Ceph Blog(https://ceph.io/en/news/blog/)를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다. 출처: https://ceph.io/en/news/blog/2025/stretch-cluuuuuuuuusters-part2/

소개¶
1부 에서는 Ceph 복제 전략의 기본 개념을 소개하고, 데이터 손실 제로(RPO=0)를 달성하기 위한 스트레치 클러스터의 이점을 강조했습니다. 2부에서는 cephadm을 사용하여 두 사이트 스트레치 클러스터와 타이브레이커 모니터를 구축하는 실질적인 단계에 대해 중점적으로 살펴보겠습니다.
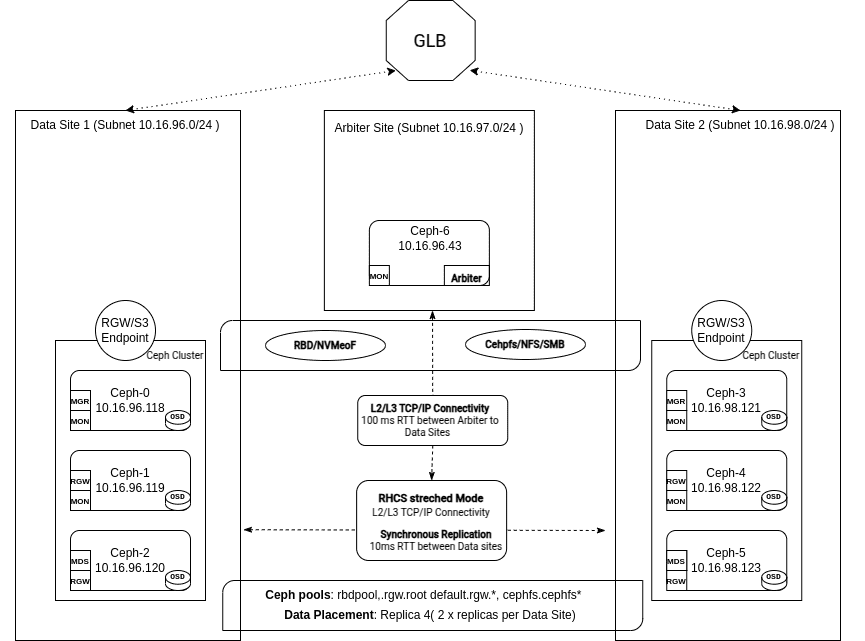
네트워크 고려사항¶
네트워크 아키텍처¶
스트레치 아키텍처 에서 네트워크는 클러스터의 전반적인 상태와 성능을 유지하는 데 중요한 역할을 합니다.
- Ceph는 레벨 3 라우팅 기능을 갖추고 있어 각 데이터 센터/사이트의 서브넷과 CIDR을 통해 Ceph 서버와 구성 요소 간 통신을 가능하게 합니다.
- Ceph 독립형 또는 스트레치 클러스터는 두 개의 별도 네트워크로 구성될 수 있습니다.
- 공용 네트워크 : 모니터, OSD, RGW 등을 포함한 모든 Ceph 클라이언트 및 서비스 간 통신에 사용됨
- 클러스터 네트워크 : 프로비저닝 시(선택 사항), 클러스터 ( 복제 , 백엔드 , 사설 네트워크 라고도 함 )는 OSD 간에 하트비트, 복구 및 복제를 위해서만 사용되므로 OSD가 위치한 데이터 사이트에만 프로비저닝하면 됩니다. 더 나아가, 이 선택적 복제 네트워크는 더 큰 인터네트워크로의 기본 경로(게이트웨이)를 가질 필요가 없습니다.
공개 및 클러스터 네트워크 고려 사항¶
- 모든 Ceph 서비스가 단일 공용 네트워크에 의존하므로, 타이브레이커 사이트를 포함한 세 사이트 모두 에서 단일 공용 네트워크 에 액세스할 수 있어야 합니다 .
- 클러스터 네트워크는 OSD를 수용하는 두 사이트에만 필요하며, 타이브레이커 사이트에서는 구성하면 안 됩니다.
네트워크 안정성¶
OSD 사이트 간의 네트워킹이 불안정하면 클러스터의 가용성 및 성능 문제가 발생합니다.
- 네트워크는 항상 100% 접근 가능해야 할 뿐만 아니라 일관된 지연 시간(낮은 지터 )도 제공해야 합니다.
- 지연 시간이 자주 급증하면 클러스터가 불안정해지고, OSD 플래핑, 모니터 쿼럼 손실, 느린(차단된) 요청 등의 문제로 클라이언트 성능에 영향을 미칠 수 있습니다.
지연 시간 요구 사항¶
- OSD가 위치한 데이터 사이트 간에는 최대 10ms의 RTT(네트워크 패킷 왕복 시간)가 허용됩니다.
- 최대 100ms의 RTT가 타이브레이커 사이트에 허용되며, 보안 정책이 허용하는 경우 VM으로 배포하거나 대규모 공급자에게 배포할 수 있습니다.
타이브레이커 노드가 클라우드에 있거나 WAN을 통한 원격 네트워크에 있는 경우 다음을 권장합니다.
- 데이터 사이트와 공용 네트워크의 타이브레이커 사이트 간에 VPN을 설정합니다.
- Ceph Messenger v2 암호화를 사용하여 전송 중 암호화를 활성화하면 Monitor와 다른 Ceph 구성 요소 간의 통신이 보호됩니다.
지연 시간이 성능에 미치는 영향¶
- Ceph의 모든 쓰기 작업은 강력한 일관성을 유지합니다. 쓰기 데이터는 관련 배치 그룹의 동작 집합에 구성된 모든 OSD에 저장되어야 클라이언트에게 성공 여부를 알릴 수 있습니다.
- 이렇게 하면 모든 클라이언트 쓰기 작업의 지연 시간에 사이트 간 네트워크의 RTT(왕복 시간)가 최소한 추가됩니다. 기본 OSD에서 보조 OSD로의 이러한 복제 쓰기( 하위 작업 )는 병렬로 수행됩니다.
참고: 예를 들어, 사이트 간 RTT가 6ms인 경우 모든 쓰기 작업에는 사이트 간 복제로 인해 최소 6ms의 추가 대기 시간이 발생합니다.
처리량 및 복구 고려 사항 ¶
- 사이트 간 대역폭(처리량)은 다음을 제한합니다.
- 최대 클라이언트 처리량.
- OSD, 노드 또는 사이트가 실패하거나 이후 다시 사용 가능해질 때 복구 속도
- 노드에 장애가 발생하면 복구 트래픽의 67%가 원격으로 발생하는데, 이는 다른 사이트의 OSD에서 데이터의 3분의 2를 읽어 클라이언트 IO와 함께 공유 사이트 간 대역폭을 소모한다는 의미입니다.
- Ceph는 각 배치 그룹(PG)에 기본 OSD를 지정합니다. 모든 클라이언트 쓰기는 이 기본 OSD를 통해 처리되며, 이 OSD는 클라이언트 또는 RGW 인스턴스와 다른 데이터 센터에 있을 수 있습니다.
read_from_local_replica를 사용하여 읽기 최적화¶
- 기본적으로 모든 읽기 작업은 기본 OSD를 거쳐 진행되므로 사이트 간 지연 시간이 늘어날 수 있습니다.
- 이 기능을 사용하면 RGW 및 RBD 클라이언트가 항상 기본 OSD(반대 사이트에 있을 확률이 50%임)
read_from_local_replica에서 읽는 대신 동일한(로컬) 사이트의 복제본에서 읽을 수 있습니다 . - 이를 통해 사이트 간 지연 시간이 최소화되고, 사이트 간 대역폭 사용량이 줄어들며, 읽기 작업이 많은 작업의 성능이 향상됩니다.
- Squid부터 블록(RBD) 및 객체(RGW) 스토리지 모두에 사용 가능합니다. CephFS 클라이언트에서는 로컬 읽기 기능이 아직 구현되지 않았습니다.
하드웨어 요구 사항¶
스트레치 클러스터에 대한 하드웨어 요구 사항 및 권장 사항은 아래에서 설명할 몇 가지 예외 사항을 제외하면 기존(독립형, 비스트레치) 배포와 동일합니다.
- 스트레치 모드의 Ceph는 올플래시(SSD) 구성을 권장합니다. 모든 스트레치 Ceph 클러스터 역할에는 HDD 미디어를 사용하지 않는 것이 좋습니다. 경고를 받았습니다.
- 스트레치 모드의 Ceph는 데이터 복제 정책으로
size=4복제를 요구합니다. 삭제 코딩이나 더 적은 수의 복사본을 사용한 복제는 지원되지 않습니다. 프로비저닝해야 하는 원시 및 사용 가능한 스토리지 용량을 적절히 계획하세요. - 여러 장치 클래스가 있는 클러스터는 지원되지 않습니다.
type replicated class hdd를 포함하는 CRUSH 규칙은 작동하지 않습니다. CRUSH 규칙에 장치 클래스가 지정되어 있는 경우(일반적으로는ssd이지만 잠재적으로nvme) 모든 CRUSH 규칙에서 해당 장치 클래스를 지정해야 합니다. - 로컬 전용 비확장형 풀은 지원되지 않습니다. 즉, 어느 사이트도 다른 사이트로 확장되지 않는 풀을 제공할 수 없습니다.
구성 요소 배치¶
모니터, OSD, RGW를 포함한 Ceph 서비스는 단일 장애 지점을 제거하고 클러스터가 클라이언트의 데이터 액세스에 영향을 미치지 않고 전체 사이트의 손실을 견딜 수 있도록 배치해야 합니다.
- Monitors : 최소 5개의 모니터가 필요하며, 데이터 사이트당 2명, 그리고 순위 결정 사이트에 1개가 필요합니다. 이 전략은 전체 사이트가 오프라인 상태일 때에도 모니터의 50% 이상을 사용할 수 있도록 하여 정족수를 유지합니다.
- Manager : 데이터 사이트당 두 개 또는 네 개의 관리자를 구성할 수 있습니다. 데이터 사이트 장애 발생 시, 정상 운영되는 사이트에 액티브/패시브 쌍을 구성하여 고가용성을 제공하기 위해 네 개의 관리자를 사용하는 것이 좋습니다.
- OSD : 데이터 사이트에 균등하게 분산됩니다. 스트레치 모드를 구성할 때는 사용자 지정 CRUSH 규칙을 생성하여 각 사이트에 두 개의 사본을 배치해야 하며, 두 사이트 스트레치 클러스터의 경우 총 네 개의 사본을 배치해야 합니다.
- RGW : 사이트 장애 발생 시 나머지 사이트에서 개체 스토리지의 높은 가용성을 보장하기 위해 최소 4개의 RGW 인스턴스(데이터 사이트당 2개)가 권장됩니다.
- MDS : CephFS 메타데이터 서버 인스턴스의 최소 권장 개수는 데이터 사이트당 두 개씩, 총 4개입니다. 사이트 장애 발생 시에도 나머지 사이트에는 두 개의 MDS 서비스가 유지되며, 하나는 활성 상태이고 다른 하나는 대기 상태로 유지됩니다.
- NFS : 사이트가 오프라인이 될 때 공유 파일 시스템의 높은 가용성을 보장하기 위해 최소한 데이터 사이트당 2개씩, 총 4개의 NFS 서버 인스턴스가 권장됩니다.
실습: 두 개의 데이터 센터 스트레치 모드 배포.¶
cephadm 배포 도구를 사용하여 클러스터 부트스트랩 프로세스를 진행하는 동안 서비스 정의 YAML 파일을 활용하여 대부분의 클러스터 구성을 단일 단계로 처리할 수 있습니다.
아래 stretched.yaml파일은 스트레치 모드로 구성된 Ceph 클러스터를 배포하기 위한 예시 템플릿을 제공합니다. 이는 예시일 뿐이며, 특정 배포의 세부 정보와 요구 사항에 맞게 사용자 정의해야 합니다.
service_type: host
addr: ceph-node-00.cephlab.com
hostname: ceph-node-00
labels:
- mon
- osd
- rgw
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-01.cephlab.com
hostname: ceph-node-01
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-02.cephlab.com
hostname: ceph-node-02
labels:
- osd
- rgw
location:
root: default
datacenter: DC1
---
service_type: host
addr: ceph-node-03.cephlab.com
hostname: ceph-node-03
labels:
- mon
- osd
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-04.cephlab.com
hostname: ceph-node-04
labels:
- mon
- mgr
- osd
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-05.cephlab.com
hostname: ceph-node-05
labels:
- osd
- rgw
- mds
location:
root: default
datacenter: DC2
---
service_type: host
addr: ceph-node-06.cephlab.com
hostname: ceph-node-06
labels:
- mon
---
service_type: mon
service_name: mon
placement:
label: mon
spec:
crush_locations:
ceph-node-00:
- datacenter=DC1
ceph-node-01:
- datacenter=DC1
ceph-node-03:
- datacenter=DC2
ceph-node-04:
- datacenter=DC2
ceph-node-06:
- datacenter=DC3
---
service_type: mgr
service_name: mgr
placement:
label: mgr
---
service_type: mds
service_id: cephfs
placement:
label: "mds"
---
service_type: osd
service_id: all-available-devices
service_name: osd.all-available-devices
spec:
data_devices:
all: true
placement:
label: "osd"
배포에 맞게 사용자 정의된 사양 파일을 사용하여 cephadm bootstrap 명령을 실행합니다 . 모든 서비스가 한 번에 배포되고 구성되도록 YAML 사양 파일 --apply-spec stretched.yml 와 함께 을 전달합니다 .
# cephadm bootstrap --registry-json login.json --dashboard-password-noupdate --mon-ip 192.168.122.12 --apply-spec stretched.yml --allow-fqdn-hostname
완료되면 클러스터가 모든 호스트와 해당 레이블을 인식하는지 확인하세요.
# ceph orch host ls HOST ADDR LABELS STATUS ceph-node-00 192.168.122.12 _admin,mon,osd,rgw,mds ceph-node-01 192.168.122.179 mon,mgr,osd ceph-node-02 192.168.122.94 osd,rgw,mds ceph-node-03 192.168.122.180 mon,osd,mds ceph-node-04 192.168.122.138 mon,mgr,osd ceph-node-05 192.168.122.175 osd,rgw,mds ceph-node-06 192.168.122.214 mon
각 데이터 센터의 최소 한 노드에 _admin 레이블을 추가하여 Ceph CLI 명령을 실행할 수 있도록 하세요. 이렇게 하면 전체 데이터 센터가 손실되더라도 작동 중인 호스트에서 Ceph 관리 명령을 실행할 수 있습니다. 모든 클러스터 노드에 _admin 레이블을 지정하는 것은 흔한 일입니다 .
# ceph orch host label add ceph-node-03 _admin Added label _admin to host ceph-node-03 # ceph orch host label add ceph-node-06 _admin Added label _admin to host ceph-node-06 # ssh ceph-node-03 ls /etc/ceph ceph.client.admin.keyring ceph.conf
실습: Ceph는 어떻게 사이트당 두 개의 데이터 사본을 작성하나요?¶
Ceph를 스트레치 모드로 구성하면 모든 풀에서 복제 데이터 보호 전략을 size=4와 함께 사용해야 합니다. 즉, 각 사이트에 두 개의 데이터 사본이 저장되므로 전체 사이트가 다운될 경우에도 가용성을 보장할 수 있습니다.
Ceph는 CRUSH 맵을 사용하여 데이터 복제본의 저장 위치를 결정합니다. CRUSH 맵은 datacenters, rooms, 그리고 가장 흔히 racks과 hosts로 구성된 버킷 유형의 계층 구조로 물리적 하드웨어 레이아웃을 논리적으로 표현합니다. 스트레치 모드 CRUSH 맵을 구성하려면 기본 CRUSH 루트 아래에 두 개의 datacenters를 정의한 후, 해당 datacenters CRUSH 버킷 내에 호스트 버킷을 배치합니다.
다음 예시는 두 개의 데이터센터 DC1과 DC2를 포함하는 스트레치 모드 CRUSH 맵을 보여줍니다. 각 데이터센터에는 세 개의 Ceph OSD 호스트가 있습니다. 부트스트랩 과정에서 사용한 사양 파일 덕분에 이 토폴로지를 바로 사용할 수 있습니다. 이 파일에는 CRUSH 맵에서 각 호스트의 위치가 지정되어 있습니다.
# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.58557 root default -3 0.29279 datacenter DC1 -2 0.09760 host ceph-node-00 0 hdd 0.04880 osd.0 up 1.00000 1.00000 1 hdd 0.04880 osd.1 up 1.00000 1.00000 -4 0.09760 host ceph-node-01 3 hdd 0.04880 osd.3 up 1.00000 1.00000 7 hdd 0.04880 osd.7 up 1.00000 1.00000 -5 0.09760 host ceph-node-02 2 hdd 0.04880 osd.2 up 1.00000 1.00000 5 hdd 0.04880 osd.5 up 1.00000 1.00000 -7 0.29279 datacenter DC2 -6 0.09760 host ceph-node-03 4 hdd 0.04880 osd.4 up 1.00000 1.00000 6 hdd 0.04880 osd.6 up 1.00000 1.00000 -8 0.09760 host ceph-node-04 10 hdd 0.04880 osd.10 up 1.00000 1.00000 11 hdd 0.04880 osd.11 up 1.00000 1.00000 -9 0.09760 host ceph-node-05 8 hdd 0.04880 osd.8 up 1.00000 1.00000 9 hdd 0.04880 osd.9 up 1.00000 1.00000
여기에는 DC1과 DC2 두 개의 데이터 센터가 있습니다. 세번째 데이터 센터 DC3에는 타이브레이커 모니터가 ceph-node-06에 있지만 OSD는 없습니다.
사이트당 두 개의 사본을 갖는다는 목표를 달성하기 위해, Ceph RADOS 풀에 할당할 확장된 CRUSH 규칙을 정의합니다.
- 여기서는 RHEL 시스템에서
crushtool바이너리를 얻기 위해ceph-base패키지를 설치합니다.
# dnf -y install ceph-base
- CRUSH 맵을 바이너리 파일로 내보내기
# ceph osd getcrushmap > crush.map.bin
- CRUSH 맵을 텍스트 파일로 디컴파일합니다.
# crushtool -d crush.map.bin -o crush.map.txt
- 파일 끝에 새 규칙을 추가하려면
crush.map.txt파일을 편집하고 숫자 규칙id속성이 고유해야 한다는 점에 유의하세요.
rule stretch_rule {
id 1
type replicated
step take default
step choose firstn 0 type datacenter
step chooseleaf firstn 2 type host
step emit
}

- 클러스터에서 규칙을 사용할 수 있도록 증강된 CRUSH 맵을 주입합니다.
# crushtool -c crush.map.txt -o crush2.map.bin # ceph osd setcrushmap -i crush2.map.bin
- 새로운 규칙을 사용할 수 있는지 확인하세요.
# ceph osd crush rule ls replicated_rule stretch_rule
실습: 스트레치 모드를 위한 모니터 구성¶
부트스트랩 사양 파일 덕분에 모니터는 소속된 데이터 센터에 따라 레이블이 지정됩니다. 이러한 레이블 지정을 통해 Ceph는 한 데이터 센터에 장애가 발생하더라도 쿼럼을 유지할 수 있습니다. 이러한 경우, 순위 결정 모니터는 DC 3나머지 모니터 및 남은 데이터 사이트와 협력하여 클러스터의 모니터 쿼럼을 유지합니다.
# ceph mon dump | grep location
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
세 개의 사이트로 구성된 스트레치 클러스터를 실행할 때, 비대칭 네트워크 오류가 발생하면 한 사이트와 두 번째 사이트 간의 통신만 영향을 받습니다. 이로 인해 해결할 수 없는 모니터 선거 폭풍이 발생하여 어떤 모니터도 리더로 선택되지 않을 수 있습니다.

이 문제를 방지하기 위해 기존 방식에서 연결 기반 방식으로 선거 전략을 변경합니다. 연결 모드는 각 모니터가 피어에 제공하는 연결 점수를 평가하여 가장 높은 점수를 받은 모니터를 선출합니다. 이 모델은 네트워크 분할( netsplit) 을 처리하도록 특별히 설계되었습니다 . 클러스터가 여러 데이터 센터에 분산되어 있고 한 사이트를 다른 사이트로 연결하는 모든 링크가 끊어지면 네트워크 분할이 발생할 수 있습니다.
# ceph mon dump | grep election election_strategy: 1 # ceph mon set election_strategy connectivity # ceph mon dump | grep election election_strategy: 3
다음 형식의 명령을 사용하여 모니터 점수를 확인할 수 있습니다.
# ceph daemon mon.{name} connection scores dump
모니터 연결 선거 전략에 대해 자세히 알아보려면 Greg Farnum의 훌륭한 영상을 시청하세요. 더 자세한 정보는 여기에서도 확인할 수 있습니다.
실습: Ceph Stretch 모드 활성화¶
스트레치 모드를 시작하려면 다음 명령을 실행하세요.
# ceph mon enable_stretch_mode ceph-node-06 stretch_rule datacenter
어디:
- ceph-node-06은 DC3의 타이브레이커(중재자) 모니터입니다.
- stretch_rule 은 각 데이터 센터에 두 개의 사본을 적용하는 CRUSH 규칙입니다.
- 데이터 센터 는 우리의 실패 도메인입니다
업데이트된 MON 구성을 확인하세요.
# ceph mon dump
epoch 20
fsid 90441880-e868-11ef-b468-52540016bbfa
last_changed 2025-02-11T14:44:10.163933+0000
created 2025-02-11T11:08:51.178952+0000
min_mon_release 19 (squid)
election_strategy: 3
stretch_mode_enabled 1
tiebreaker_mon ceph-node-06
disallowed_leaders ceph-node-06
0: [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] mon.ceph-node-00; crush_location {datacenter=DC1}
1: [v2:192.168.122.214:3300/0,v1:192.168.122.214:6789/0] mon.ceph-node-06; crush_location {datacenter=DC3}
2: [v2:192.168.122.138:3300/0,v1:192.168.122.138:6789/0] mon.ceph-node-04; crush_location {datacenter=DC2}
3: [v2:192.168.122.180:3300/0,v1:192.168.122.180:6789/0] mon.ceph-node-03; crush_location {datacenter=DC2}
4: [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] mon.ceph-node-01; crush_location {datacenter=DC1}
Ceph는 타이브레이커 모니터가 리더 역할을 수행하는 것을 명시적으로 금지합니다. 타이브레이커의 유일한 목적은 하나의 기본 사이트에 장애가 발생할 경우 쿼럼을 유지하기 위한 추가 투표를 제공하여 스플릿 브레인(split-brain) 시나리오를 방지하는 것입니다. 설계상 타이브레이커 모니터는 별도의, 종종 규모가 작은 환경(예: 클라우드 VM)에 상주하며 네트워크 지연 시간이 길어지고 리소스가 부족할 수 있습니다. 타이브레이커 모니터가 리더 역할을 수행하도록 허용하면 성능과 일관성이 저하될 수 있습니다. 따라서 Ceph는 타이브레이커 모니터를 disallowed\leader로 표시하여 데이터 사이트가 타이브레이커 쿼럼 투표의 이점을 누리면서 클러스터의 기본 제어권을 유지하도록 합니다.
실습: 스트레치 모드가 활성화된 경우 풀 복제 및 배치 확인¶
스트레치 모드가 활성화되면, 객체 스토리지 데몬(OSD)은 데이터 센터를 피어링할 때만 배치 그룹(PG)을 활성화합니다(두 데이터 센터 모두 사용 가능한 경우). 다음과 같은 제약 조건이 적용됩니다.
- 복제본 수(각 풀의
size속성)는 기본값에서 3에서 4로증가하며 각 사이트에는 두 개의 복제본이 있을 것으로 예상됩니다. - OSD는 동일한 데이터 센터 내의 모니터에만 연결할 수 있습니다.
- 새로운 모니터는 위치가 지정되지 않으면 클러스터에 가입할 수 없습니다.
# ceph osd pool ls detail pool 1 '.mgr' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 12.12 pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
특정 풀 ID에 대한 배치 그룹(PG)을 검사하고 어떤 OSD가 작동 세트에 있는지 확인하세요.
# ceph pg dump pgs_brief | grep 2.c dumped pgs_brief 2.c active+clean [2,3,6,9] 2 [2,3,6,9] 2
이 예에서 PG 2.c는 DC1의 OSD 2와 3, DC2의 OSD 6과 9를 갖습니다.
ceph osd tree 명령을 사용하면 해당 OSD의 위치를 확인할 수 있습니다.
# ceph osd tree | grep -Ev '(osd.1|osd.7|osd.5|osd.4|osd.0|osd.8)' ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.58557 root default -3 0.29279 datacenter DC1 -2 0.09760 host ceph-node-00 -4 0.09760 host ceph-node-01 3 hdd 0.04880 osd.3 up 1.00000 1.00000 -5 0.09760 host ceph-node-02 2 hdd 0.04880 osd.2 up 1.00000 1.00000 -7 0.29279 datacenter DC2 -6 0.09760 host ceph-node-03 6 hdd 0.04880 osd.6 up 1.00000 1.00000 -8 0.09760 host ceph-node-04 -9 0.09760 host ceph-node-05 9 hdd 0.04880 osd.9 up 1.00000 1.00000
여기서 각 PG에는 DC1에 2개의 복제품이 있고 , DC2에 2개의 복제품이 있는데, 이는 스트레치 모드의 핵심 개념입니다.
결론¶
두 사이트 스트레치 클러스터를 세 번째 사이트 타이브레이커 모니터와 함께 구축하면 전체 데이터 센터의 운영 중단 시에도 데이터의 높은 가용성을 유지할 수 있습니다. 단일 사양 파일을 활용하면 모니터, OSD 및 기타 Ceph 구성 요소를 포함하여 두 사이트 모두에 걸쳐 자동적이고 일관된 서비스 배치가 가능합니다. 연결 선택 전략은 또한 잘 연결된 모니터의 우선순위를 지정하여 안정적인 쿼럼을 유지하는 데 도움이 됩니다. 신중한 CRUSH 구성, 정확한 레이블 지정, 적절한 데이터 보호 전략이라는 요소를 결합하면 데이터 무결성이나 서비스 연속성을 저해하지 않고 사이트 간 장애를 처리하는 복원력 있는 스토리지 아키텍처가 구축됩니다.
시리즈의 마지막 부분 에서는 실제 장애 상황에서 스트레치 클러스터를 테스트해 보겠습니다. 전체 사이트가 오프라인 상태가 되면 Ceph가 자동으로 성능 저하 상태로 전환되는 방식, 장애 발생 시 클라이언트 I/O에 미치는 영향, 그리고 사이트 복구 후 데이터 손실을 방지하는 복구 프로세스에 대해 살펴보겠습니다.
저자는 이 게시물을 작성하는 데 시간을 할애하여 커뮤니티를 지원해 준 IBM에 감사드리고 싶습니다.
