Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://developers.redhat.com/articles/2025/10/13/protecting-virtual-machines-storage-and-secondary-network-node-failures
쿠버네티스는 노드 상태를 모니터링하고 상태 변화에 대응하여 워크로드를 보호하는 기능을 제공합니다. 그러나 이러한 기능은 가상 머신 사용 사례나 통신사 배포처럼 스토리지 및 보조 네트워크를 많이 사용하는 워크로드에는 충분하지 않습니다. 이 글에서는 쿠버네티스의 현재 기능의 한계를 살펴보고 이러한 상황을 개선하기 위한 몇 가지 접근 방식을 제시합니다.
Kubernetes가 노드 문제를 감지하는 방법
노드에 영향을 줄 수 있는 상황을 감지하는 구성 요소는 kubelet 입니다 . kubelet이 수행하는 검사는 문서화되어 있지만, 제어 평면과의 연결이 설정되었는지, 그리고 노드에 Pod를 시작하기에 충분한 리소스(PID, 메모리, 디스크 공간)가 있는지만 확인할 수 있습니다. 또한 kubelet은 준비 상태를 보고하는데, 이는 일반적으로 kubelet 프로세스 자체가 준비된 것으로 해석될 수 있습니다.
문제가 발생하면 상태 섹션에 노드의 상태로 기록됩니다. 예를 들어, 다음은 정상 노드를 나타냅니다(간결성을 위해 일부 필드는 생략됨).
conditions:
- type: MemoryPressure
status: 'False'
reason: KubeletHasSufficientMemory
message: kubelet has sufficient memory available
- type: DiskPressure
status: 'False'
reason: KubeletHasNoDiskPressure
message: kubelet has no disk pressure
- type: PIDPressure
status: 'False'
reason: KubeletHasSufficientPID
message: kubelet has sufficient PID available
- type: Ready
status: 'True'
reason: KubeletReady
message: kubelet is posting ready status노드 컨트롤러는 또한 조건을 테인트로 변환합니다 . 노드에 대한 압력과 관련된 조건은 NoSchedule 테인트로 변환되고, 준비 상태 조건은 NoExecute 테인트로 변환됩니다.
기본적으로 노드의 상태는 제어 평면과의 마지막 성공적인 체크인 후 50초가 지나면 Unknown으로 설정(이에 상응하는 Unreachable 테인트 추가)됩니다.
Kubernetes가 비정상 노드로부터 Pod를 보호하는 방법
기본적으로 포드는 다음과 같은 허용 범위를 받습니다.
- key: node.kubernetes.io/not-ready
operator: Exists
effect: NoExecute
tolerationSeconds: 300
- key: node.kubernetes.io/unreachable
operator: Exists
effect: NoExecute
tolerationSeconds: 300즉, 노드가 준비되지 않거나 접근할 수 없게 되면 해당 노드의 Pod는 300초(5분) 동안 해당 상태를 유지합니다. 그 후 해당 노드에서 강제로 퇴장되고 다른 사용 가능한 노드로 재스케줄링됩니다.
파드가 제거되면 정상적으로 삭제됩니다. 즉, 파드 객체는 kubelet에서 파드가 제거되었다는 확인이 있을 때만 삭제됩니다. 노드가 준비되지 않았거나 다른 이유로 접근할 수 없는 경우에는 확인이 수신되지 않습니다. 정상적인 삭제에는 6분의 제한 시간이 적용됩니다 . 따라서 일반적인 상황에서는 준비되지 않은 노드에서 파드를 삭제하는 데 약 12분(50초 + 5분 + 6분)이 소요됩니다.
메모리에 대한 보장 및 버스트 가능 QoS 클래스의 포드는 또한 다음과 같은 허용 범위를 받습니다.
- key: node.kubernetes.io/memory-pressure
operator: Exists
effect: NoScheduleDaemonSet은 DaemonSet Pod의 일정을 취소할 필요가 없기 때문에 잘 알려진 모든 노드 조건에 대한 허용 범위를 받습니다.
가상 머신에 대한 고려 사항
위에 설명된 이벤트 순서는 가상 머신을 실행하는 포드에도 적용됩니다. 그러나 가상 머신에는 다음과 같은 추가 고려 사항이 필요합니다.
- 여러 가상 머신 인스턴스가 동시에 실행되는 경우 가상 머신 디스크가 불일치하는 것을 방지합니다.
- 노드가 건강하지 않을 때 반응하는 시간을 늘립니다(어떤 경우에는 12분이 너무 깁니다).
노드에 접근할 수 없는 경우, 기본 워크로드의 상태를 파악하기 어려워집니다. 이러한 워크로드가 가상 머신인 경우, 여전히 실행 중이거나 스토리지에 연결되어 있을 수 있습니다.
다른 인스턴스를 시작하기 전에 가상 머신이 어디에서도 실행되고 있지 않은지 확인하는 것이 중요합니다. 스토리지의 일관성을 유지하려면 최소한 원래 가상 머신이 스토리지에 액세스하고 있지 않은지 확인해야 합니다. 비정상 노드로부터 리소스를 격리하는 프로세스를 펜싱이라고 합니다.
노드의 펜싱을 수행하고 해당 노드에 할당된 작업 부하를 다시 시작하도록 구성할 수 있는 연산자가 있습니다.
- Node health check (NHC)
- Self node remediation (SNR)
- Fence agents remediation (FAR)
- Machine deletion remediation (MDR)
그림 1의 다이어그램은 이러한 운영자들이 서로 어떻게 상호작용하는지와 그들의 책임 범위를 보여줍니다.
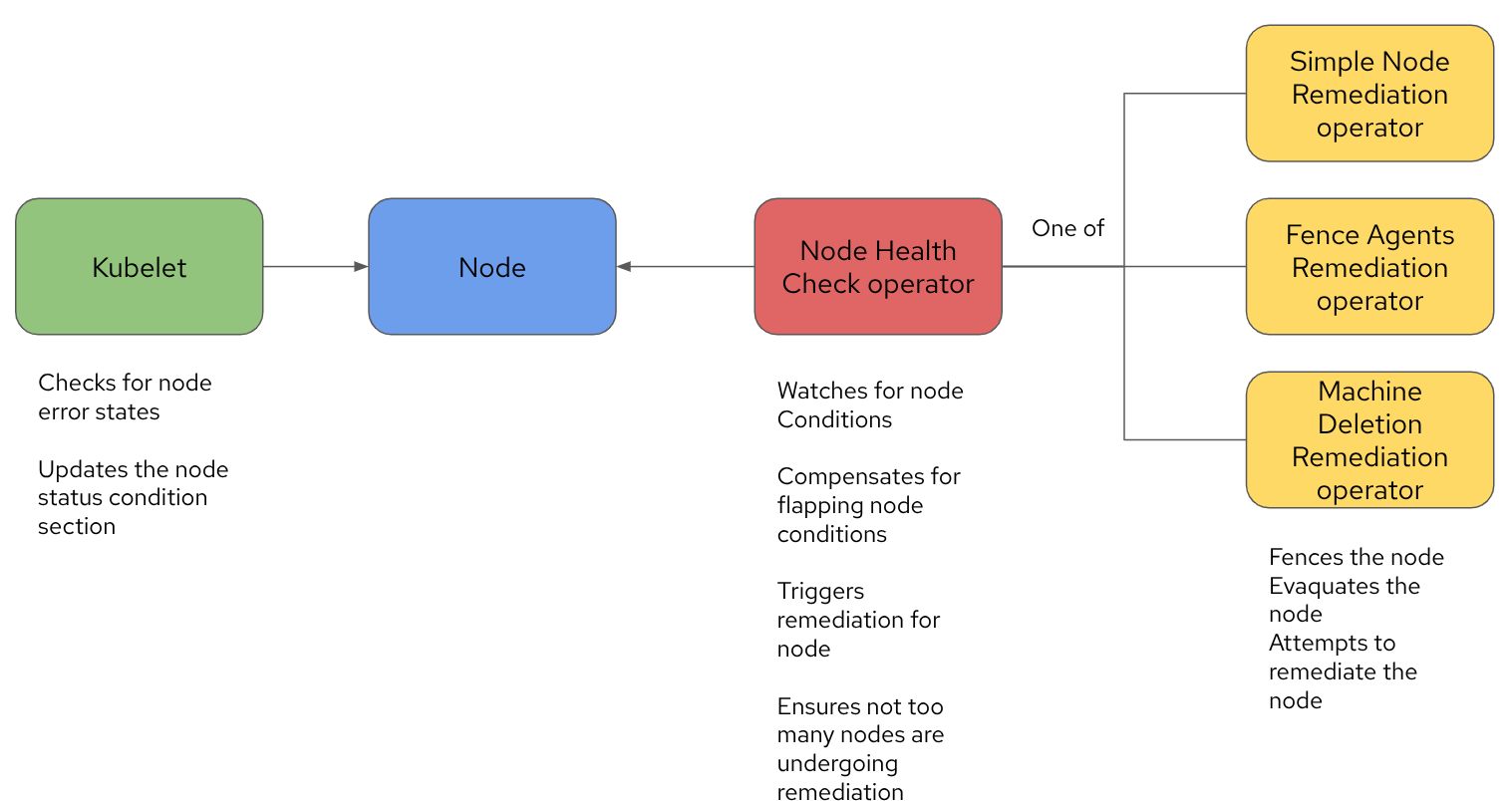
앞서 설명했듯이 Kubelet은 자체 상태 점검(또는 Kubelet이 지정된 임계값 내에서 체크인하지 않을 경우 제어 평면)을 통해 노드에 조건을 설정합니다. NHC는 이러한 조건을 감지하고 적절한 조치를 실행합니다. 또한, 조치를 실행하기 전에 특정 조건이 일정 기간 동안 발생했는지 확인하고 동시에 조치를 받는 노드 수를 제어하는 등의 추가 기능도 제공합니다.
수정 유형이 트리거되면 관련 수정 운영자가 노드를 펜싱하고 워크로드를 다시 시작합니다. 이때 워크로드는 다른 노드에서 다시 예약됩니다.
OpenShift Virtualization을 사용하는 경우, Fence Agent Remediation Operator를 수정하는 것이 좋습니다. FAR은 표준 out-of-service 테인트를 수정 전략으로 사용하도록 구성해야 합니다. out-of-service 테인트는 Pod 및 관련 VolumeAttachment를 즉시 강제 삭제하므로, 가상 머신과 같은 상태 저장 애플리케이션에 빠르고 안전한 전략입니다.
이러한 오퍼레이터를 적극적으로 조정하면(이 기사의 범위를 벗어남) 반응 시간을 약 1분 30 초로 줄일 수 있습니다 .
현재 제한 사항
일반적인 가상 머신 배포는 스토리지와 보조 네트워크를 사용합니다. 가상 머신을 실행하려면 스토리지가 필요하며, 일반적으로 가상 머신은 제어 평면과 다른 네트워크의 네트워크에 노출됩니다. 이를 관리 네트워크라고도 합니다. Kubelet은 기본적으로 제한된 수의 검사만 수행하며, 이러한 검사는 스토리지나 보조 네트워크와 관련이 없습니다. 콘트롤 플레인 연결 상태 검사는 관리 네트워크의 상태를 암묵적으로 검사합니다.
결과적으로 쿠버네티스는 가상 머신의 운영 상태에 중요한 외부 스토리지 또는 보조 네트워크에서 발생하는 문제(노드 노드에 영향을 미칠 수 있는 여러 다른 문제 포함)를 인지하지 못합니다. 스토리지 문제가 발생하면 가상 머신은 스토리지가 복구될 때까지 일시 중지되지만, 가상 머신 포드는 다른 노드로 예약되지 않습니다. 네트워크 문제가 발생하면 일반적으로 VM은 네트워크에서 격리되지만 가상 머신 포드는 해당 노드에서 계속 실행됩니다.
이런 상황에서 가상 머신 health check가 도움이 될 수 있을까요? 이 두 가지 문제를 조사하기 위한 상태 점검을 개발하는 것은 물론 가능하지만, 가상 머신 상태 점검에 실패하면 가상 머신이 다시 시작됩니다. 노드를 사용할 수 없는 것으로 표시하는 것은 아닙니다. 해당 노드에서 가상 머신을 계속 예약할 수 있기 때문에 문제가 더욱 심각해집니다.
그렇다면 문제가 해결될 때까지 노드를 실제로 사용할 수 없음으로 표시하는 솔루션을 어떻게 설계할 수 있을까요?
노드 문제 감지기 연산자
쿠버네티스 커뮤니티는 바로 이 문제에 대한 해결책으로 Node Problem Detector (NPD) 연산자를 개발했습니다. NPD 연산자는 노드에 대한 추가 상태 확인을 수행하고 노드 상태에 관련 조건을 추가하는 데몬셋을 배포합니다. Node Problem Detector operator에 대한 올바른 상태 확인이 정의되어 있다면 이제 스토리지 및 보조 네트워크 문제를 감지하고 대응할 수 있습니다. 아키텍처는 다음과 유사한 설계로 발전합니다.
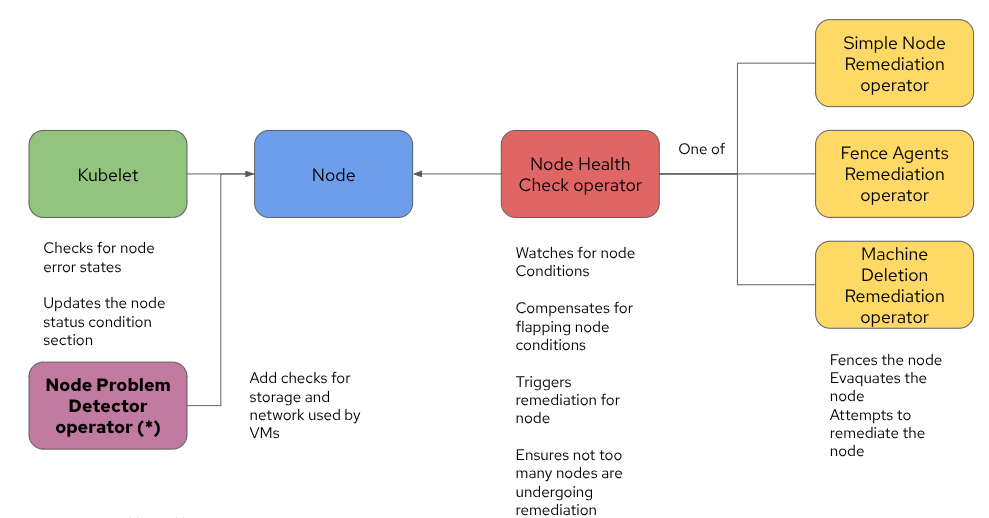
기본적으로 핵심 구성 요소는 동일하게 유지되며, NPD가 추가되어 Kubelet이 노드 수준의 문제를 더 자세히 감지할 수 있게 되었습니다.
NPD 운영자에는 사전 정의된 추가 상태 검사 세트가 포함되어 있으며 사용자 정의 상태 검사를 실행하도록 구성할 수 있습니다.
중요: NPD 운영자는 현재 Red Hat에서 지원되지 않습니다.
노드 상태 점검 설계
Kubelet이 수행하는 기본 노드 상태 점검은 가상 머신 사용 사례에서 스토리지 및 보조 네트워크 문제를 감지하기에 충분하지 않습니다. Node Problem Detector 연산자를 활용하여 스토리지 및 보조 네트워크에 대한 사용자 지정 상태 점검을 설계해 보겠습니다.
스토리지의 경우, 예시 블록 장치가 다중 경로를 통해 제공된다고 가정합니다. SAN 어레이가 포함된 경우, 스토리지가 파이버 채널 (FC) 또는 iSCSI를 통해 제공되는지 여부와 관계없이 이는 거의 항상 적용됩니다 .
보조 네트워크의 경우, VM 네트워크(일반적으로 VLAN)가 모두 노드 수준에서 본딩된 한 쌍의 전용 NIC를 통해 흐른다고 가정합니다. 이는 대부분의 경우 두 개의 NIC가 제어 플레인 네트워크에 사용되고 두 개의 NIC가 가상 머신 트래픽에 사용되기 때문에 매우 일반적인 시나리오입니다.
상태 점검을 설계할 때는 노드 로컬에서 수행하는 것이 좋습니다. 예를 들어, 개별 노드의 네트워크 연결이 끊어진 것을 감지하는 경우입니다. 노드 외부로 프로빙을 확장하고 네트워크 아키텍처 또는 스토리지 구축의 하위 계층까지 포함하는 효과적인 상태 점검을 설계하는 것은 훨씬 어렵습니다.
아래 예제는 Node Problem Detector operator 가이드라인과 사용자 정의 상태 검사 예제를 따라 만들어졌습니다 .
스토리지 상태 점검
스토리지가 다중 경로 장치에 있는 경우, multipath -C <device> 명령은 장치 매퍼가 연결이 활성화되었다고 간주하는지 테스트하는 데 매우 유용합니다.
NPD에 정의된 상태 점검의 간단한 예는 다음과 같습니다.
#!/bin/bash
# This plugin checks if the ntp service is running under systemd.
# NOTE: This is only an example for systemd services.
readonly OK=0
readonly NONOK=1
readonly UNKNOWN=2
# Return success if we can read data from the block device
export device=$(chroot /node-root multipath -ll | grep "NETAPP,LUN" | awk '{print $2}' | shuf | head -n 1)
if chroot /node-root multipath -C $device; then
echo "ontap-san-test is accessible"
exit $OK
else
echo "ontap-san-test is NOT accessible"
exit $NONOK
fi몇 가지 주의할 사항:
- 이 명령어는 노드에서 실행해야 합니다. 더 정확히 말하면, NPD 운영자 포드에서 실행하는 것은 매우 복잡합니다. 노드 자체에서 실행할 경우, 전체 노드 파일 시스템을 마운트하는 경로에 chroot를 사용할 수 있습니다.
- 위에서 설명한 바와 같이, 먼저 특정 유형(이 예시에서는 가상 머신을 지원하는 스토리지 클래스에 의해 생성된 NETAPP, LUN)의 모든 멀티패스 장치를 검색합니다. 그런 다음 결과를 섞은 후, 단일 장치를 선택하여 해당 장치에 대한 상태 점검을 수행합니다. 완벽하지는 않지만, 장치 중 하나를 무작위로 선택하면 노드 내 모든 장치에 영향을 미치는 더 큰 문제가 있는지 여부를 알 수 있습니다. 항상 최소한 하나의 장치가 존재하도록 보장하기 위해, NPD DaemonSet 내에서 해당 스토리지 클래스의 볼륨을 마운트합니다. 모든 DaemonSet 포드 인스턴스가 동일한 장치를 마운트하며, 이는 스토리지 클래스가 반드시 ReadWriteMany(RWX) 액세스 모드를 지원해야 하기 때문에 가능합니다.
다음은 이 상태 점검에 대한 메타데이터를 정의하는 예입니다.
{
"plugin": "custom",
"pluginConfig": {
"invoke_interval": "15s",
"timeout": "3s",
"max_output_length": 80,
"concurrency": 3,
"enable_message_change_based_condition_update": true
},
"source": "ontap-san-custom-plugin-monitor",
"metricsReporting": true,
"conditions": [
{
"type": "OntapSANProblem",
"reason": "OntapSANIsUp",
"message": "Ontap-san connection service is up"
}
],
"rules": [
{
"type": "permanent",
"condition": "OntapSANProblem",
"reason": "OntapSANIsDown",
"path": "./custom-config/ontap-san-check.sh",
"timeout": "3s"
}
]
}노드 문제 감지기 운영자는 이 구성 파일을 사용하여 주기적으로 상태 검사를 실행하고 노드의 상태를 보고합니다.
모든 것이 올바르게 구성된 경우, 정상 노드는 다음과 유사한 조건을 반환합니다.
- type: OntapSANProblem
status: 'False'
lastHeartbeatTime: '2025-09-10T18:04:27Z'
lastTransitionTime: '2025-09-10T01:22:32Z'
reason: OntapSANIsUp
message: Ontap-san connection service is up저장소 문제가 있는 경우 노드 상태는 다음 출력과 유사하게 나타납니다.
- type: OntapSANProblem
status: 'True'
lastHeartbeatTime: '2025-09-10T18:14:18Z'
lastTransitionTime: '2025-09-10T18:14:17Z'
reason: OntapSANIsDown
message: ontap-san-test is NOT accessible네트워크 상태 점검
본딩된 NIC 한 쌍에 대한 네트워크 상태 점검의 경우, 본딩된 NIC의 링크 상태를 테스트할 수 있습니다. 본딩된 NIC 중 하나 이상에 정상 링크가 있으면 본딩된 링크가 정상으로 보고되므로, 이 점검은 적절한 방법입니다. 이 점검은 로컬에서 수행되며, 케이블이 연결되어 있고 본딩된 NIC와 관련 NIC가 올바르게 활성화되어 있는지 확인하는 것과 거의 같습니다. ip link show <device> 명령은 링크 상태를 테스트하는 좋은 방법을 제공합니다. 본딩된 NIC의 장치 이름이 bond0라고 가정하면, 다음 스크립트를 사용하여 상태 점검을 실행할 수 있습니다.
#!/bin/bash # This plugin checks if the ntp service is running under systemd. # NOTE: This is only an example for systemd services. readonly OK=0 readonly NONOK=1 readonly UNKNOWN=2 # Return success if the link is up if ip link show bond0 | grep "state UP" | grep ,UP | grep ,LOWER_UP && exit 0 || exit 1; then echo "bond0 is up" exit $OK else echo "bond0 is down" exit $NONOK fi
명령에서 파이프와 grep 시리즈는 ip link show <device> 명령 출력의 모든 상태가 정상적인 연결을 보고하는지 확인하는 데 사용됩니다.
상태 검사 메타데이터는 다음과 유사합니다.
{
"plugin": "custom",
"pluginConfig": {
"invoke_interval": "10s",
"timeout": "3s",
"max_output_length": 80,
"concurrency": 3,
"enable_message_change_based_condition_update": true
},
"source": "bond0-custom-plugin-monitor",
"metricsReporting": true,
"conditions": [
{
"type": "Bond0Problem",
"reason": "Bond0IsUp",
"message": "Bond0 connection is up"
}
],
"rules": [
{
"type": "permanent",
"condition": "Bond0Problem",
"reason": "Bond0IsDown",
"path": "./custom-config/bond0-check.sh",
"timeout": "3s"
}
]
}건강한 노드는 다음과 비슷한 것을 생성합니다.
- type: Bond0Problem
status: 'False'
lastHeartbeatTime: '2025-09-10T18:04:27Z'
lastTransitionTime: '2025-09-10T01:22:32Z'
reason: Bond0IsUp
message: Bond0 connection is up건강하지 않은 노드는 다음과 같습니다.
- type: Bond0Problem
status: 'True'
lastHeartbeatTime: '2025-09-10T18:14:18Z'
lastTransitionTime: '2025-09-10T18:14:17Z'
reason: Bond0IsDown
message: Bond0 is down구성 마무리
앞서 언급했듯이, 설계한 상태 확인이 제대로 실행되도록 DaemonSet을 약간 변형하여 NPD를 배포해야 합니다. 최소 하나의 다중 경로 장치가 발견되도록 하려면 PVC를 생성하여 DaemonSet 포드에 마운트해야 합니다.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ontap-san-test
labels:
app.kubernetes.io/instance: node-problem-detector
app.kubernetes.io/name: node-problem-detector
spec:
accessModes:
- ReadWriteMany
volumeMode: Block
resources:
requests:
storage: 1Gi # Requests 10 GiB of storage
storageClassName: ontap-sanDaemonSet 포드에 PVC를 추가하려면 다음 구성을 추가하세요.
volumes:
- name: ontap-san-test
persistentVolumeClaim:
claimName: ontap-san-test 컨테이너 장치의 마운트 위치는 중요하지 않습니다. 보셨듯이 컨테이너 내부에서 테스트하지 않고 노드로 chroot하기 때문입니다. 다만 루트 변경을 위해 노드 파일 시스템을 어딘가에 마운트해야 합니다. 방법은 다음과 같습니다:
volumes:
- hostPath:
path: /
name: node-root 그리고 해당 볼륨 마운트를 정의해야 합니다.
volumeMounts:
- mountPath: /node-root
name: node-root bond0 인터페이스를 확인하려면 노드 네트워크 네임스페이스에서 Pod를 실행해야 합니다. 다음 구성을 사용하면 됩니다.
spec: hostNetwork: true
NPD 연산자가 노드에 새로운 조건을 추가하도록 구성되면, 노드 상태 점검 연산자도 해당 조건에 대응하도록 구성할 수 있습니다. 저장소 및 네트워크 관련 조건을 포함하여 업데이트된 구성은 다음과 유사한 출력을 생성합니다.
unhealthyConditions:
- duration: 300s
status: 'False'
type: Ready
- duration: 300s
status: Unknown
type: Ready
- duration: 120s
status: 'True'
type: OntapSANProblem
- duration: 120s
status: 'True'
type: Bond0Problem이 구성을 사용하면 NHC는 Unknown 및 Unready 상태에 반응할 뿐만 아니라 우리가 추가한 두 가지 새로운 상태 검사에도 반응합니다.
Taints 및 Tolerations를 사용하여 솔루션 개선
지금까지 파악된 솔루션은 스토리지 또는 보조 네트워크 관련 문제로 인해 노드 상태가 나빠질 경우 노드를 펜싱(재부팅)합니다. 이 설계는 해당 노드의 모든 포드 또는 가상 머신이 두 가지 유형의 리소스를 모두 사용하는 경우에 적합합니다. 즉, 클러스터가 가상 머신 실행에만 전념하는 경우 위 솔루션은 만족스럽습니다.
하지만 클러스터에 가상 머신과 기존 컨테이너화된 워크로드가 혼합되어 있다면 노드를 제거하는 것이 적절할까요? 노드는 다른 면에서는 정상이며 기존 워크로드를 실행할 수 있습니다. 다른 워크로드는 계속 실행하면서 가상 머신만 노드에서 이동할 수 있는 방법이 있을까요?
테인트와 톨러레이션을 사용하여 이러한 동작을 자동화할 수 있습니다. 일반적으로 테인트는 특정 노드에서 무언가를 실행하거나 예약해서는 안 된다는 것을 암시하는 데 사용되는 반면, 톨러레이션은 (테인트에도 불구하고) 톨러레이션이 적용된 포드가 해당 테인트된 노드에서 실제로 실행될 수 있음을 암시하는 데 사용될 수 있습니다. 다시 말해, 테인트는 포드를 노드에서 밀어내고, 톨러레이션은 그러한 밀어내는 힘을 무력화합니다.
이 전략을 구현하려면 다음과 같은 자동화가 필요합니다.
- 노드에
OntapSANProblem또는Bond0Problem유형의 조건이 있는 경우, 노드에NoExecute유형의 테인트를 추가해야 합니다. 조건이 해결되면 테인트를 제거해야 합니다. - 팟이 생성될 때 PVC 스토리지 클래스 ontap-san을 가진 볼륨이 없는 경우, OntapSANProblem 테인트에 대한 톨러레이션이 추가됩니다.
- 마찬가지로, 생성된 포드가 vlan-으로 시작하는 보조 네트워크를 사용하지 않을 경우, Bond0Problem 테인트에 톨러레이션을 추가합니다(네트워크 연결 정의에서 bond0을 사용하는 경우 모두 vlan-으로 시작한다는 명명 규칙을 가정함).
정책 엔진을 사용하여 이러한 자동화를 구현할 수 있습니다. Kyverno 는 적합한 기능을 갖춘 정책 엔진입니다. 다음은 조건에 따라 노드에 테인트를 추가하는 정책 예시입니다(간략하게 설명하기 위해 보조 네트워크 조건에 대한 정책만 보여드립니다).
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: taint-node-on-bond0-condition
spec:
admission: true
background: false
emitWarning: false
rules:
- match:
any:
- resources:
kinds:
- Node/status
operations:
- UPDATE
preconditions:
all:
- key: "{{ request.object.status.conditions || `[]` | [?type == 'Bond0Problem'].status | [0] || 'NotFound' }}"
operator: Equals
value: "True"
- key: "Bond0Problem"
operator: AllNotIn
value: "{{ request.object.spec.taints[].key || `[]` }}"
mutate:
patchesJson6902: |-
- path: "/spec/taints/-"
op: add
value:
key: Bond0Problem
value: "true"
effect: NoSchedule
targets:
- apiVersion: v1
kind: Node
name: '{{ request.object.metadata.name }}'
name: set-node-taint
skipBackgroundRequests: trueKyverno는 기본적으로 노드를 감시하지 않으므로 Kyverno 설정에서 노드를 명시적으로 활성화해야 합니다. 또한, 해당 조건이 사라지면 해당 오염을 제거하는 유사한 정책이 있어야 합니다(이러한 조건에 대한 매니페스트는 이 문서의 범위를 벗어납니다).
다음은 보조 네트워크를 사용하지 않는 포드에 허용 범위를 추가하는 정책의 예입니다.
apiVersion: policies.kyverno.io/v1alpha1
kind: MutatingPolicy
metadata:
name: tolerate-bond0-problem
spec:
autogen:
mutatingAdmissionPolicy:
enabled: false
podControllers:
controllers: []
matchConstraints:
resourceRules:
- apiGroups: [ "" ]
apiVersions: [ "v1" ]
operations: ["CREATE", "UPDATE"]
resources: [ "pods" ]
failurePolicy: Ignore
reinvocationPolicy: IfNeeded
evaluation:
admission:
enabled: true
matchConditions:
- name: no-networks-whose-name-starts-with-vlan
expression: |-
!( object.metadata.namespace.startsWith('kube-') ||
object.metadata.namespace.startsWith('openshift-') ||
object.metadata.namespace.endsWith('-system') ||
object.metadata.namespace == 'default' ||
object.metadata.namespace == 'kyverno') &&
(! has(object.metadata.annotations) ||
! ('k8s.v1.cni.cncf.io/networks' in object.metadata.annotations) ||
! object.metadata.annotations['k8s.v1.cni.cncf.io/networks'].contains('\"name\":') ||
object.metadata.annotations['k8s.v1.cni.cncf.io/networks'].findAll('\"name\":\"([^\"]*)\"').map(s,s.split(':')[1].substring(1,s.split(':')[1].size()-1)).filter(name, name.startsWith('vlan-')).size() == 0)
mutations:
- patchType: JSONPatch
jsonPatch:
expression: |
has(object.spec.tolerations) ?
[
JSONPatch{
op: "add",
path: "/spec/tolerations/-",
value: {
"key": "Bond0Problem",
"operator": "Exists",
"effect": "NoExecute"
}
}
] :
[
JSONPatch{
op: "add",
path: "/spec/tolerations",
value: {
"key": "Bond0Problem",
"operator": "Exists",
"effect": "NoExecute"
}
}
]가상 머신 보호
이 글에서는 특히 가상 머신 사용 사례에서 노드 장애 발생 시 발생하는 활동 유형을 설명했습니다. 노드 장애 상황 처리를 위한 몇 가지 권장 사례를 간략하게 설명했습니다. 또한 쿠버네티스가 무시하는 몇 가지 장애 유형, 즉 보조 네트워크 장애와 스토리지 장애를 파악했습니다.
이 글은 가상 머신을 호스팅하는 환경에서 작업할 때 발생하는 이러한 문제에 대한 적절한 해결책을 제시했습니다. 또한, 가상 머신과 기존 워크로드를 모두 지원하는 아키텍처를 개발하고 설계를 개선했습니다.
