출처: https://developers.redhat.com/articles/2025/08/26/vm-tuning-case-study-balancing-power-and-performance-amd-processors
튜닝 관련해서 한번 읽어볼만한 글인 것 같아 Google 번역하고 살짝 교정해봤습니다.
새 서버를 구축하는 동안 베어 메탈 환경에서 실행되는 워크로드와 동일 머신의 가상 머신(VM)에서 실행되는 워크로드 간에 극명한 성능 차이가 있음을 발견했습니다. 심층적인 조사 결과, 몇 가지 튜닝 변경 사항을 발견했는데, 그중 일부는 명확하고 일부는 놀라웠으며, 그 결과 성능 차이가 크게 줄었습니다.
이 글에서는 시스템 프로필 조정, 최신 CPU 스케일링 드라이버 활성화부터 네트워크 성능 향상, 유휴 전력 동작 이해까지 가장 효과적인 최적화 방법을 살펴보겠습니다. 작고 구체적인 변화가 어떻게 큰 효과를 가져올 수 있는지, 그리고 성능 튜닝에 대한 일부 가정이 실제로 적용되지 않는 이유를 알아보겠습니다.
워크로드
저는 업무상 GNU project debugger(GDB)를 자주 빌드하고 테스트하기 때문에 GDB가 빠르게 빌드되는 것이 중요합니다. GDB 빌드에 사용되는 명령은 다음과 같습니다.
mkdir -p /path/to/build/directory ; cd /path/to/build/directory /path/to/gdb/sources/configure time make -j32
make 명령 실행 시간을 측정하는 것은 관례가 아니지만 , 이 연구에서는 워크로드의 핵심 부분에 대한 시간을 측정했습니다. GDB 빌드 워크로드의 시간을 측정한 각 시나리오에 대해 최소 5회 이상 워크로드를 실행하고, 실행 전에 빌드 디렉터리를 삭제했습니다. 5회 실행 후에도 표준 편차가 비교적 높게 유지되는 경우, 표준 오차(즉, 오차 범위)를 줄이기 위해 테스트를 몇 번 더 실행하여 더 정확한 평균을 도출했습니다.
노트: 이
make옵션-j32(병렬 작업 수 설정)은 모든 머신에 적합하지 않습니다. 일반적으로-j머신의 코어 수와 동일하게 설정하는 것이 좋습니다. 저는 일반적으로-j$(nproc)옵션을 사용하는데, 이 작업을 수행합니다. 하지만 이 성능 연구에서는 호스트와 VM 모두 최대 32개의 프로세스만 병렬로 실행하기를 원했기 때문에 명시적으로 32로 지정했습니다.
GDB 프로젝트의 Makefiles에 익숙하지 않은 분들을 위해 설명드리자면, 프로젝트의 각 하위 디렉터리는 자체 configure스크립트를 실행한 후, (-j 스위치를 사용했기 때문에 병렬로 ) 다양한 컴파일러나 기타 도구를 실행하여 소스 코드를 오브젝트 코드로 변환합니다. 그 후, 오브젝트 파일을 실행 파일이나 라이브러리로 변환하는 링크 단계가 이어집니다. 종속성이 없는 경우 다양한 configure 스크립트 실행이 병렬로 진행될 수 있지만, 이러한 경우 빌드 프로세스가 직렬화되는 경향이 있습니다.
마찬가지로, 다양한 객체를 결합하는 단계(예: 링커 실행)에 도달하면 빌드 프로세스는 모든 종속 컴파일 단계가 완료될 때까지 기다려야 합니다. top유형 도구를 사용하여 빌드를 모니터링할 때 32개의 코어가 사용되는 경우는 드뭅니다. 가끔 발생하지만, 빌드 프로세스 중 몇 번만 발생합니다.
네트워크 병목 현상을 배제하기 위해 iperf3로 VM과 호스트, 그리고 VM과 다른 머신 간의 네트워크 성능 테스트도 진행했습니다. GDB 빌드 시간에는 거의 영향을 미치지 않았지만 네트워크 성능을 크게 향상시킨 한 가지 최적화 iperf3 결과에 대해 설명하겠습니다. 각 iperf3 워크로드를 최소 5회 이상 실행했지만, 표준 편차가 너무 커서 데이터를 제시할 때 오차 막대를 사용했습니다.
시스템 구성 및 테스트 환경
이 연구에 사용된 호스트 머신은 AMD EPYC 9354P로, simultaneous multithreading (SMT) 기능을 갖춘 32코어 프로세서로, Linux에서 64개의 논리 코어로 작동합니다. GDB 빌드 워크로드와 게스트 VM을 스왑 없이 실행하기에 충분한 메모리를 제공하며, OS가 빌드 프로세스 중에 사용되는 모든 파일을 캐시할 수 있을 만큼 충분히 큽니다.
가상 머신은 32개의 가상 CPU, 16GiB RAM, 그리고 80GiB 이상의 디스크 공간으로 구성되었으며, 호스트의 OpenZFS(ZFS의 파생 버전) 볼륨을 기반으로 합니다. 디스크 및 네트워크 I/O는 고성능 가상화를 위한 virtio 드라이버를 사용합니다.
GDB 빌드의 경우, 소스 및 빌드 디렉터리는 모두 10Gbps 이더넷 링크로 연결된 별도의 머신에서 Network Filesystem Protocol (NFS)을 통해 마운트되었습니다. 호스트의 로컬 스토리지를 사용한 추가 테스트 결과, NFS가 빌드 성능에 미치는 영향은 미미한 것으로 나타났습니다. I/O가 많은 워크로드라는 점을 고려하면 놀라운 결과였습니다.
하지만 10Gbps 네트워크 대역폭과 최적화된 OpenZFS 스토리지를 갖춘 I/O 서브시스템은 이미 충분했습니다. 이는 워크로드가 이제 I/O가 아닌 CPU와 메모리에 집중되어 있음을 시사하며, 네트워크 및 스토리지 변경이 거의 효과가 없었던 이유를 설명합니다.
호스트와 게스트 시스템 모두 Fedora 42를 실행했기 때문에 성능 차이는 소프트웨어 차이가 아니라 튜닝으로 인한 것이라고 확신할 수 있었습니다.
호스트 VM 성능에 대한 튜닝의 누적 영향
베어 메탈 환경에서는 워크로드 평균 82.4초, VM은 130.6초가 소요되어 48초(58%)의 차이가 발생했습니다. 비교를 위해, 부하가 높은 AMD Ryzen Threadripper 7970X는 워크로드를 54.4초 만에 완료했고, 호스팅된 VM은 64.9초가 소요되어 10.5초(19%)의 차이가 훨씬 작았습니다.
여러 차례의 튜닝 최적화 후, EPYC 호스트는 워크로드를 67.6초 만에 완료했고, VM은 77.8초 만에 완료했습니다. 이는 10.2초(15%)의 차이입니다. 더욱 놀라운 점은 튜닝된 VM이 기존 베어 메탈 호스트 구성(82.4초)보다 더 빠르게 실행된다는 것입니다. 이는 4.6초의 차이입니다. 그림 1을 참조하십시오.
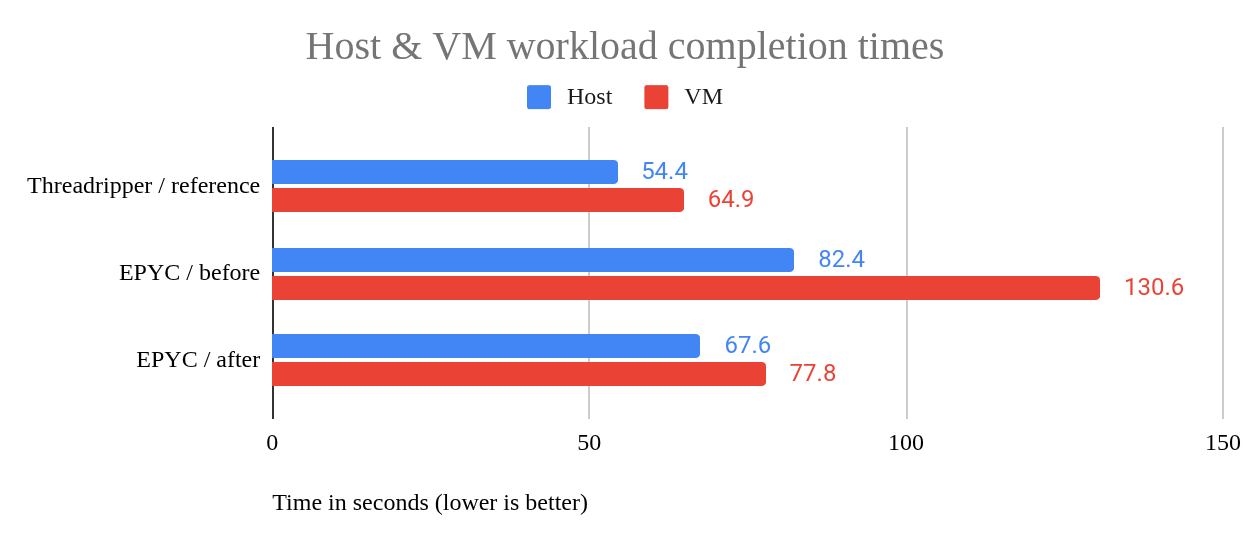
그림 1: 호스트와 VM 워크로드 완료 시간 비교
튜닝 과정에서 모든 변경 사항을 추적했지만, 가장 큰 성능 향상을 가져온 최적화부터 시작하여 그 영향을 기준으로 제시하기로 했습니다. 이러한 접근 방식은 성능 튜닝의 현실을 반영합니다. 가장 큰 효과를 내는 개선 사항이 항상 먼저 시도된 것은 아니며, 일부 변경 사항은 효과가 거의 없거나 전혀 없습니다.
가장 큰 이점: 호스트의 튜닝 프로필 변경
호스트 tuned프로필을 balanced에서 virtual-host 또는 throughput-performance와 같은 다른 프로필로 변경했더니 VM 성능이 무려 45%나 향상되었습니다. 다른 테스트를 통해 이러한 결과가 항상 그런 것은 아니라는 것을 알게 되었습니다. balanced 프로필은 일반적으로 좋은 성능을 제공하기 때문입니다. 실제로 앞서 언급한 NFS 서버라는 한 머신에서 해당 머신에 호스팅된 VM의 워크로드를 테스트한 결과, balanced 프로필의 성능이 throughput-performance 프로필보다 약간 더 좋 습니다 .
이 tuned-adm list명령은 각 기능에 대한 간략한 설명과 함께 프로필을 표시합니다. VM에서 워크로드를 실행하고 있으므로 당연히 사용할 프로필은 해당 virtual-host프로필이며, 실제로 제가 가장 먼저 시도해 본 프로필이기도 합니다. 사용 가능한 대부분의 프로필을 사용하여 초기 테스트를 수행한 후, 벤치마킹을 위해 아래 목록을 선택했습니다. tuned-adm list 명령에서 제공하는 프로필 설명은 이탤릭체로 표시됩니다.
balanced: 일반적이고 특수화되지 않은 튜닝된 프로필 입니다. 기본 프로필입니다.balanced-performance: 구성 파일 설정을 실험해 볼 수 있는 사용자 지정 프로필입니다 . 몇 가지 수정 사항을 제외하면tuned거의 동일합니다 .balancedthroughput-performance: 다양한 일반 서버 워크로드에서 탁월한 성능을 제공하는 광범위하게 적용 가능한 튜닝입니다. 테스트 결과, 이는 탁월한 성능 프로필이며, 놀랍게도 유휴 전력 사용량도 낮습니다.virtual-host: KVM 게스트 실행에 최적화합니다. VM 실행에는 당연한 선택처럼 보였지만, 심각한 단점을 발견했습니다.powersave: 저전력 소비에 최적화합니다. 이 튜닝 과정을 시작할 때, 저는 EPYC 플랫폼의balanced프로파일이 사실상powersave와 동일할 것이라고 가정했습니다 . 테스트 결과, 성능 저하가 거의 비슷했으며,powersave는 단지 5.5%만 느렸습니다.balanced프로파일의 구성 파일에는schedutil와ondemand가버너(governor)를 모두 사용할 수 없는 경우balanced프로파일의 가버너가powersave를 사용하도록 설정되어 있는데, 아마도 이것이 처음에 성능이 매우 나빴던 이유 중 하나일 것입니다.
여러 AMD 컴퓨터에서 해당 tuned-adm verify명령은 balanced 프로필 오류를 보고하며, 로그 파일을 통해 cpufreq_conservative 모듈이 로드되지 않았음을 나타냅니다. 알고 보니 해당 모듈은 로드 가능한 모듈이 아니라 커널에 내장된 모듈이었습니다! 즉, 오류는 구성 요소 누락이 아니라 프로필의 예상 값과 시스템의 CPU 스케일링 구성 간의 불일치로 인해 발생합니다.
검증 실패를 해결하고 유휴 전력 소비를 줄이면서 더 나은 성능을 낼 수 있는 가능성을 모색하기 위해 사용자 지정 balanced-performance 프로필을 만들었습니다. 여러 설정을 시도해 보았지만, 결국에는 두 가지 기능만 수행합니다.
cpufreq_conservative모듈에 대한balanced프로필 참조를 제거합니다 .energy_performance_preference설정이performance로 변경되었습니다 . 후자의 설정에 대해서는amd-pstate토론에서 더 자세히 논의하겠습니다.
amd-pstate 드라이버 로 전환한 후에도 balanced-performance 프로파일은 원래 balanced 프로파일과 거의 동일한 성능을 보였습니다 . 그림 2의 차트는 두 프로파일 사이에 오차 범위 내에서 약간의 차이가 있음을 보여줍니다.
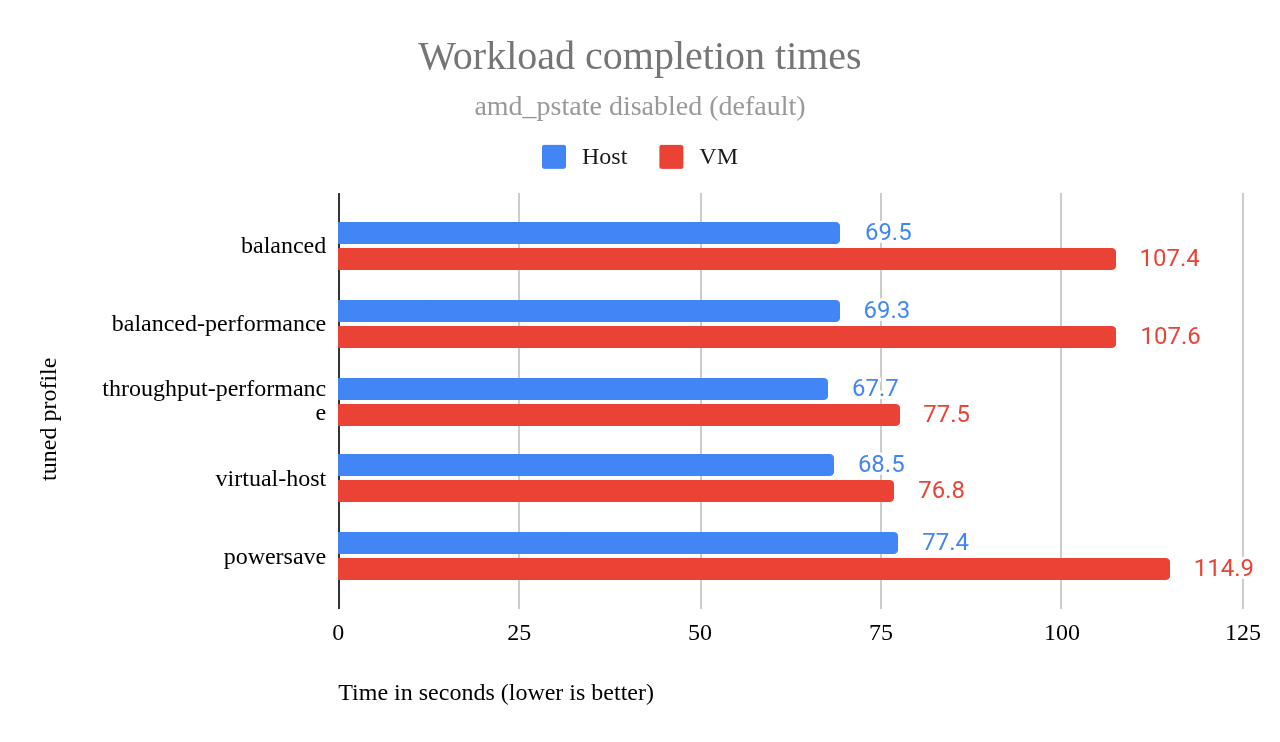
그림 2: amd_pstate가 비활성화된 경우(기본값) 작업 완료 시간.
이 차트는 해당 virtual-host프로필이 강력한 VM 성능을 제공한다는 것을 보여줍니다. 그렇다면 이를 도입해야 할까요?
각 작업 부하 테스트(일반적으로 5회, 프로필당 최대 16회)를 수행한 후, 서버의 전원 공급 장치에 연결된 TP-Link Tapo P115 스마트 플러그를 사용하여 유휴 전력 소비량을 측정했습니다. 2분 후, 관찰된 가장 낮은 전력 값을 기록했습니다. 이 기간 동안 측정값은 최대 20와트까지 변동했는데, 이는 아마도 백그라운드 시스템 활동 때문일 것입니다.
유휴 상태에서 virtual-host 프로필은 balanced 프로필보다 89와트 , throughput-performance 프로필보다 75와트 더 많은 전력을 소모하는 것으로 나타났습니다. 이는 유휴 상태에서 가끔씩 나타나는 20와트 변동으로는 설명할 수 없는 상당한 차이입니다.
더욱 우려스러운 점은 virtual-host에서 throughput-performance로 전환했을 때 유휴 전력 사용량이 줄어들지 않고 virtual-host에서 관찰된 더 높은 수준으로 유지되었다는 점입니다.
추가 테스트 결과, tuned 프로필의 실제 유휴 전력 소비량을 안정적으로 측정하려면 프로필 변경 사이에 재부팅이 필요하다는 것을 확인했습니다. 이는 CPU 주파수 조정 및 전력 관리에 영향을 줄 수 있는 일부 튜닝 설정이 tuned-adm 단독으로는 완전히 복원되지 않기 때문입니다 .
그림 3의 차트는 amd-pstate의 다양한 작동 모드(off, passive, active, guided)를 포함하여 각 프로필의 유휴 전력 사용량을 보여줍니다.
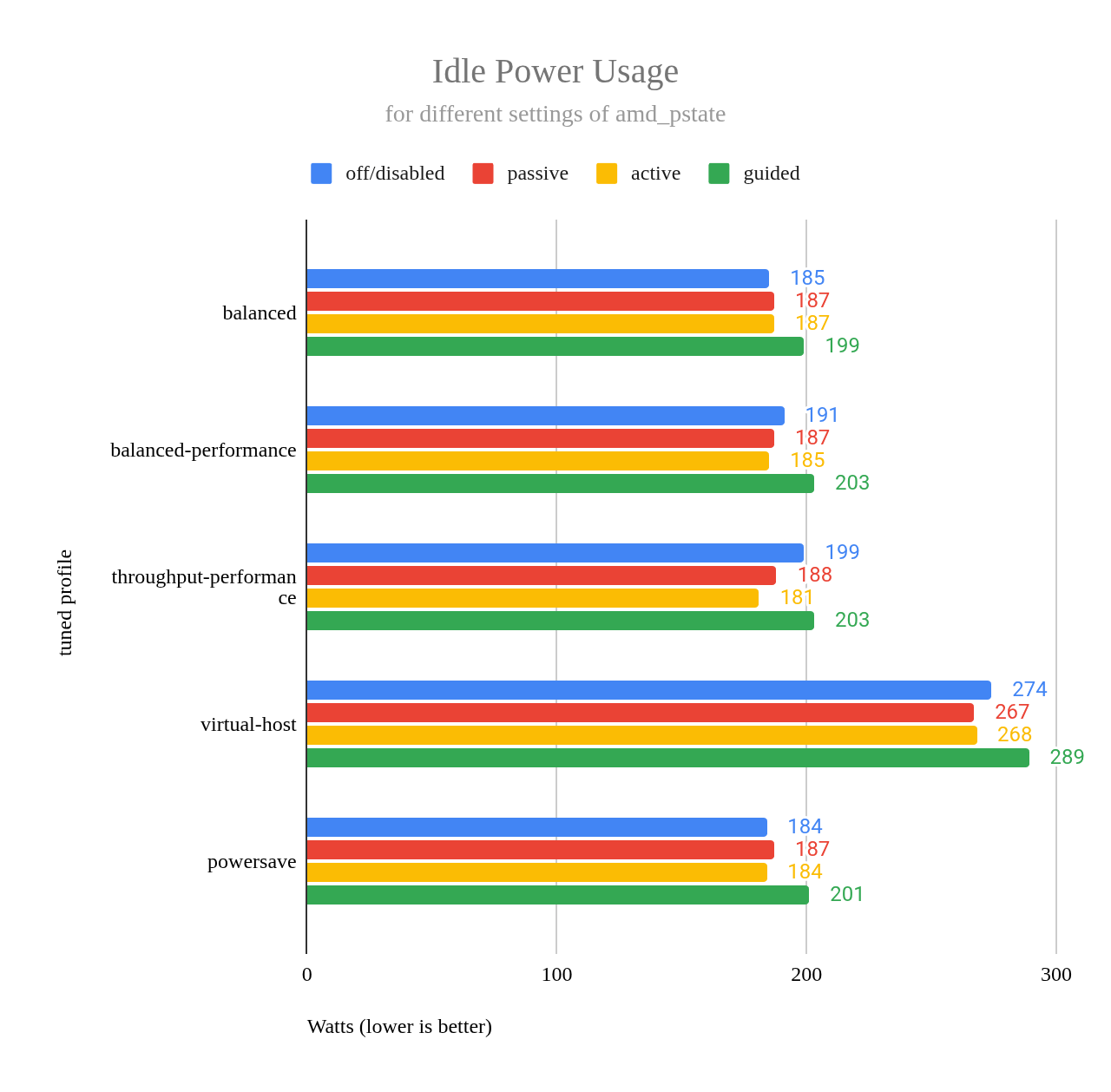
그림 3: 다양한 amd_pstate 설정에 따른 유휴 전력 사용량.
이 차트에서 알 수 있는 한 가지는 throughput-performance 프로필을 amd_pstate=active와 사용할 때 유휴 전력 사용량이 매우 좋다는 것입니다. 차트를 보면 유휴 전력 사용량이 powersave 프로필을 사용할 때보다 훨씬 낮지만, 그 차이는 오차 범위 내에 있습니다.
tuned-adm 프로파일은 고수준 성능/전력 정책을 설정 하지만, 실제 실행은 기본 CPU 드라이버(예: amd_pstate또는 acpi-cpufreq)와 특정 드라이버에 사용 가능한 스케일링 거버너에 따라 달라집니다. 이러한 상호 작용은 amd_pstate를 비활성화했을 때 일부 tuned-adm 설정이 미치는 영향이 미미했던 이유를 설명합니다. 이러한 결과에서 드라이버의 역할을 이해하기 위해 이제 amd-pstate 드라이버의 작동 모드를 자세히 살펴보겠습니다.
전력과 성능의 균형: amd-pstate의 실제 활용
앞서 설명했듯이, 전력과 성능의 균형을 맞추기 위해 사용자 지정 tuned 프로필을 작성하려는 시도는 성공적이지 못했습니다. 이 문제에 대해 조사하던 중, Huang Rui가 amd-pstate CPU Performance Scaling Driver에서 자세히 설명한 amd-pstate 드라이버에 대해 알게 되었습니다 . 이 Linux 커널 드라이버는 최신 AMD 프로세서의 CPU 성능 상태(P-state)를 관리합니다.
선택한 작업 모드( amd_pstate=active, passive, guided 커널 명령줄 매개변수를 통해 구성됨)에 따라 드라이버는 CPU가 실시간으로 주파수와 전압을 자율적으로 조정하도록 허용할 수 있습니다. 저는 세 가지 모두 실험해 보았지만, 제 하드웨어에 active와 guided가 가장 유용한 것으로 나타났습니다. 그렇다면 이러한 옵션은 무엇을 의미하며, 어떻게 활성화할 수 있을까요?
amd-pstate비활성화: EPYC 시스템에 설치된 Fedora 42에서는 기본적으로 활성화되어 있었습니다. 반면 Threadripper 7970X 시스템에서는 기본적으로active로 활성화되어 있습니다 . BIOS 설정에 따라 EPYC 시스템에서 amd-pstate도active기본적으로 이 모드로 설정될 수 있지만, 아직 찾지 못했습니다.amd_pstate=active: 이 옵션이 명령줄을 통해 커널에 전달되면 amd-pstate는 완전 자율 모드가 됩니다. OS는 하드웨어에 성능, 에너지 효율 또는 균형 중 어떤 것을 우선시할지에 대한 힌트를 제공할 수 있지만, 그 외에는 CPU의 동작을 크게 제어할 수 없습니다. 이러한 힌트는tuned프로필을 설정하여 제공할 수 있습니다 . 힌트는 프로필 구성 파일의energy_performance_preference설정으로 지정되지만, 모든 프로필( 예:latency-performance)이 이 설정을 제공하는 것은 아닙니다.amd_pstate=guided:amd_pstate=active와 유사하지만 OS가 최소 및 최대 성능 경계를 정의할 수 있도록 합니다. 그러면 하드웨어가 이 경계 내에서 주파수를 자율적으로 선택하고, 열 및 전력 조건이 허용될 때 OS의 지침을 우선적으로 적용합니다.amd_pstate=passive: 이 옵션이 명령줄을 통해 커널에 전달되면amd_pstate는 비자율 모드가 됩니다. 이 모드에서 OS는 정확한 성능 목표(예: 공칭 성능의 60%)를 지정하고, 하드웨어는 열 및 전력 제약 조건을 준수하면서 이 목표를 달성하려고 시도합니다. 에너지 대비 성능 선호도와 같은 OS 힌트를 사용하는 능동 모드나 최소/최대 경계를 설정하는 유도 모드와 달리, 수동 모드는 가능한 한 OS가 정의한 특정 성능 수준에 도달하는 데 중점을 둡니다.
제가 실험한 결과, 이 옵션은 때로는 amd-pstate를 비활성화했을 때보다 더 나은 성능을 제공했지만, 때로는 그렇지 않은 경우도 있었습니다. 특히 해당tuned프로필을virtual-host사용할 때 그렇습니다.
amd_pstate=active(그림 4)를 사용하여 서버를 배포하겠습니다 . amd_pstate=guided 테스트 중에는 성능이 약간 더 좋았지만(그림 5), active모드는 더 나은 유휴 전력 효율을 제공합니다. 이는 서버가 활동이 적은 상태에서 상당한 시간을 보내는 데 매우 중요합니다. 일반적인 워크로드에서는 성능 차이가 미미했기 때문에, 잠재적인 전력 절감은 가치 있는 타협이었습니다.
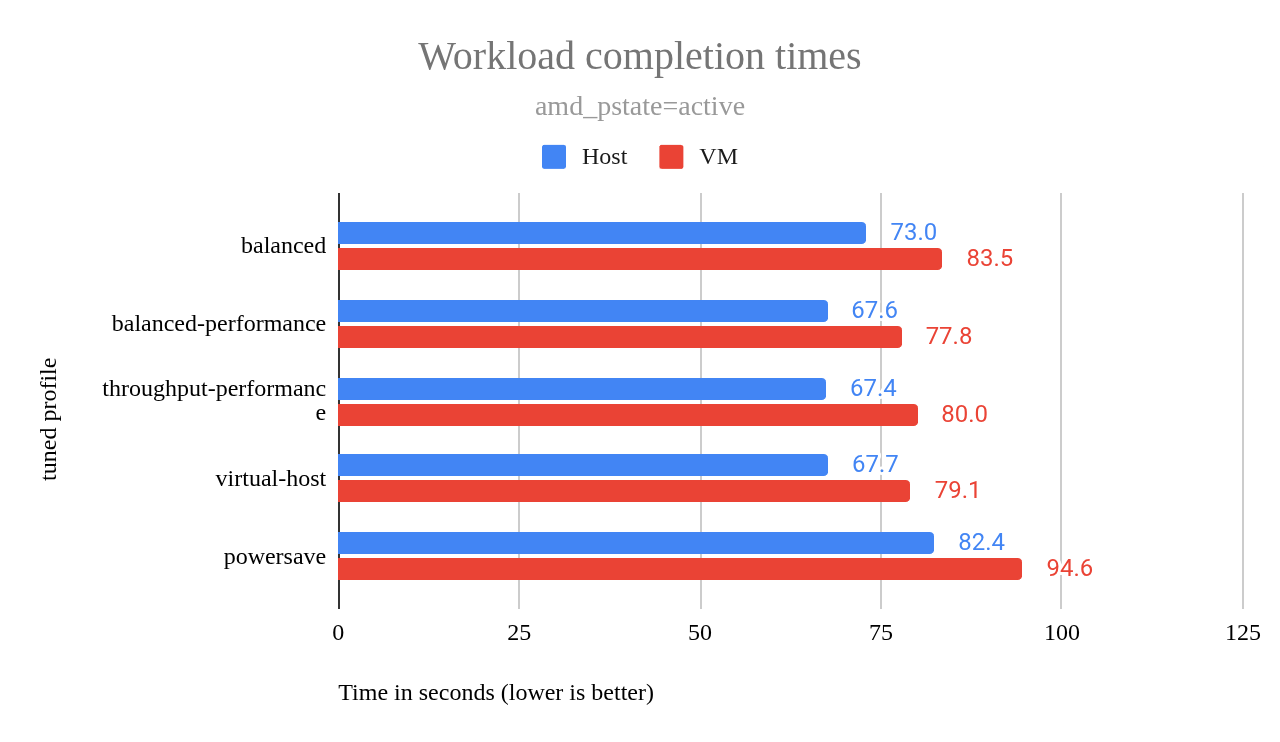
그림 4: amd_pstate=active에 대한 작업 완료 시간.
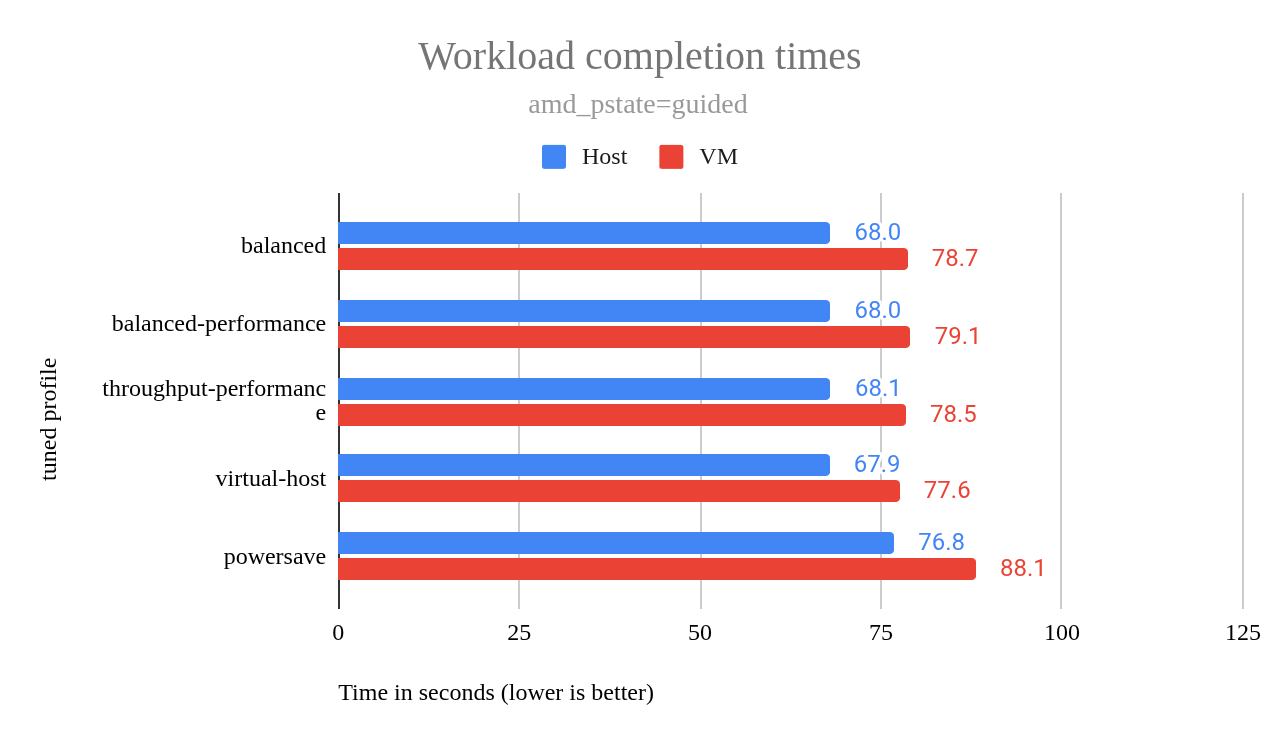
그림 5: amd_pstate=guided에 대한 작업 완료 시간.
amd_pstate=active 차트와 마찬가지로 , amd_pstate=guided 차트에서도 powersave를 제외한 모든 프로필이 거의 동일한 성과를 보였지만, 한 가지 예외가 있었습니다. amd_pstate=active그림 4의 차트에서 해당 balanced 프로필은 powersave를 제외한 모든 프로필보다 현저히 낮은 성과를 보인 반면, amd_pstate=guided 그림 5의 차트에서는 powersave를 제외한 모든 프로필이 거의 동일한 성과를 보였습니다. 마치 각 프로필의 결과를 차트에 그대로 복사한 것처럼 말이죠.
이는 amd_pstate=guided가 대부분의 튜닝된 프로필에서 관찰되는 성능 차이를 amd_pstate=active를 사용할 때 보다 효과적으로 제거함을 시사합니다. virtual-host 프로필은 앞선 전력 사용량 차트에서 볼 수 있듯이 다른 프로필에 비해 유휴 전력 소비량이 더 높았습니다.
amd-pstate 모드와 tuned 프로필 간의 상호 작용을 더욱 자세히 분석하기 위해 amd-pstate 모든 설정(비활성화, passive, active, guided)과 tuned 프로필 조합에 대한 VM 워크로드 완료 시간을 비교하는 차트를 만들었습니다 . 그림 6 참조.
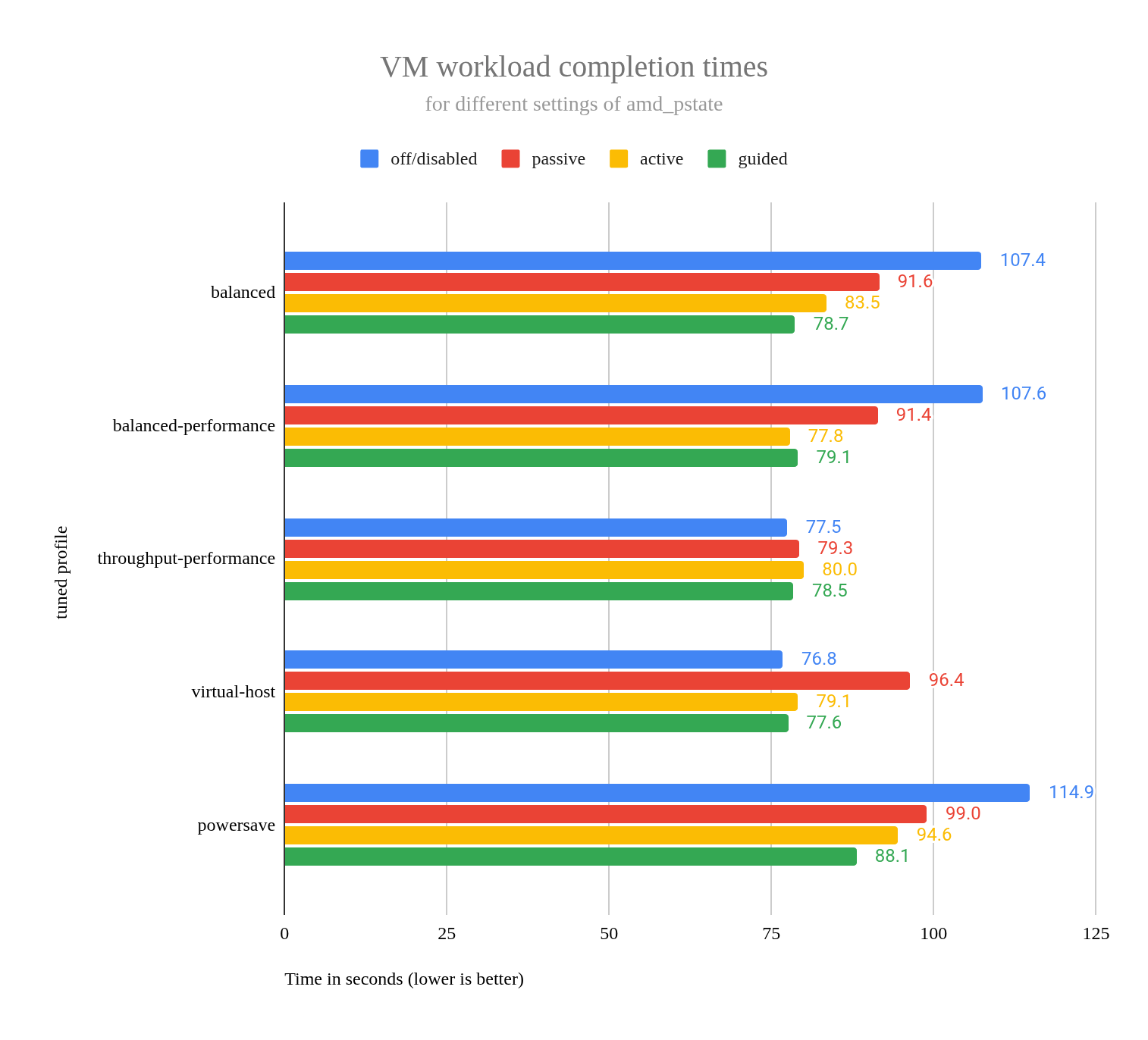
그림 6: 다양한 amd_pstate 설정(disabled, passive, active, guided)에 따른 VM 워크로드 경쟁 시간.
완화 기능 비활성화: 성능 향상 대비 보안 위험
커널 명령줄 옵션은 mitigations=off는 Spectre v1, Spectre v2, Speculative Store Bypass(SSB), Transient Scheduler 및 기타 사이드 채널 공격을 포함한 추측 실행 취약점에 대한 모든 커널 측 완화 기능을 비활성화합니다. 취약한 프로세서에서는 이러한 완화 기능이 기본적으로 활성화되어 있습니다. 이 mitigations=off 옵션은 프로세서의 취약성 여부와 관계없이 이러한 완화 기능을 비활성화합니다. 추측 실행 공격에 취약하지 않은 프로세서에서는 mitigations=off가 아무런 효과가 없습니다. 애초에 완화 기능이 활성화되어 있지 않기 때문입니다.
이 연구에서 입증된 것처럼 취약한 프로세서에서는 완화 기능을 비활성화하면 성능이 향상될 수 있습니다.
경고: 보안 완화(예:
mitigations=off)를 비활성화하면 시스템에 심각한 취약점이 발생하여 추측 실행 공격(사이드 채널 공격이라고도 함)에 취약해집니다. 이러한 공격은 공격자의 무단 데이터 접근, 시스템 무결성 손상 또는 전체 시스템 제어로 이어질 수 있으며, 영향을 받는 시스템뿐만 아니라 동일 네트워크의 다른 장치에도 영향을 미칠 수 있습니다. 광범위한 네트워크 손상 가능성을 포함한 내재된 위험은 대부분의 사용 사례에서 잠재적인 성능 이점보다 더 큽니다.
호스트 성능에 미치는 영향
호스트에서 사용하면 mitigations=off호스트에서 실행되는 작업 부하가 사용하지 않는 경우보다 10.6초(15.5%) 더 빨리 완료되었습니다.
| 기계로 테스트됨 | 호스트 완화 | N | 평균 | 표준편차 | 마그 에러 |
|---|---|---|---|---|---|
| host | on | 16 | 78.6 | 0.183 | 0.09 |
| host | off | 16 | 68.0 | 0.342 | 0.168 |
호스트 완화 기능을 비활성화할 때 VM 성능에 미치는 영향
- VM에서 완화 기능 활성화: 호스트에서 완화 기능을 비활성화한 결과, VM 워크로드가 호스트 완화 기능을 활성화했을 때보다 평균 1.2초(1.3%) 더 빠르게 완료되었습니다. 이는 오차 범위를 약간 벗어난 수치이므로, 호스트에서 완화 기능을 비활성화하면 VM 성능이 약간 향상될 수 있습니다.
- VM에서 완화 기능 비활성화: 호스트에서 완화 기능을 비활성화한 결과, VM 워크로드가 호스트 완화 기능을 활성화했을 때보다 평균 0.2초 (0.27%) 느리게 완료되었습니다 . 이 결과는 놀랍지만, 오차 범위 내에 있으므로 통계적으로 유의미하지는 않습니다.
| 기계로 테스트됨 | 호스트 완화 | VM 완화 | N | 평균 | 표준편차 | 마그 에러 |
|---|---|---|---|---|---|---|
| VM | on | off | 16 | 79.6 | 1.966 | 0.963 |
| VM | off | off | 16 | 79.8 | 3.066 | 1.502 |
| VM | on | on | 16 | 90.9 | 1.732 | 0.849 |
| VM | off | on | 16 | 89.7 | 1.94 | 0.951 |
VM에서 완화 기능을 비활성화하는 영향
- 호스트에서 완화 기능이 비활성화됨: VM에서 완화 기능을 비활성화하면 VM 워크로드가 완화 기능이 활성화된 경우보다 평균 9.9초(12%) 더 빨리 완료됩니다.
- 호스트에서 완화 기능이 활성화됨: VM에서 완화 기능을 비활성화하면 VM 워크로드가 완화 기능이 활성화된 경우보다 평균 11.3초(14.2%) 더 빨리 완료됩니다.
| 기계로 테스트됨 | 호스트 완화 | VM 완화 | N | 평균 | 표준편차 | 마그 에러 |
|---|---|---|---|---|---|---|
| VM | off | on | 16 | 89.7 | 1.94 | 0.951 |
| VM | off | off | 16 | 79.8 | 3.066 | 1.502 |
| VM | on | on | 16 | 90.9 | 1.732 | 0.849 |
| VM | on | off | 16 | 79.6 | 1.966 | 0.963 |
추측 실행 취약점 논의
이 데이터는 호스트에서 완화 기능을 비활성화하면 호스트 워크로드 성능이 15.5% 향상됨을 보여줍니다. 그러나 VM 워크로드에서는 호스트에서 완화 기능을 비활성화해도 거의 효과가 없습니다.
반면, VM에서 완화 기능을 비활성화하면 호스트에서 완화 기능이 비활성화되었는지 활성화되었는지에 따라 12% 또는 14%의 성능 향상 효과가 있는 것으로 나타났습니다. 이 결과를 차트(그림 7)로 보여주며 이 섹션을 마무리하겠습니다.
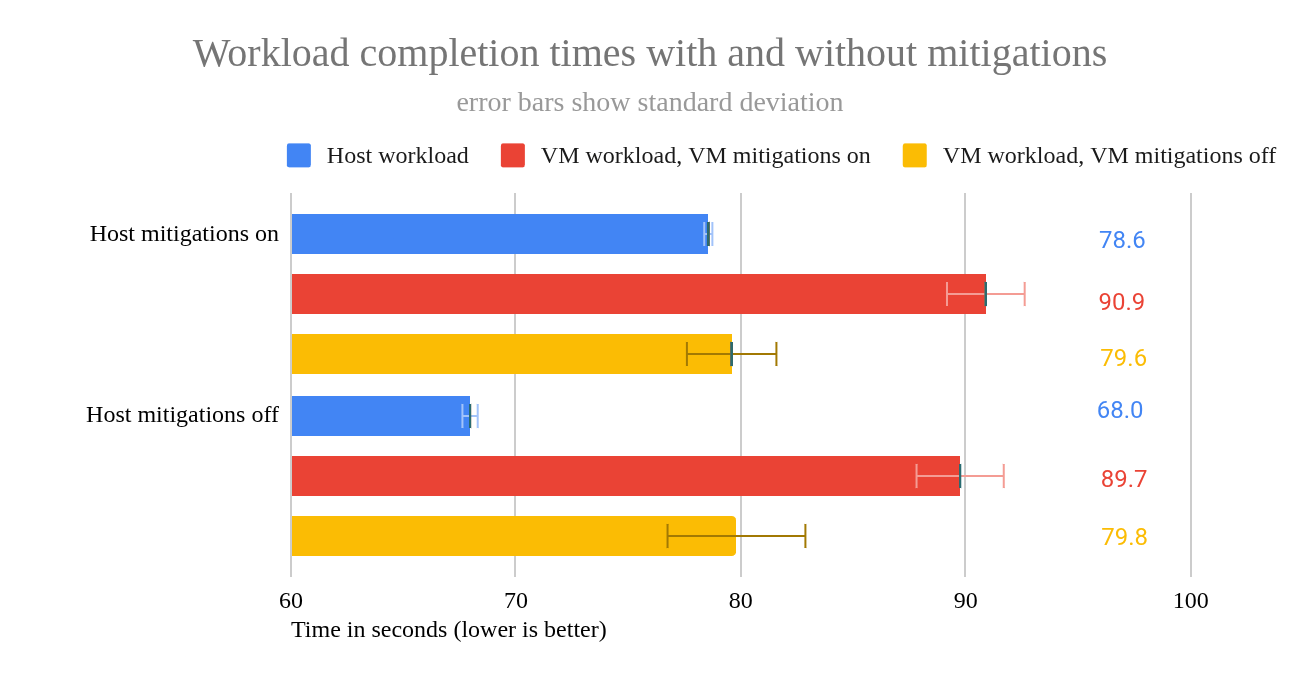
그림 7: 완화 조치를 적용한 경우와 적용하지 않은 경우의 작업 완료 시간.
VM NIC 대기열 및 CPU 고정
이 libvirt 프레임워크를 사용하면 가상 네트워크 인터페이스 카드(NIC) 대기열을 구성하여 네트워크 트래픽 워크로드를 CPU 코어 전체에 분산할 수 있습니다. 이는 NIC의 XML 설명에 <driver name="vhost" queues="16"/> 내용을 추가하여 수행됩니다. 제 테스트 VM에서 다음과 같은 모습이 나타납니다.
<interface type="bridge"> <mac address="52:54:00:19:0a:b5"/> <source bridge="br0"/> <model type="virtio"/> <driver name="vhost" queues="16"/> <link state="up"/> <address type="pci" domain="0x0000" bus="0x01" slot="0x00" function="0x0"/> </interface>
이렇게 하면 VM의 NIC에 16개의 대기열이 추가됩니다. 대기열 개수는 XML 요소가 없을 때 생성되는 1개뿐 아니라 4, 8, 16, 20, 28, 32개 등 여러 값으로 실험해 보았습니다. 32개의 대기열로 테스트할 때는 가상 CPU를 호스트 CPU에 고정해야 했습니다. 이렇게 하지 않으면 VM이 부팅 중에 중단되었습니다.
GDB 빌드 워크로드를 테스트한 결과, 다양한 큐 크기 간의 평균 완료 시간을 비교했을 때 통계적으로 유의미한 차이는 없었습니다. 그러나 큐 크기가 작을 때는 샘플 수가 5개뿐이었음에도 불구하고 표준 편차가 더 컸습니다. 큐 크기가 1일 때 5회 테스트를 실행한 결과, 표준 편차는 4.2였고 오차 한계(95% 신뢰 구간)는 3.7이었습니다. 따라서 큐 수가 많을수록 더 일관된 결과를 얻을 수 있다는 점은 어느 정도 이점이 있습니다.
GDB 워크로드 외에도 네트워크 테스트에 일반적으로 사용되는 도구인 iperf3를 사용하여 테스트했습니다. 물리적 NIC 문제를 확인하는 데도 가끔 사용하지만, VM과 호스트 간의 네트워크 대역폭을 확인하는 데 더 자주 사용합니다. 네트워크 성능을 측정하기 위해 iperf3 -s호스트(서버)와 VM(클라이언트)에서 iperf3 -P 16 -c name-of-host, 16개의 병렬 스트림을 사용하여 동시 연결을 시뮬레이션했습니다.
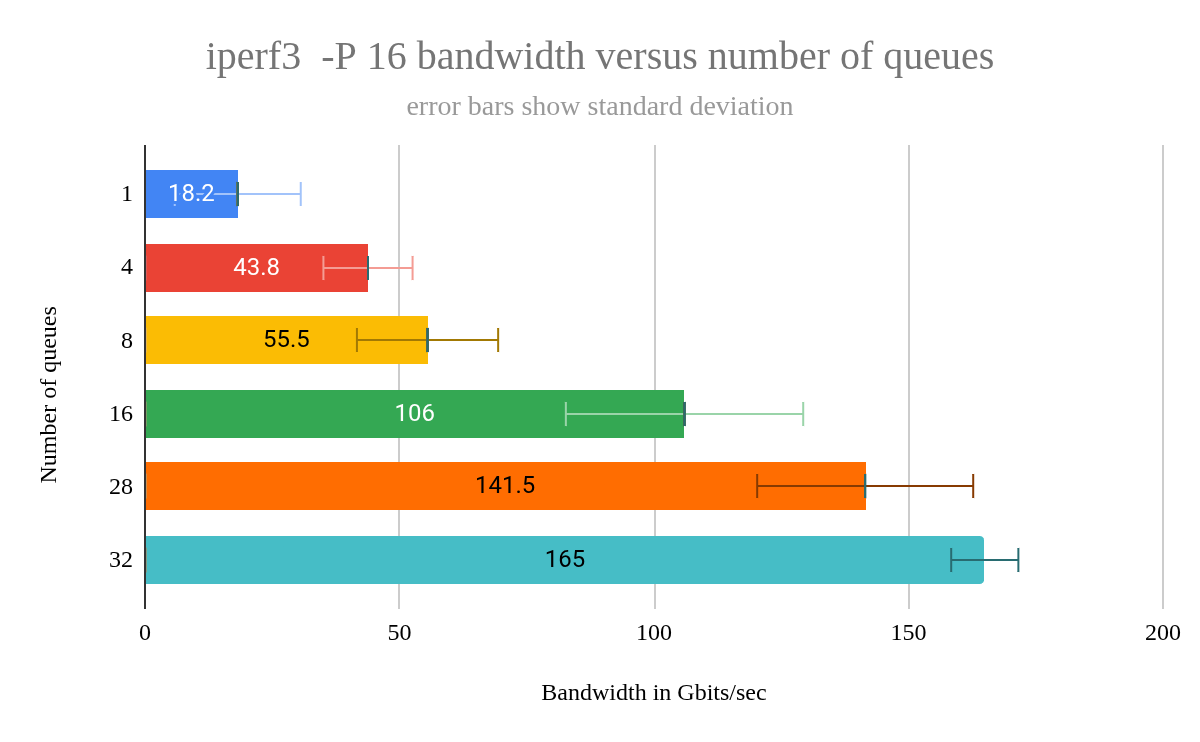
그림 8: iperf3-P 16 대역폭 대 대기열 수.
queues=32의 표준 편차는 4.3으로 가장 낮았습니다 . 하지만 앞서 언급했듯이, 컴퓨터를 부팅하려면 CPU 고정을 활용해야 했습니다. 각 VM CPU를 호스트 CPU(코어)에 고정(할당)하여 하이퍼스레딩으로 인해 코어가 공유되지 않도록 했습니다. 대기열 개수보다 CPU 고정이 표준 편차 감소에 더 큰 영향을 미쳤을 것으로 예상됩니다. 따라서 VM에서 더욱 결정적인 성능을 원한다면 CPU 고정을 사용하는 것을 고려해 보세요.
CPU 고정은 다음 XML을 사용하여 수행됩니다. 이 예는 내 VM의 32개 코어를 호스트의 32개 코어에 할당하는 데 사용한 것입니다.
<cputune> <vcpupin vcpu="0" cpuset="0"/> <vcpupin vcpu="1" cpuset="1"/> ... <vcpupin vcpu="31" cpuset="31"/> </cputune>
큰 영향을 미치지 않는 변경 사항
다음 변경 사항은 측정 가능한 성능 차이를 보이지 않았습니다.
- 커널 명령줄 옵션
amd_iommu=on iommu=pt:amd_iommu=onAMD IOMMU(입출력 메모리 관리 장치)를 활성화하여 VM에 할당된 장치에 대한 하드웨어 수준의 메모리 보호 및 주소 변환을 제공합니다.iommu=pt(패스스루 모드) 가상화 오버헤드 없이 물리적 장치에 직접 액세스할 수 있습니다. 이러한 옵션은 효율적인 GPU 또는 NIC 패스스루를 위해 필수적입니다. 이 옵션을 사용해도 워크로드 성능에 영향을 미치지 않는 것으로 확인되었습니다. - 호스트의 NFS 서버: VM과 호스트 간의 네트워크 지연 시간이 줄어들어 약간의 성능 향상을 기대했지만 아무런 차이도 관찰되지 않았습니다.
- 호스트 파일 시스템을
virtiofs로 공유 :virtiofs는 가상화 환경을 위한 고성능, 저부하 파일 시스템 공유 메커니즘입니다. virtio 프레임워크를 사용하여 VM에서 호스트 파일 시스템에 직접 액세스할 수 있도록 하여 NFS와 같은 기존 방식에 비해 가상화 오버헤드를 줄입니다. EPYC 머신에서는 NFS보다 성능이 떨어졌습니다. 다른 시스템에서는 약간 더 빨랐습니다. - single root I/O virtualization(SR-IOV)를 사용하여 VM에 물리적 NIC 할당: SR-IOV를 사용하면 하나의 물리적 NIC가 여러 개의 가상 NIC처럼 표시되며, 각 NIC는 직접 하드웨어에 액세스할 수 있습니다. 이를 통해 가상화 오버헤드를 줄이고 네트워크 성능을 향상시킵니다.
iperf3테스트 결과, VM과 NFS 서버 간의 성능은 향상되었지만 GDB 빌드 성능에는 영향을 미치지 않았습니다. - VM에서
tuned프로필을 변경: 성능에 큰 변화는 관찰되지 않았습니다.
작업 항목
AMD 시스템을 관리하고 VM 성능이 amd-pstate 운영 모드 중 하나를 사용하지 않거나 최적이 아닌 프로필을 사용하여 저하되는지 궁금하다면 tuned다음 명령을 실행하여 빠르게 확인할 수 있습니다.
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_driver
이 명령을 실행하면 다음 중 하나가 표시될 가능성이 높습니다.
acpi-cpufreq: VM 성능이 예상보다 좋지 않을 수 있습니다.acpi-pstate-epp: 시스템이amd-pstate드라이버를active모드에서 사용하고 있습니다 . 아마도 성능이 꽤 좋을 것입니다.acpi-pstate: 시스템에서amd-pstate드라이버를passive,guided두 모드 중 하나로 사용하고 있습니다 . 드라이버가passive모드에 있는 경우 , 원인을 파악한 후guided,active두 모드 중 하나로 전환해 보세요.- 다른 가능성도 있지만, 이는 이 기사의 범위를 벗어납니다.
amd-pstate 드라이버가 사용 중인 경우 다음 명령을 사용하여 해당 모드를 확인할 수 있습니다.
cat /sys/devices/system/cpu/amd_pstate/status
드라이버 amd-pstate를 사용하지 않으면 이 파일은 존재하지 않습니다. 하지만 드라이버를 사용 중이라면, passive, guided, active는 명확한 의미를 가진 출력입니다.
AMD 시스템에서 acpi-cpufreq스케일링 드라이버를 사용하는 경우 다음 두 가지를 개별적으로 또는 조합하여 시도해 볼 수 있습니다.
- 패키지를 설치한
tuned후tuned-adm profile명령을 사용하여 프로필을 변경하세요.tuned-adm active명령을 사용하면 현재 프로필을 확인할 수 있습니다.balanced프로필이 사용 중이라면 프로필을throughput-performance로 변경해 보세요. amd-pstate드라이버를 강제로 사용하도록 전환해 보세요 . 커널 명령줄amd_pstate=active등을 통해 이를 수행할 수 있습니다. GRUB 부트로더를 사용하는 시스템에서는/etc/default/grub을 편집하고GRUB_CMDLINE_LINUX설정에amd_pstate=active추가하세요 . 이 작업이 완료되면 Fedora 또는 RHEL 시스템에서sudo grub2-mkconfig -o /etc/grub2-efi.cfg을 수행하세요 . (다른 시스템에서 GRUB을 업데이트하는 방법은 다른 곳에서 쉽게 확인할 수 있습니다.) 이 작업이 완료되면 재부팅한 다음 이 섹션의 앞부분에서 표시된 명령을 사용하여amd-pstate드라이버가 사용 중이고 예상되는 작동 모드를 사용하고 있는지 확인합니다.
마지막 생각
tuned프로필을 virtual-host로 변경하자 GDB 빌드 워크로드의 성능이 즉각적으로 향상되었지만, 유휴 전력 소비가 급증하는 큰 비용이 발생했습니다. 이러한 단점 때문에 amd-pstate를 조사해 보았는데, amd-pstate=active를 사용하더라도 virtual-host 프로필이 balanced-performance 또는 throughput-performance 보다 훨씬 더 많은 전력을 소비한다는 것을 발견했습니다.
제 시스템에는 virtual-host 프로필이 적합하지 않습니다. 대신 제가 만든 balanced-performance 프로필이나 뛰어난 성능을 제공하고 유휴 전력을 낮게 유지하는 throughput-performance 프로필을 사용하겠습니다.
이 경험을 통해 성능 튜닝은 단순히 속도만이 아니라, 균형점을 찾는 것임을 깨달았습니다. 최고의 프로파일이 항상 가장 빠른 것은 아닙니다. 워크로드와 전력 제약에 적합한 프로파일이 가장 중요합니다.
이 연구의 주요 내용
tuned프로필을 변경하면 예상치 못한 영향을 미칠 수 있지만, 유휴 전력 소비에 부정적인 영향을 미치지 않는지 확인하세요.- 최신 AMD 시스템에는
amd-pstate가 필수적이며,active모드guided는 성능과 전력 효율성의 가장 좋은 균형을 제공합니다. mitigations=off를 사용하면 성능이 향상될 수 있지만 보안 위험을 완전히 이해하지 않은 이상 사용하지 마세요.amd-pstate를 활성화 하거나tuned프로필을 변경하는 것과 같은 사소한 변경만으로도 베어 메탈과 VM 성능 간의 격차를 줄일 수 있습니다.
VM 성능에 대한 이러한 탐구는 목표 지향적 튜닝을 통해 상당한 성능 향상을 달성할 수 있음을 보여줍니다. 베어 메탈과 VM 간의 초기 성능 격차는 상당했지만, 시스템 프로필, CPU 스케일링 드라이버에 대한 세심한 조정과 전력 효율성에 대한 집중을 통해 그 격차를 상당히 줄였습니다. 이러한 경험을 통해 성능 튜닝은 단순히 속도를 극대화하는 것이 아니라 성능과 전력 소비 간의 최적의 균형을 찾는 중요한 원칙이 강조되었습니다.
실험과 꼼꼼한 측정, 그리고 가정에 도전하는 의지를 받아들이면 디버거를 구축하든 다른 까다로운 작업을 처리하든 시스템의 잠재력을 최대한 활용할 수 있습니다.


