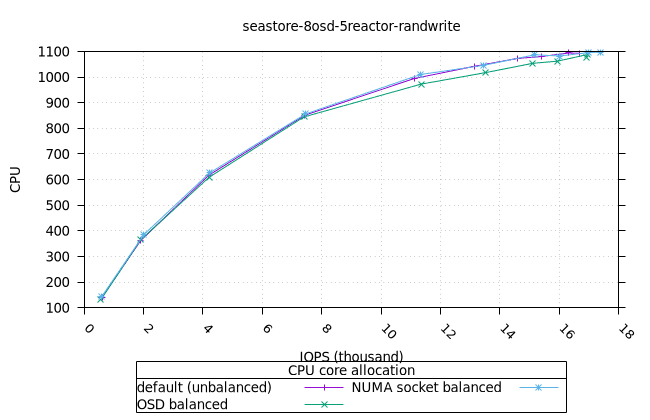
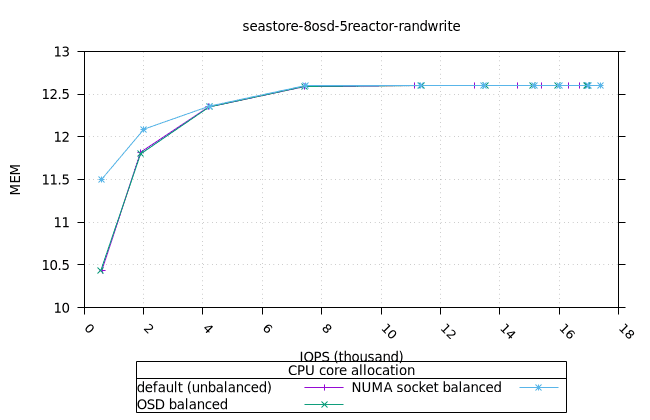
씨스토어¶
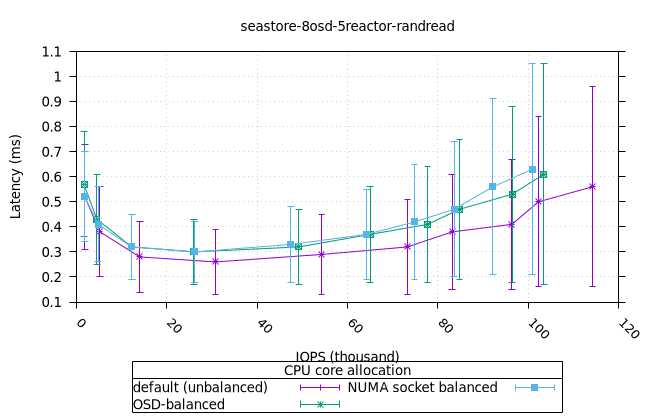
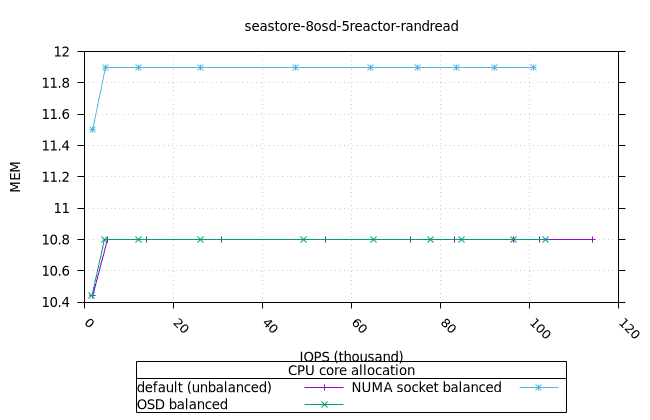
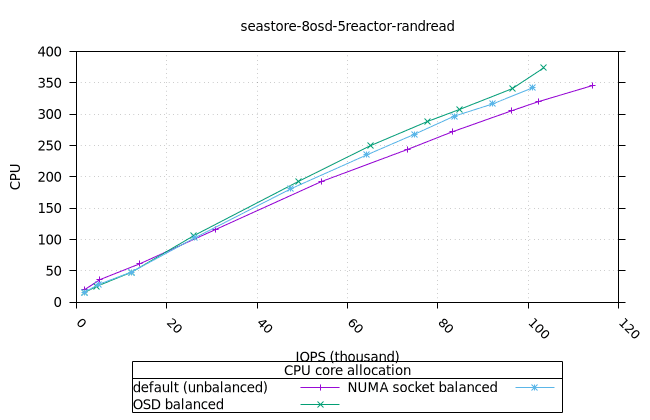
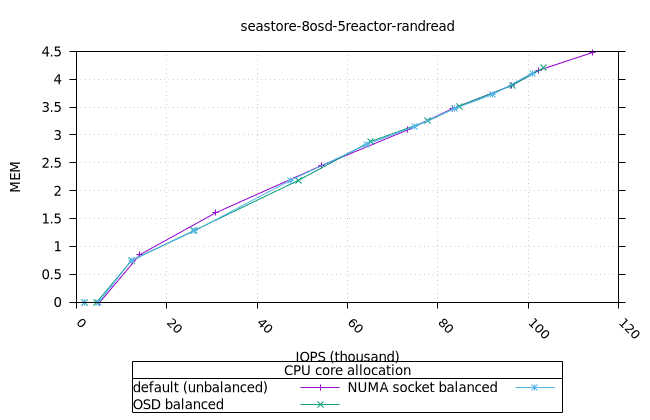
- 모든 iodepth에서 OSD 프로세스의 메모리 사용량이 일정하게 유지되는 것은 좋은 신호입니다. NUMA 소켓 전략은 다른 전략보다 0.6%만 더 높았는데, 이는 우려할 만한 수준은 아닙니다.
| OSD CPU | OSD 메모리 |
|---|---|
 |  |
| FIO CPU | 피오 멤 |
|---|---|
 |  |
블루스토어¶
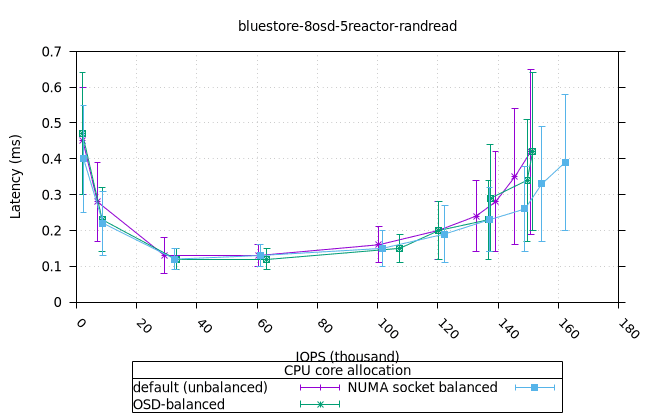
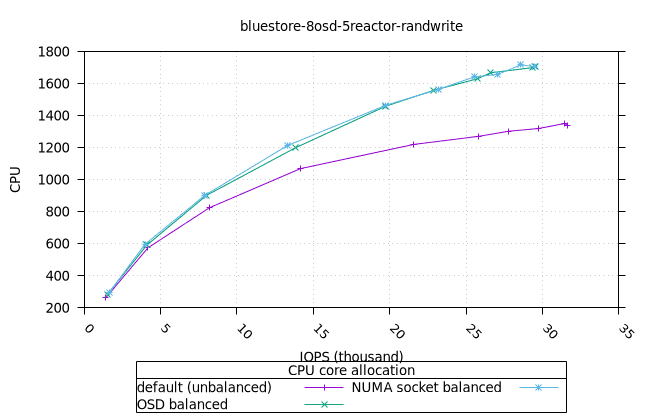
- 흥미롭게도, NUMA 소켓 균형 CPU 할당 전략은 Bluestore의 다른 CPU 할당 전략보다 약간 더 나은 것으로 나타났습니다.
| OSD CPU | OSD 메모리 |
|---|---|
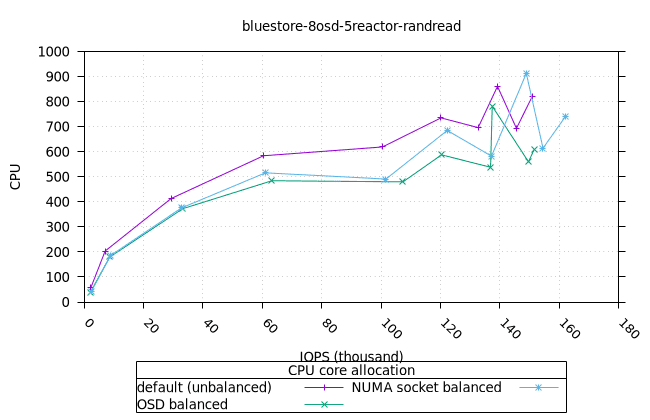 | 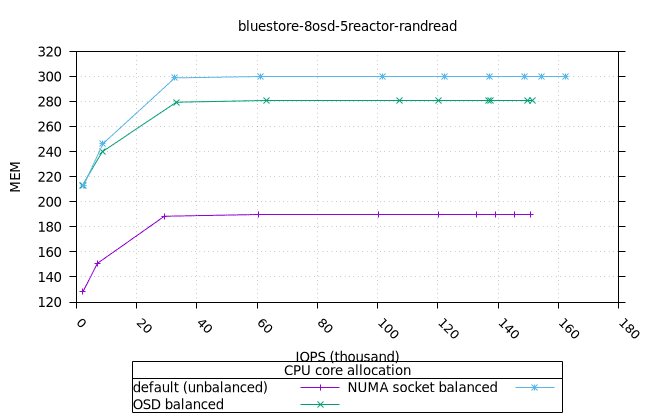 |
| FIO CPU | 피오 멤 |
|---|---|
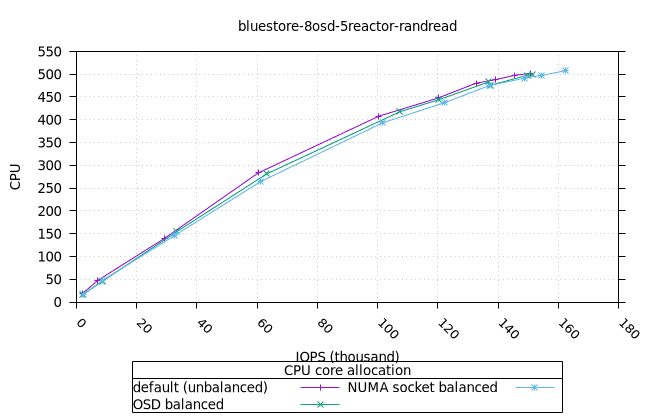 | 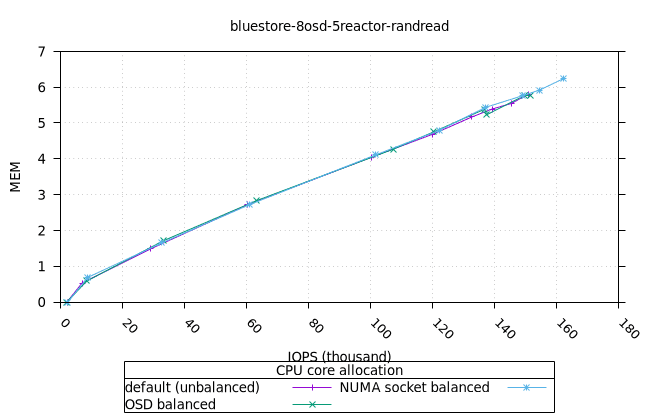 |
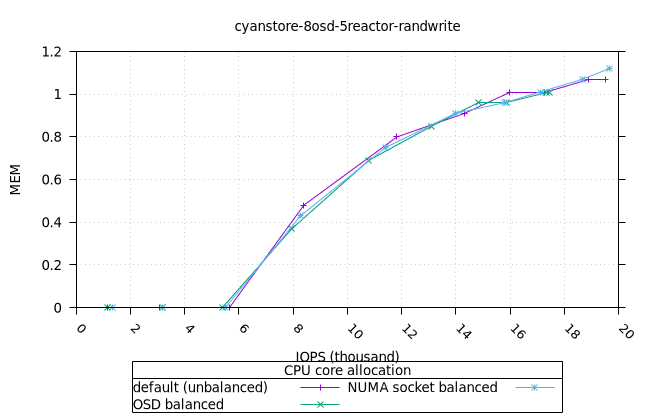
무작위 4K 쓰기¶
- 리소스 사용률 그래프가 완만한 기울기로 매끄럽게 표현된다는 점에서 이는 만족스러운 작업입니다. NUMA 소켓 전략은 Cyanstore와 Seastore의 경우 다른 전략보다 약간 유리하지만, 기본 전략은 Bluestore의 경우 약간 유리합니다.
사이언스토어¶
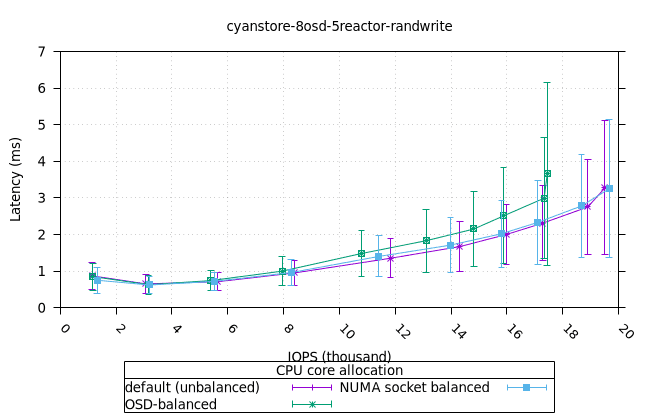
| OSD CPU | OSD 메모리 |
|---|---|
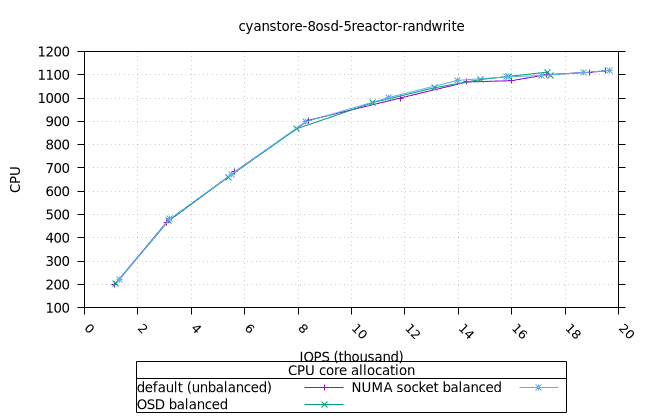 | 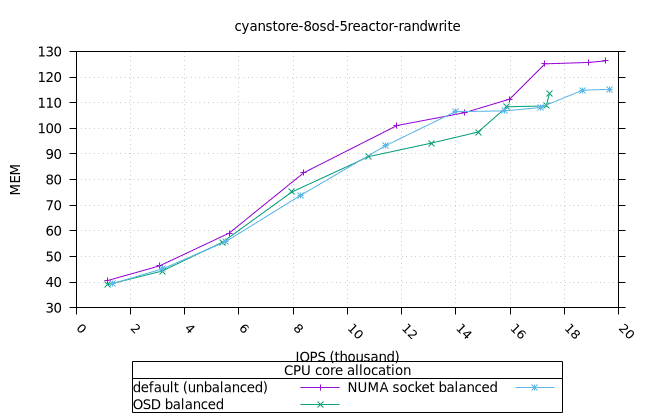 |
| FIO CPU | 피오 멤 |
|---|---|
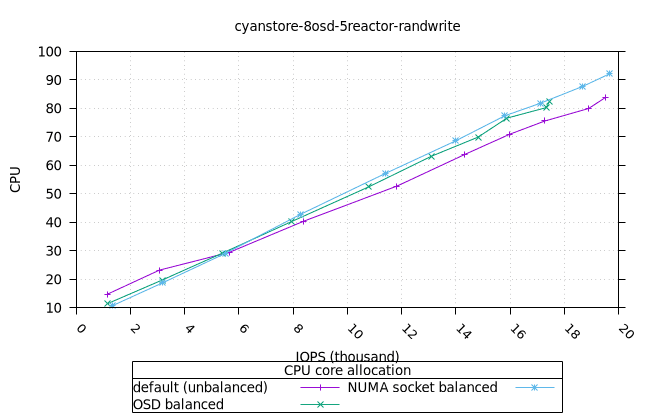 |  |
씨스토어¶
| OSD CPU | OSD 메모리 |
|---|---|
 |  |
| FIO CPU | 피오 멤 |
|---|---|
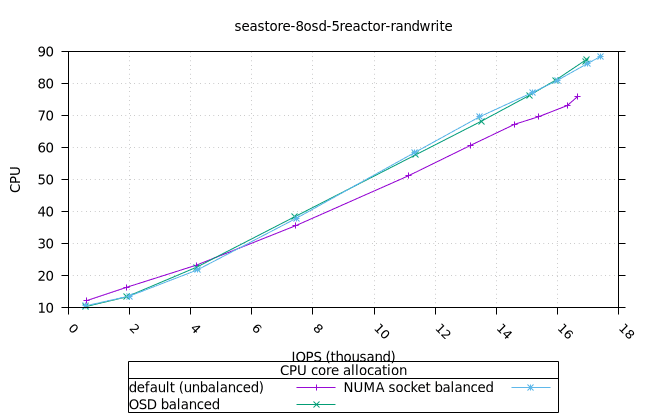 | 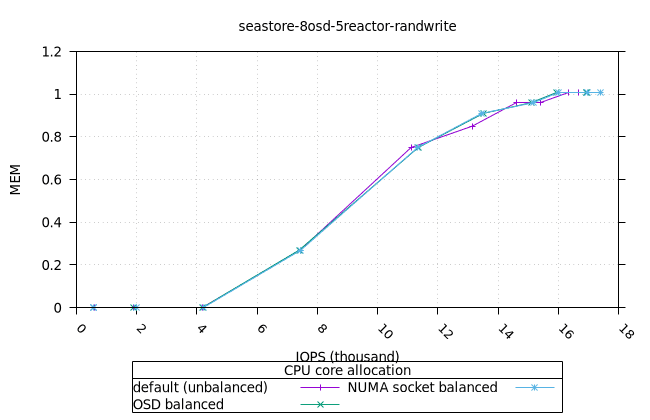 |
블루스토어¶
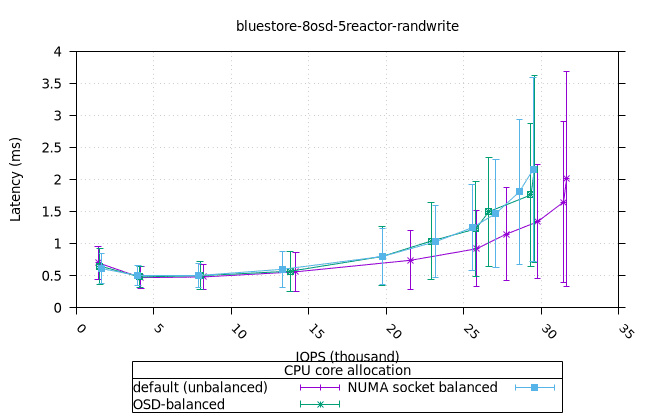
| OSD CPU | OSD 메모리 |
|---|---|
 | 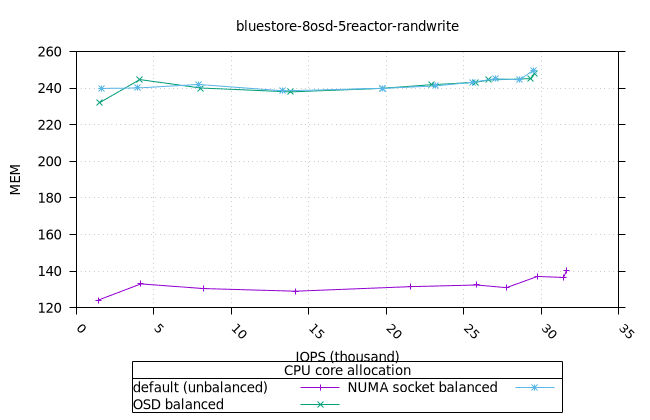 |
| FIO CPU | 피오 멤 |
|---|---|
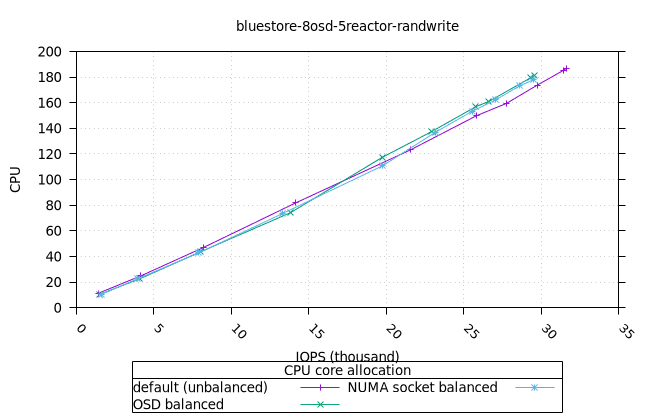 | 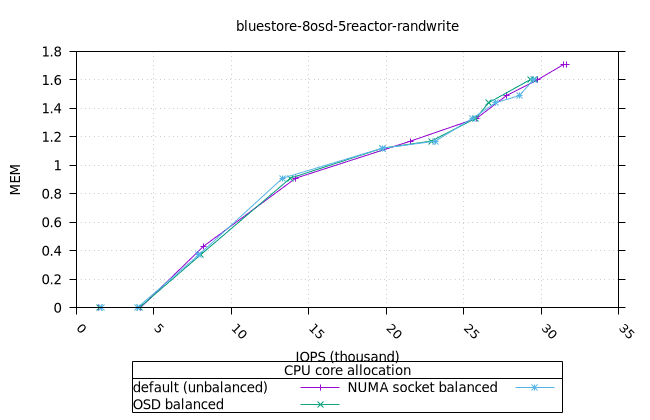 |
순차적 64K 읽기¶
- 이러한 워크로드의 특성상 CPU 사용률이 급증하는 것으로 보입니다. 이는 세 가지 CPU 할당 전략과 세 가지 객체 스토리지 백엔드에서 모두 동일하게 나타납니다. 추가 조사가 필요합니다.
사이언스토어¶
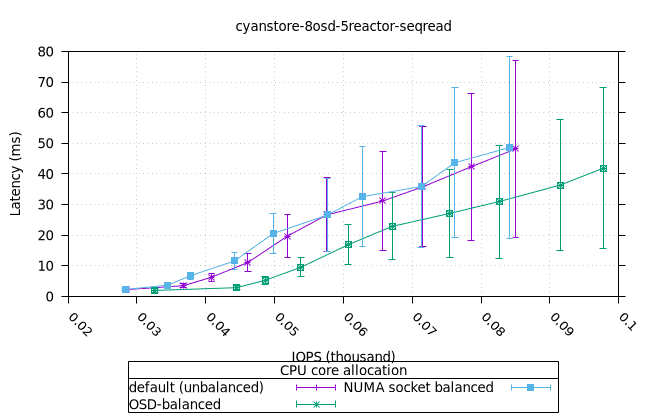
| OSD CPU | OSD 메모리 |
|---|---|
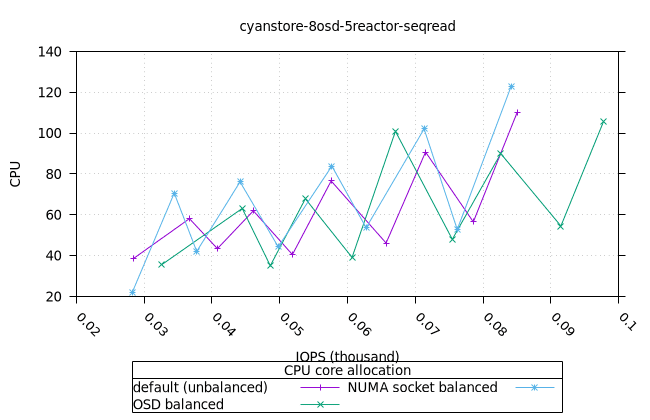 | 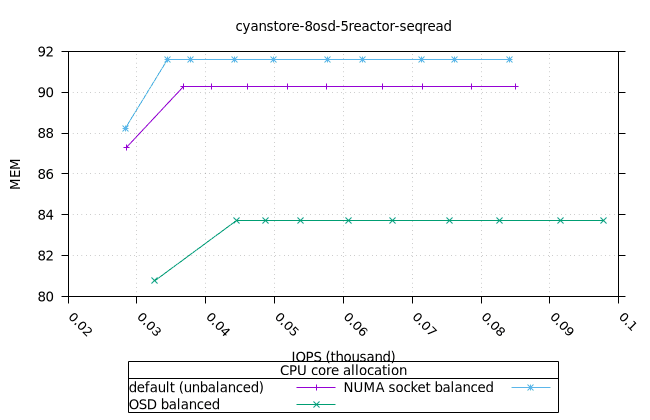 |
| FIO CPU | 피오 멤 |
|---|---|
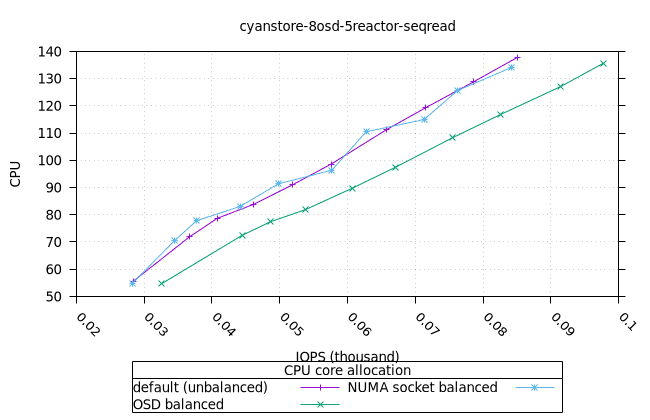 |  |
씨스토어¶
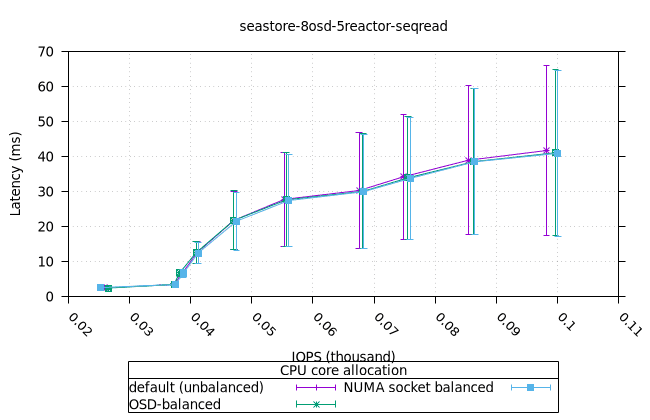
| OSD CPU | OSD 메모리 |
|---|---|
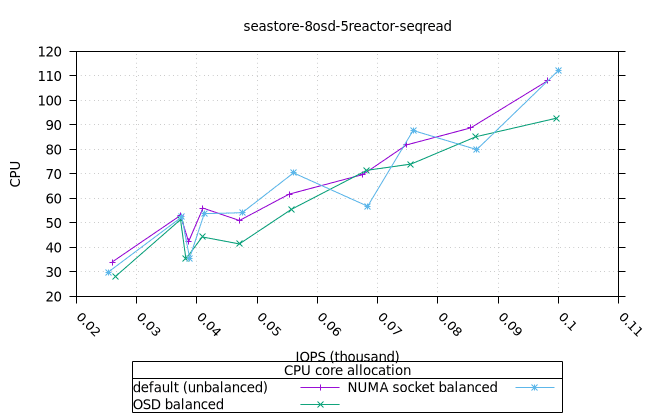 | 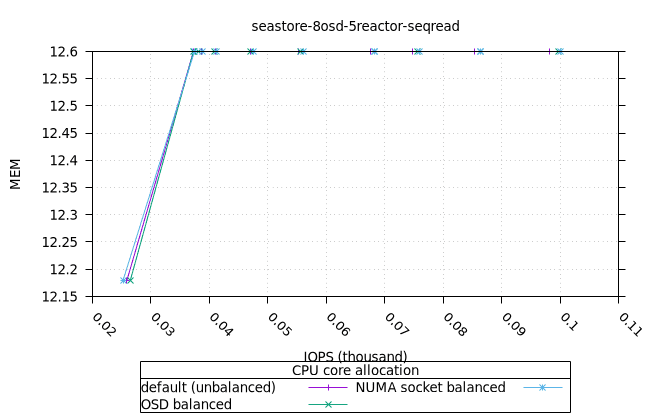 |
| FIO CPU | 피오 멤 |
|---|---|
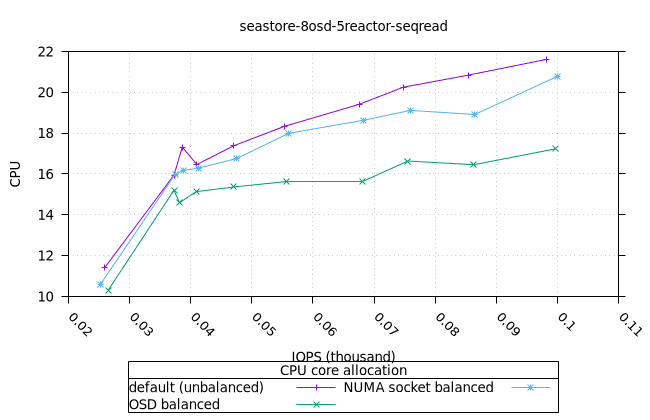 |  |
블루스토어¶

| OSD CPU | OSD 메모리 |
|---|---|
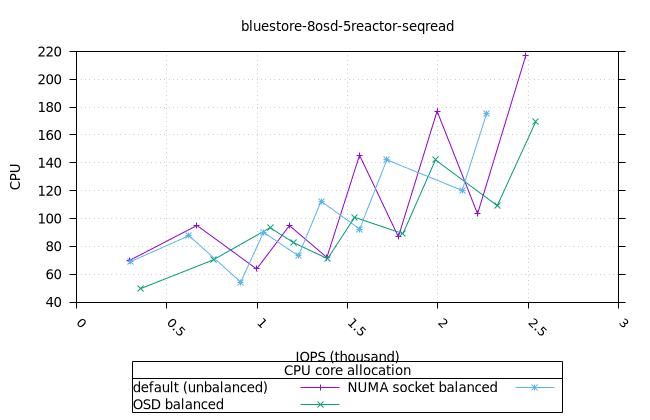 | 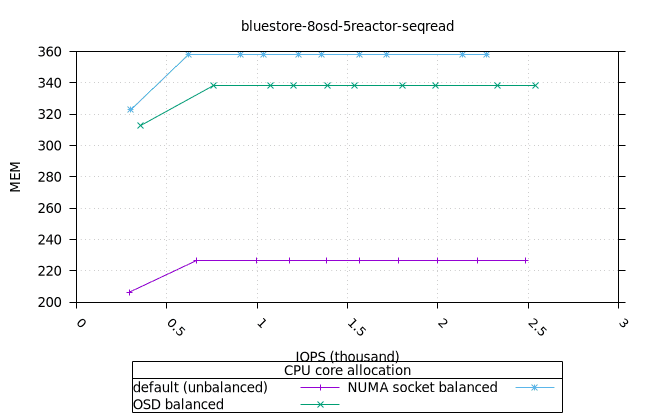 |
| FIO CPU | 피오 멤 |
|---|---|
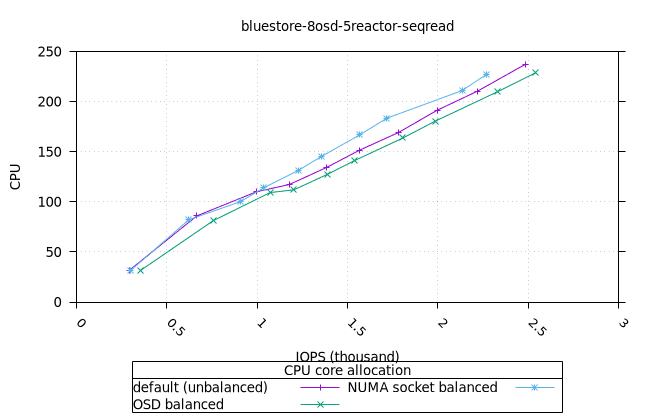 | 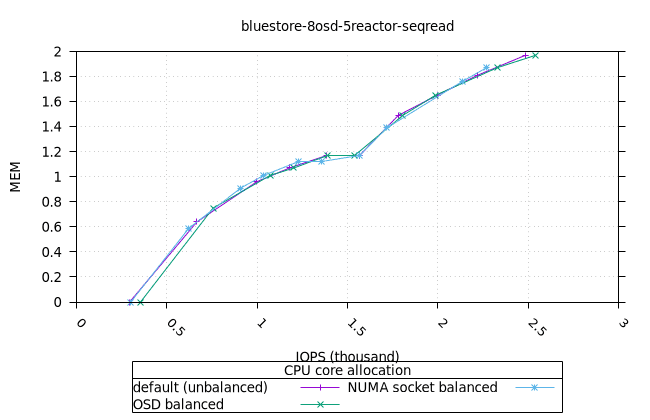 |
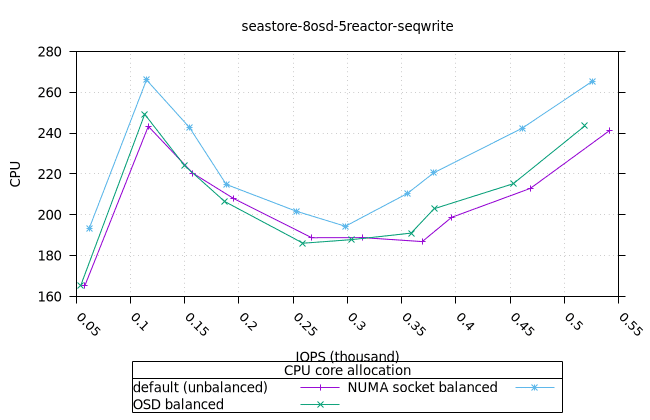
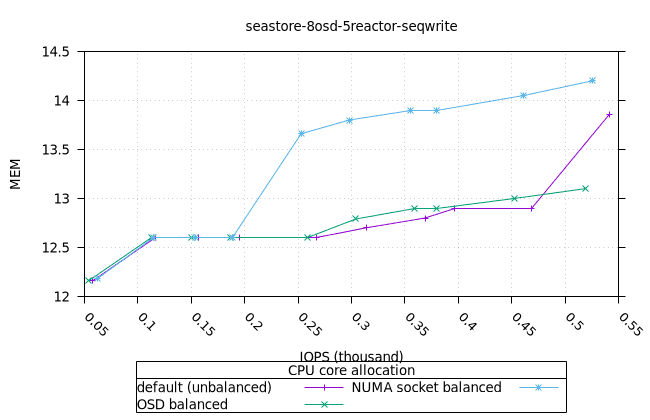
순차적 64K 쓰기¶
- 세 가지 객체 저장소 백엔드에서 세 가지 CPU 할당 전략에 대한 CPU 사용률의 초기 급증을 설명하기는 어렵습니다. 확인을 위해 이 테스트의 로컬 버전을 실행해야 할 수도 있습니다.
사이언스토어¶
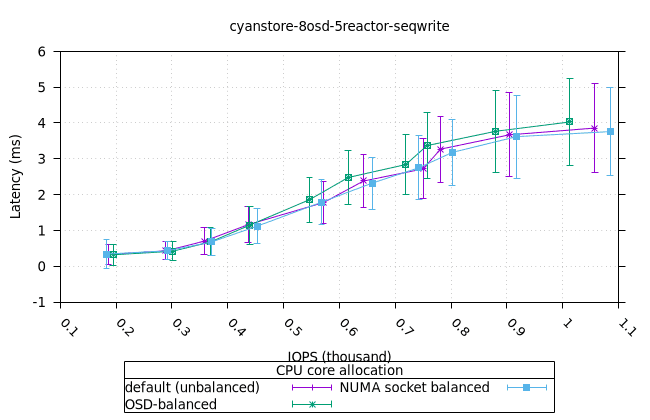
| OSD CPU | OSD 메모리 |
|---|---|
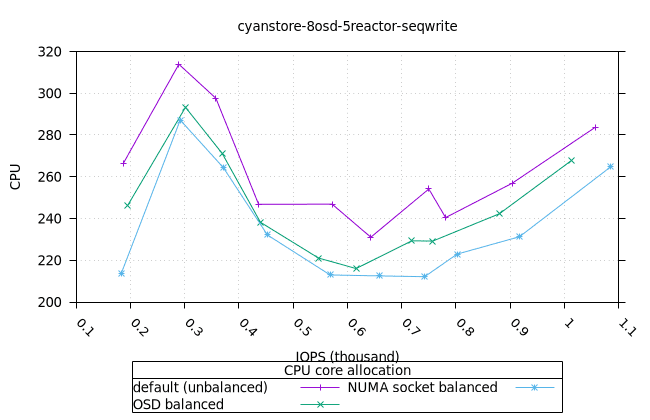 | 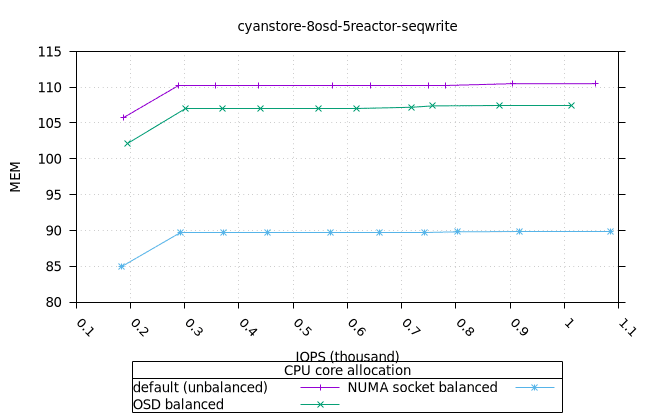 |
| FIO CPU | 피오 멤 |
|---|---|
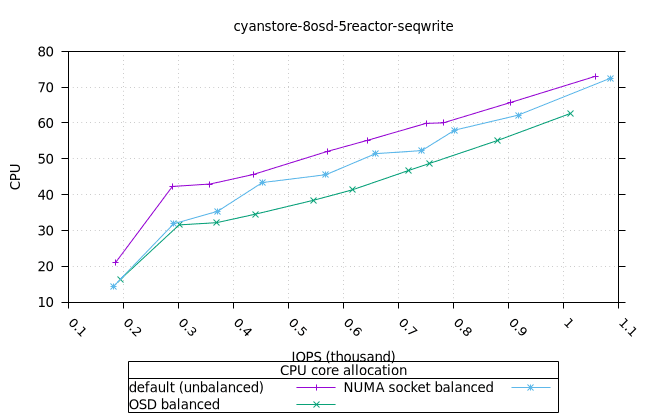 | 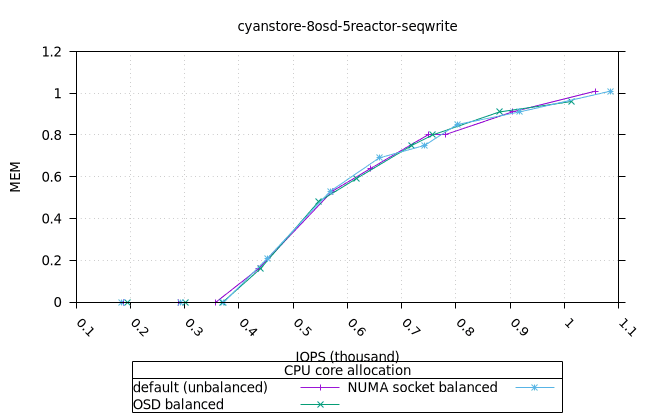 |
씨스토어¶
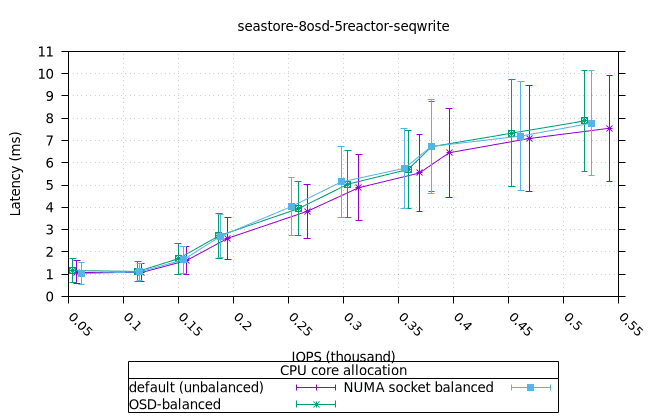
| OSD CPU | OSD 메모리 |
|---|---|
 |  |
| FIO CPU | 피오 멤 |
|---|---|
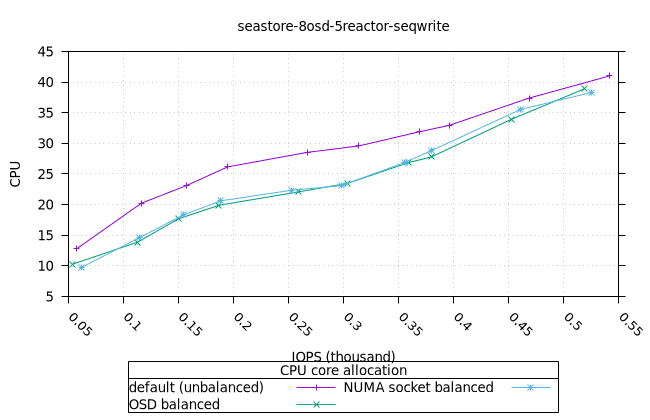 | 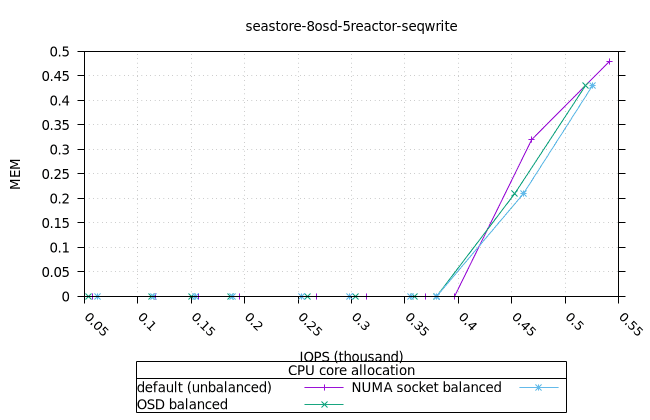 |
블루스토어¶
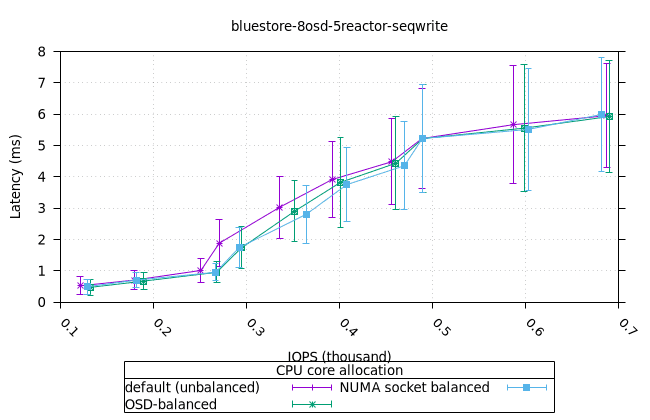
| OSD CPU | OSD 메모리 |
|---|---|
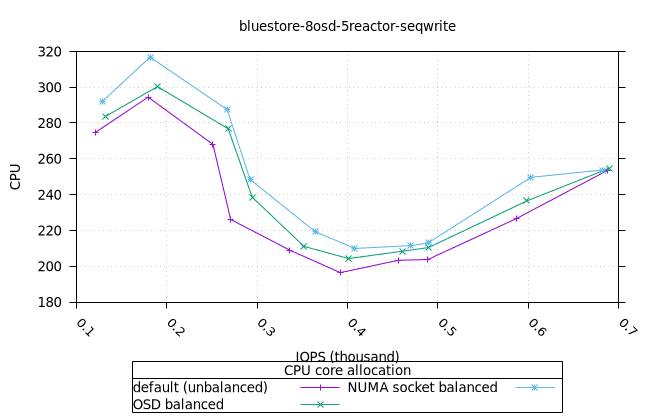 | 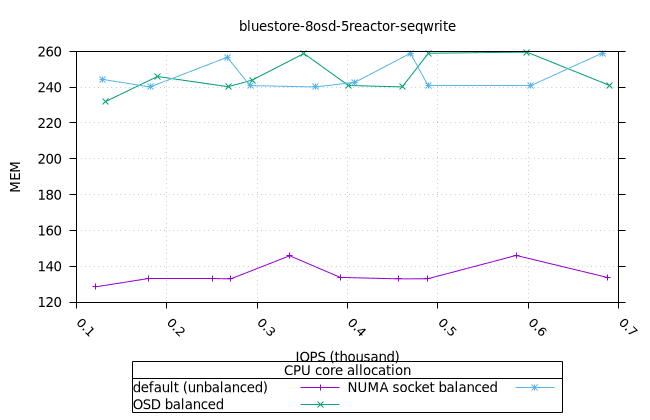 |
| FIO CPU | 피오 멤 |
|---|---|
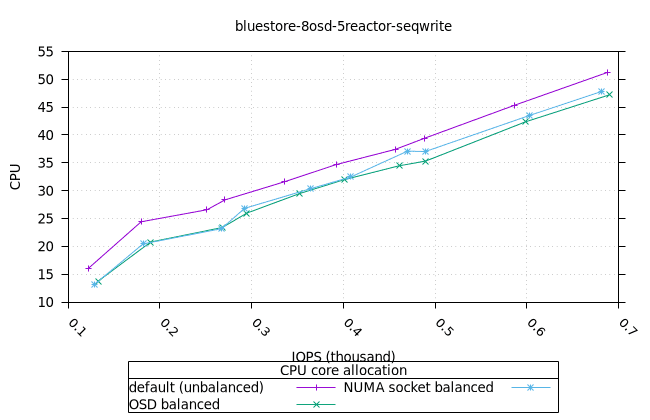 | 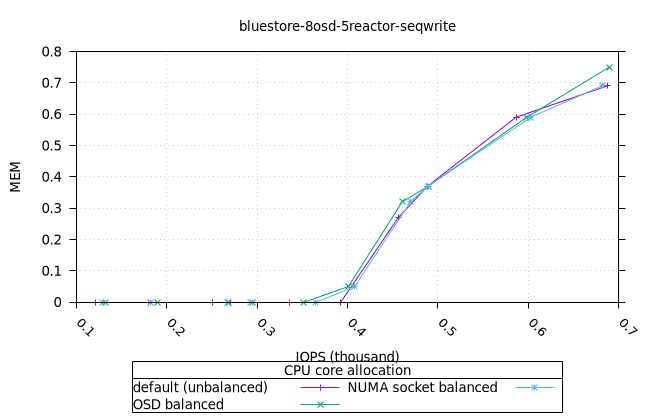 |
3개의 객체 스토리지 백엔드에 걸친 기본 CPU 할당 전략 비교¶
세 가지 스토리지 백엔드에서 기본 CPU 할당 전략을 간략하게 비교합니다. 현재 현장/커뮤니티에서 사용되고 있는 기본 CPU 할당 전략을 선택했습니다.
- Cyanstore는 랜덤 읽기 4k와 순차 쓰기 64k에서 더 높은 성능을 보이는데, 이는 메모리 접근에 지연 시간이 없기 때문에 당연한 일입니다.
- Bluestore가 4k 랜덤 쓰기 성능에서 더 높은 성능을 보이는데, 이는 다소 놀랍습니다. Bluestore가 작은 블록 쓰기에서 더 효율적인 이유를 파악하기 위해 추가 조사가 필요합니다.
- 순차적인 64K 읽기의 경우, Bluestore가 순수 Reactor 객체 백엔드에 비해 훨씬 앞서 있는 것 또한 놀랍습니다. 오류가 있는지 확인하기 위해 이 부분을 자세히 살펴볼 필요가 있습니다.
| 무작위 읽기 4K | 랜덤 쓰기 4k |
|---|---|
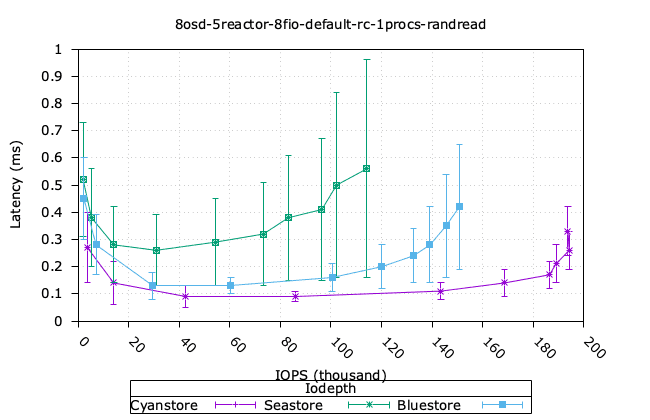 | 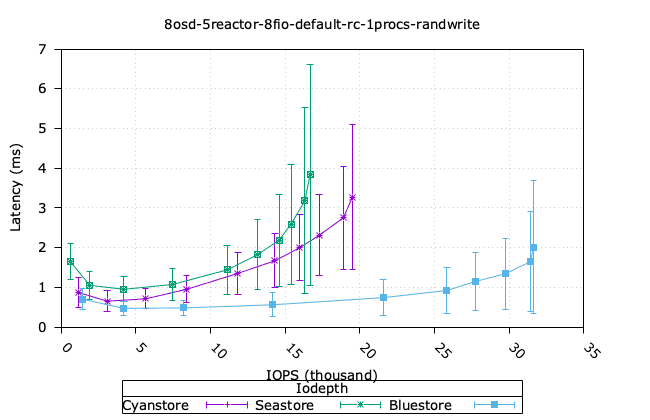 |
| 시퀀스 읽기 64K | Seq Write 64k |
|---|---|
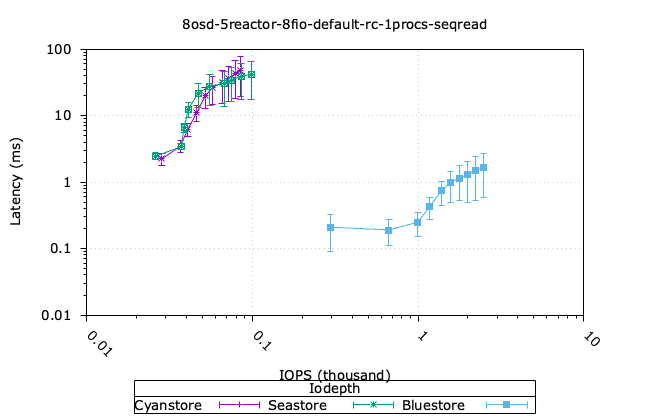 | 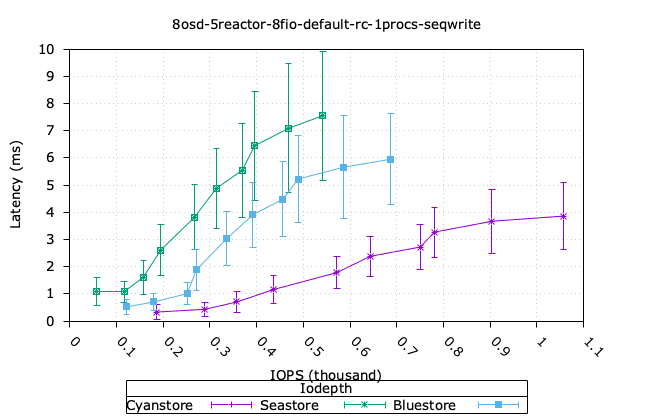 |
결론¶
이 블로그 게시물에서는 세 가지 객체 스토리지 백엔드에서 세 가지 CPU 할당 전략에 대한 성능 결과를 보여드렸습니다. 흥미로운 점은 어떤 CPU 할당 전략도 기존 기본 전략보다 크게 우수한 성능을 보이지 않았다는 점입니다. 엄격한 방법론을 유지하기 위해 모든 테스트에 동일한 Ceph 빌드(위에 언급된 커밋 해시 포함)를 사용하여 각 단계에서 필요한 단일 매개변수만 수정되도록 했습니다. 따라서 이 결과는 아직 최신 Seastore 개발 진행 상황을 나타내는 것은 아닙니다.
이 글은 제 첫 블로그 글인데, 도움이 되셨기를 바랍니다. 이렇게 활기찬 커뮤니티에 합류한 첫 해를 보내며 Ceph 커뮤니티의 지원과 지도에 진심으로 감사드립니다. 특히 Matan Breizman, Yingxin Cheng, Aishwarya Mathuria, Josh Durgin, Neha Ojha, Bill Scales에게 감사드립니다. 다음 블로그 글에서는 Crimson OSD의 성능 지표 내부를 심층적으로 살펴보겠습니다. 주요 코드 랜드마크에 플레임그래프를 적용하고, 기존 도구를 활용하여 구성 요소별 지연 시간을 파악해 보겠습니다.
