Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://www.redhat.com/en/blog/energy-efficient-computing-server-platforms-red-hat-enterprise-linux
데이터 센터와 고성능 시스템의 에너지 효율성은 점점 더 중요해지고 있습니다. 에너지 비용은 운영 지출(OPEX) 예산의 상당 부분을 차지할 수 있으며, 잠재적으로 사업의 성공과 실패를 좌우하는 중요한 요인이 될 수 있습니다. 본 논문에서는 최신 서버 플랫폼의 에너지 효율성 문제를 분석하고, 전력 소비 및 성능 측정 도구와 예시 방법론을 제시합니다. 사례 연구로서 서로 다른 CPU 아키텍처를 사용하는 두 가지 서버 플랫폼의 측정 결과를 제시합니다. 네트워크 성능(처리량 측정 포함), CPU 사용률, 그리고 전력 소비를 중점적으로 분석하며, 특히 소비되는 에너지 와트당 최대 처리량 달성에 중점을 둘 것입니다.
테스트 방법론
컴퓨터 성능과 전력 요구 사항 간의 관계를 평가하는 것은 세 가지 주요 단계로 나눌 수 있습니다.
- 컴퓨터의 성능을 평가하세요
- 컴퓨터의 전력 요구 사항 측정
- 전력 소비에 대한 성능 정규화
시스템 성능은 물리적 CPU 코어당 달성 가능한 처리량(초당 기가비트)을 기준으로 측정합니다. 최신 고속(100Gbps 이상) 이더넷 어댑터를 사용하는 경우 단일 사용자 공간 프로세스가 사용 가능한 모든 대역폭을 활용하는 것은 사실상 불가능하다는 점에 유의해야 합니다. 더욱이 네트워크 처리량은 성능의 일부에 불과합니다. 네트워크 트래픽 처리는 이상적으로 최소한의 리소스만 소모하여 시스템 대부분을 네트워크를 통해 전송되는 데이터를 생성하거나 처리하는 데 사용할 수 있도록 합니다. 이상적으로는 CPU가 가능한 한 적은 수의 코어로 포화 상태여야 합니다.
이러한 요구 사항을 정량화하기 위해 다음 지표를 모니터링합니다.
- 초당 기가비트 단위로 달성 가능한 최대 처리량입니다.
- 코어 단위로 측정한 총 CPU 사용률입니다. 편의상 절반만 로드된 코어 두 개는 완전히 로드된 코어 하나로 계산됩니다.
- 계산 효율은 초당 기가비트(Gbps) 단위의 처리량을 CPU 사용률로 나눈 값입니다. 예를 들어, 두 개의 CPU 코어를 사용하여 60Gbps의 처리량을 처리하는 시스템의 계산 효율은 코어당 30Gbps입니다.
네트워크 처리량 측정
네트워크 처리량을 측정하기 위해 업계 표준으로 널리 인정받는 오픈 소스 iperf3 벤치마킹 도구를 사용합니다. 벤치마킹에 사용된 정확한 명령어는 다음과 같습니다.
iperf3 --json --client 172.16.0.42 --time 30 --port 5201 --parallel 8 --parallel 8 옵션은 트래픽이 8개의 동시 TCP 소켓을 사용하여 전송되지만, 사용자 공간 프로세스는 하나만 사용하도록 지정합니다. 이 방식은 Receive Side Scaling (RSS) 해싱 함수의 아티팩트를 완화하고 재현 가능한 결과를 보장합니다. 다른 방법은 원격 및 로컬 TCP 포트를 고정하고 ethtool ntuple 기능을 사용하여 CPU 간에 흐름을 균등하게 분배하도록 RSS를 구성하는 것입니다. 테스트에 사용된 모든 네트워크 인터페이스 컨트롤러(NIC)가 처음에 ntuple RSS 구성을 지원하지 않았기 때문에 병렬 소켓 방식을 선택했습니다. 이 방법의 잠재적 단점 중 하나는 여러 CPU 코어에서 데이터를 처리할 때 캐시 동작이 최적화되지 않는다는 것입니다. 그러나 모든 테스트에 동일한 구성을 사용하므로 결과는 비슷합니다.
CPU 사용률 측정
CPU 사용률을 측정에 mpstat 명령을 사용합니다.
mpstat -P ALL 30 iperf3 벤치마크 시작 직전에 프로그래밍 방식으로 mpstat 프로세스를 실행합니다. 이 예시에서 숫자 30은 CPU 사용량이 iperf3 실행 시간과 동일한 30초 동안 모니터링됨을 나타냅니다.
로컬과 원격의 처리량이 동일하더라도 CPU 사용률은 다릅니다. 송신 측은 TCP segmentation offload (TSO)를 사용하여 데이터 조각화를 NIC에 오프로드하는 반면, 수신 측은 소프트웨어에서 데이터를 재구성해야 하기 때문에 수신 데이터는 일반적으로 송신 데이터보다 CPU 사용량이 더 높습니다. 따라서 송신 측과 수신 측 모두에서 CPU 사용률을 모니터링해야 합니다. 대부분의 경우, 달성 가능한 처리량을 결정하는 데 더 중요한 요소인 원격 CPU 사용률을 보고합니다.
계산 효율성
계산 효율성을 평가하기 위해 처리량을 100배로 조정한 총 시스템 부하로 나눕니다. 100으로 나누는 것은 mpstat
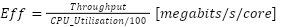
이 방정식은 완전히 로드된 단일 코어의 가상 성능을 제공합니다.
네트워크 집약적 프로세스 운영 체제
테스트 대상 시스템은 다양한 운영 조건에서 다르게 동작할 수 있습니다. 다음 운영 모델에서 시스템을 테스트합니다.
단일 프로세스
사용자 공간 프로세스는 하나만 실행됩니다. 일반적으로 두 개의 CPU 코어가 사용됩니다. 하나는 iperf3 프로세스용이고 다른 하나는 인터럽트 처리용입니다. 여기서 CPU 클럭 주파수와 사이클당 명령어 처리량(IPM)이 달성되는 처리량을 결정하며, 이상적으로는 가능한 한 높아야 합니다.
다중 프로세스
여러 사용자 공간 프로세스가 실행 중이지만, 여전히 사용 가능한 대역폭을 완전히 포화시키지는 못합니다. CPU 멀티코어 성능은 달성된 처리량의 분모가 됩니다. 이상적으로 처리량은 선형적으로 증가해야 합니다. 코어 수를 두 배로 늘리면 처리량도 약 두 배로 증가해야 합니다.
포화 상태
이 모델에서는 링크가 포화될 만큼 충분한 사용자 공간 프로세스가 실행되고 있으며, 이는 처리량이 NIC의 회선 속도, 즉 최대 잠재 처리량에 도달함을 의미합니다. 프로세스를 추가한다고 해서 처리량이나 전체 시스템 부하가 증가하는 것은 아닙니다. 대신, 추가 프로세스는 동일한 CPU 코어 세트에 스케줄링되어야 합니다.
멀티코어 및 포화 성능을 측정하기 위해 여러 병렬 iperf3 인스턴스를 동시에 실행합니다. iperf3와 mpstat 프로세스의 오케스트레이션은 Red Hat에서 개발한 벤치마킹 도구인 Nepta를 통해 처리됩니다 .
단일 네트워크 스트림을 처리하는 데는 운영 체제가 처리하는 두 가지 주요 작업이 포함됩니다.
- 네트워크 트래픽을 생성하거나 수신하는 네트워크 집약적 사용자 공간 프로세스 실행
- 네트워크 카드에서 생성된 많은 수의 인터럽트 처리
하드웨어 지역성을 위한 워크로드 최적화
이 단계에서는 하드웨어를 이해하는 것이 중요합니다. 거의 모든 서버 하드웨어는 NUMA(Non-Uniform Memory Access) 아키텍처를 사용하는데, 이는 액세스하는 메모리 영역에 따라 액세스 시간이 달라진다는 것을 의미합니다.
각 CPU 코어에는 로컬 메모리(코어에 물리적으로 가장 가까운 메모리 컨트롤러(일반적으로 동일한 실리콘 다이 또는 소켓에 있음)에 연결된 메모리)와 원격 메모리(다른 소켓 또는 다이에 있는 메모리 컨트롤러에 연결된 메모리)가 있습니다.
마찬가지로, 동일한 실리콘의 컨트롤러에 연결된 PCI 장치는 로컬 PCI 장치로 간주되고, 그 외의 모든 장치는 원격 PCI 장치로 간주됩니다.
CPU 코어, PCI 장치, 메모리 컨트롤러, 인접 메모리 모듈의 조합은 NUMA 노드를 형성합니다.
lstopo 유틸리티를 사용하면 하드웨어 토폴로지를 시각화할 수 있습니다. 출력은 텍스트로 표시됩니다.
lstopo출력 그래픽 파일을 정의하여 이미지를 생성할 수 있습니다.
lstopo topology.png다음은 하드웨어 토폴로지를 나타내는 생성된 PNG 파일의 예입니다.
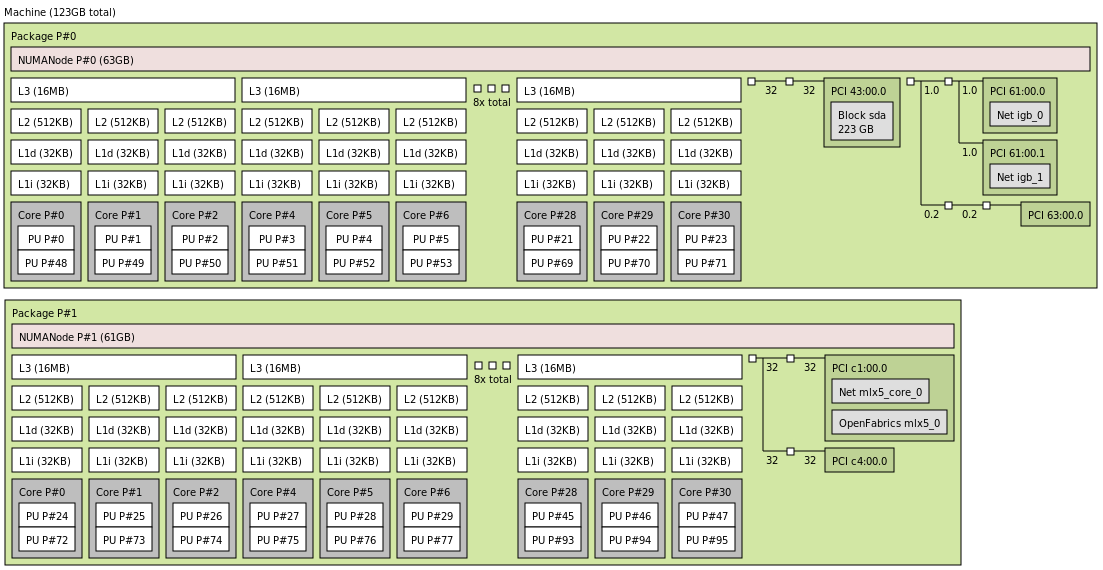
네트워크 집약적 프로세스를 위한 NUMA 인식 리소스 할당
네트워크 집약적인 프로세스 관점에서 네트워크 카드는 로컬 NUMA 노드 또는 원격 NUMA 노드에 위치할 수 있습니다. 원격 노드에서 프로세스를 실행하면 일반적으로 두 자릿수의 성능 저하가 발생합니다. 하지만 이것이 원격 코어를 유휴 상태로 두어야 한다는 것을 의미하지는 않습니다. 성능 저하가 있더라도 원격 코어를 사용하는 것이 완전히 사용하지 않는 것보다 훨씬 낫습니다.
현재 Linux 스케줄러는 메모리 지역성을 고려하지만 프로세스의 I/O 요구 사항을 최적화하지는 않습니다. 이러한 측면을 최적화하는 것은 전적으로 사용자의 책임입니다.
경험적 경험에 근거하여 자원 배분을 위해 다음과 같은 전략이 권장됩니다.
1. 네트워크 카드가 있는 NUMA 노드의 CPU 코어보다 네트워크 집약적 프로세스가 적습니다.
- 로컬 NUMA 노드의 일부 CPU 코어를 네트워크 집약적 프로세스에 할당합니다.
- 동일한 노드의 다른 CPU 코어를 인터럽트 처리에 할당합니다.
2. NUMA 노드의 CPU 코어보다 네트워크 집약적인 프로세스가 더 많지만 시스템의 총 CPU 코어의 두 배를 넘지 않음:
- 로컬 NUMA 노드의 모든 CPU 코어를 인터럽트 처리에 전용합니다.
- 시스템의 나머지 CPU 코어를 모두 네트워크 집약적 프로세스에 할당합니다.
3. 수천 개의 네트워크 집약적 프로세스 또는 여러 NUMA 노드에 걸쳐 리소스를 필요로 하는 프로세스:
- 기본 Red Hat Enterprise Linux(RHEL) 구성을 사용하세요. RHEL은 기본적으로 이 시나리오에 최적화되어 있습니다.
인터럽트 및 프로세스 고정
특정 네트워크 드라이버에서 생성된 인터럽트는 tuna 유틸리티를 사용하여 CPU 하위 집합에 고정할 수 있습니다.
sudo tuna --spread=0-12 --irqs=$(grep ice /proc/interrupts | \
awk '{print $1}' | sed 's/://')이 명령은 ice 드라이버가 생성한 모든 네트워크 인터럽트를 CPU 0~12에 분산합니다.
네트워크 관련 프로세스는 taskset를 사용하여 특정 CPU 코어에 고정할 수 있습니다. 새로 시작된 프로세스의 경우:
taskset -c 1 ./process이미 실행 중인 프로세스의 경우 pgrep 또는 pidof 또는 ps를 사용하여 프로세스의 PID를 얻어 tasksel에 전달합니다.
taskset -cp 1 <PID>여러 네트워크 관련 프로세스를 실행할 때는 각 프로세스를 전용 CPU에 고정해야 합니다. 많은 네트워크 데몬은 자식 프로세스를 특정 CPU에 고정하는 구성 옵션도 제공하며, 이를 통해 성능을 더욱 최적화할 수 있습니다.
테스트의 하드웨어 환경
이 문서의 목적은 다양한 컴퓨팅 플랫폼의 성능이나 전력 소비를 비교하는 것이 아닙니다. Red Hat의 목표는 시스템 간 벤치마크가 아니라, 사용 가능한 모든 하드웨어에서 최적의 성능을 제공하는 것입니다.
이 사례 연구에서는 CPU 아키텍처, 코어 수, 시스템 메모리 크기가 서로 다른 세 가지 서버 시스템을 사용합니다. 이 시스템들은 연산 및 전력 효율 분석을 설명하기 위한 용도로만 사용됩니다. 벤치마킹을 위해 네트워크 집약적인 프로세스의 수가 가장 가까운 NUMA 노드의 CPU 코어 수보다 적은 간단한 시나리오에 초점을 맞춥니다.
시스템 1: 엔트리 레벨 ARM 서버
- CPU: 32코어 @ 1.7GHz
- 벤치마크 구성: 최대 16개의
iperf3인스턴스, 16개의 코어는 인터럽트 처리에, 16개의 코어는 iperf 프로세스 실행에 전용됨
시스템 2: 고성능 ARM 서버
- CPU: 80코어 @ 2.2GHz
- 벤치마크 구성: 최대 40개의
iperf3인스턴스, 인터럽트 처리에 전용된 40개의 코어, iperf 프로세스 실행에 전용된 40개의 코어
시스템 3: 기존 x64 서버
- CPU: 32코어 @ 3.2GHz
- 벤치마크 구성: 최대 40개의
iperf3인스턴스, 인터럽트 처리에 전용된 40개의 코어, iperf 프로세스 실행에 전용된 40개의 코어
각 시스템의 CPU 고정 구성은 다음 표에 요약되어 있습니다.
| 프로세스 수 | 시스템 1ARM 32코어 | 시스템 2ARM 80코어 | 시스템 3×64 코어 | |||
| 프로세스 코어 | 인터럽트 코어 | 프로세스 코어 | 인터럽트 코어 | 프로세스 코어 | 인터럽트 코어 | |
| 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 2 | 0,1 | 2,3 | 0,1 | 2,3 | 0,1 | 2,3 |
| 4 | 0-3 | 4-7 | 0-3 | 4-7 | 0-3 | 4-7 |
| 8 | 0-7 | 7-15 | 0-7 | 7-15 | 0-7 | 7-15 |
| 16 | 0-15 | 16-31 | 0-15 | 16-31 | 0-15 | 16-31 |
| 32 | 실행되지 않음 | 실행되지 않음 | 0-31 | 32-63 | 실행되지 않음 | 실행되지 않음 |
| 40 | 실행되지 않음 | 실행되지 않음 | 0-39 | 40-79 | 실행되지 않음 | 실행되지 않음 |
컴퓨터 시스템 전력 소비량 평가
컴퓨터 시스템의 전력 소비량을 측정하는 데에는 세 가지 일반적인 접근 방식이 있습니다.
외부 전력계
교정된 외부 전력계(전력계)를 사용하는 것이 전체 시스템 전력을 측정하는 가장 신뢰할 수 있는 방법입니다. 하지만 CPU, SSD, 메모리 등 개별 구성 요소의 전력 소비량에 대한 정보는 제한적입니다. 일부 고급 전력계에는 자동 측정을 위한 직렬 인터페이스가 포함되어 있지만, 직렬 회선을 통한 자동화는 종종 번거롭고 복잡합니다.
시스템 유틸리티
일부 CPU 공급업체는 심층적인 전력 분석을 위한 명령줄 유틸리티를 제공합니다. 이러한 도구는 캐시, 메모리 컨트롤러, PCI 컨트롤러의 전력 소비량을 포함하여 CPU 동작에 대한 자세한 정보를 제공합니다. 하지만 CPU 전력만 측정할 뿐, 전원 공급 장치나 저장 장치와 같은 시스템 전체의 전력 소비량은 모니터링할 수 없습니다.
플랫폼 관리
일부 플랫폼 공급업체는 전력 측정 기능을 플랫폼 관리 인터페이스에 통합합니다. 이러한 접근 방식은 외부 계측기와 CPU 유틸리티의 장점을 결합합니다. 즉, 신뢰성이 높고 자동화가 가능하며 구성 요소 수준의 통찰력을 제공합니다. 하지만 이러한 기능은 모든 시스템에서 보편적으로 사용할 수 있는 것은 아닙니다.
다행히도 모든 테스트 시스템에는 섀시 수준 전력 모니터링 기능이 장착되어 있어 ipmitool로 액세스할 수 있습니다.
sudo tuna --spread=0-12 --irqs=$(grep ice /proc/interrupts | \
awk '{print $1}' | sed 's/://')이 명령은 팬 속도, 전압, 그리고 (가장 중요한) 전력 소비량을 포함한 모든 하드웨어 센서의 측정값을 반환합니다. 저희 시스템에서는 다음과 같은 전력 측정값을 사용할 수 있습니다.
- PSU1 Power In: 전원 공급 장치 1의 AC 입력 전원
- PSU1 Power Out: 전원 공급 장치 1의 DC 출력 전원
- PSU2 Power In: 전원 공급 장치 2의 AC 입력 전원
- PSU2 Power Out: 전원 공급 장치 2의 DC 출력 전원
- CPU_Power: 마더보드 전압 조정기에서 측정된 CPU에서 소모되는 DC 전력
- Memory_Power (x64 시스템 전용): 마더보드 전압 조정기에서 측정된 DRAM 전력
이 측정값을 AC 전력계(AC 측)와 DC 클램프 미터(DC 측)를 통해 검증했습니다. 모든 측정값은 ipmitool외부 측정값과 5% 이내로 일치하여 정확도에 대한 확신을 가질 수 있었습니다.
ipmitool 보고는 순간적인 측정값이라는 점에 유의해야 합니다. 초기 테스트에서 벤치마크 시작 후 1초 후에 전력이 안정화되고 완료될 때까지 안정적으로 유지되는 것을 확인했습니다. 따라서 편의상 각 벤치마크 실행 후 15초마다 한 번의 측정값을 사용합니다.
전력 소비에 따른 성능 정규화
실험을 단일 지표로 통합하기 위해, 달성된 최대 처리량을 전력 소비량으로 나누었습니다. 지표는 PSU의 DC 측과 CPU 자체 모두에서 계산되었습니다.
테스트에 대한 최종 성능 측정 기준은 다음과 같습니다.
- CPU Energetic Efficiency: 와트당 Mbit/s(CPU가 소비하는 와트당 처리량)
- System Energetic Efficiency: 와트당 Mbit/s(PSU 손실을 제외한 전체 시스템에서 소비되는 와트당 처리량)
전원 공급 장치에 대한 참고 사항
스위칭 모드 전원 공급 장치 효율에 대한 자세한 논의는 이 문서의 범위를 벗어납니다. 그러나 몇 가지 핵심 사항을 강조하는 것이 중요합니다.
최신 서버 전원 공급 장치는 일반적으로 정격 용량의 20%에서 90%에 이르는 광범위한 부하 범위에서 높은 효율을 달성합니다. 이 범위를 벗어나면 효율이 빠르게 떨어질 수 있습니다. 80 Plus Platinum 인증을 받은 대부분의 최신 PSU는 정격 용량의 20%를 초과하는 부하에서 90% 이상의 효율을 달성해야 합니다. 이는 인상적이지만, 저전력 고효율 CPU를 사용하는 경우에는 그다지 의미가 없을 수 있습니다.
저희 시스템에는 800W 이중화 전원 공급 장치 두 개가 장착되어 있어 총 1600W의 용량을 제공합니다. 정격 효율에 도달하려면 이 전원 공급 장치는 최소 320W(총 용량의 20%)의 부하가 필요합니다. 최신 서버 CPU는 일반적으로 TDP가 100W 이하입니다. 저희 테스트 결과, 최대 부하 상태에서도 모든 시스템이 320W 한계치에 도달하지 못했습니다.
완화 전략
저전력 조건에서 효율성을 개선하기 위해 다음을 구현했습니다.
정격이 낮은 전원 공급 장치를 사용하세요
우리는 합리적인 효율성을 위해 필요한 최소 부하를 줄이면서 원래 800W PSU를 400W 장치로 교체했습니다.
핫 스탠바이 모드 활성화
모든 부하가 첫 번째 PSU에서 발생하고, 두 번째 PSU는 중복성을 위해 상시 대기 상태로 유지되도록 플랫폼 관리를 구성했습니다. 예를 들어, 단일 400W PSU에서 72W를 소비하는 32코어 ARM 시스템은 정격 용량의 18%로 작동했는데, 이는 20% 임계값보다 약간 낮았지만 여전히 82%의 효율을 달성했습니다.
DC 출력을 직접 측정
PSU 효율성의 비선형성을 피하기 위해 이 논문의 모든 전력 효율성 측정 기준은 AC 입력이 아닌 DC 출력 측정을 기반으로 합니다.
PSU 효율성을 고려하는 이점
시스템 전력 입력을 평가하고 이에 따라 PSU를 조정하면 다음이 가능합니다.
- 과도하게 공급되고 값비싼 전원 공급 장치를 피함으로써 CAPEX를 줄입니다.
- 전반적인 효율성을 개선하고, 시스템의 전력 소비와 운영 비용을 낮춰 OPEX를 줄입니다.
결론
본 연구에서는 네트워크 집약적인 워크로드를 중심으로 컴퓨터 시스템 성능과 전력 소비 간의 관계를 평가했습니다. 연구 방법론을 요약하면 다음과 같습니다.
- 시스템 성능 평가
- 성능은 CPU 코어당 달성 가능한 네트워크 처리량으로 측정되었습니다.
- 우리는 CPU 활용도, 최대 처리량, 계산 효율성(완전히 로드된 코어당 처리량)을 고려했습니다.
- 현실적인 성능 동작을 포착하기 위해 단일 프로세스, 다중 프로세스, 포화 상태 등 다양한 운영 체제를 테스트했습니다.
- 하드웨어 지역성을 위한 워크로드 최적화
- 우리는 NUMA 인식을 강조하고, 네트워크 집약적 프로세스와 인터럽트 처리를 로컬 메모리와 PCI 장치에 맞췄습니다.
- 원격 메모리 접근으로 인한 성능 저하를 줄이기 위해 CPU 고정 및 인터럽트 분산이 활용되었습니다.
- 전력 소비량 측정
- 전력은 ipmitool을 통한 플랫폼 관리 인터페이스를 사용하여 모니터링되었으며, 외부 AC/DC 미터로 검증되었습니다.
- CPU 전력과 시스템 전체 전력이 모두 기록되었으며, DC 측 측정을 사용하여 PSU 효율성을 설명했습니다.
- 전력에 대한 성능 정규화
- 마지막 지표는 처리량과 전력 소비를 결합하여 CPU와 시스템 수준의 에너지 효율(Mbit/s/W)을 산출합니다.
- PSU 효율성을 고려하여 저부하 작동을 최적화하고 낭비를 줄이기 위한 전략을 수립했습니다.
- 이 글의 목적은 고객에게 네트워크 성능을 측정하고 전력 사용을 최적화하는 실용적인 방법론을 제공하고, 네트워크 집약적 시스템을 설계, 조정 또는 확장할 때 정보에 입각한 결정을 내릴 수 있도록 돕는 것입니다.
전반적으로 이 접근 방식은 하드웨어 인식 스케줄링, 정확한 전력 측정, 에너지 효율적인 시스템 설계의 중요성을 강조하며, 현대 데이터 센터 환경에 대한 실행 가능한 통찰력을 제공합니다.
