Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://developers.redhat.com/articles/2024/06/19/red-hat-openshift-data-foundation-topology-considerations
Red Hat OpenShift Data Foundation을 사용하여 스토리지 클러스터를 설정할 때는 여러 가지 요소를 고려해야 합니다 . 이 문서에서는 OpenShift Data Foundation의 프로덕션급 복원력 있고 확장 가능한 배포를 구축할 때 고려해야 할 몇 가지 세부 사항을 자세히 살펴봅니다. 적합한 배포 아키텍처를 설계하고 구축하려면 다음 사항을 면밀히 살펴봐야 합니다.
- 아키텍처/토폴로지/디자인 측면에서 기본 플랫폼 환경은 어떻게 생겼나요?
- 어떤 기본 저장소가 사용 가능하며, 어떻게 제공됩니까?
- 복제 옵션.
OpenShift Data Foundation을 처음 사용하시는 경우, 아키텍처 문서를 참조하여 운영자가 제공하는 기능과 기능을 간략하게 이해하시기 바랍니다. OpenShift Data Foundation은 내부적으로 Rook과 Ceph를 사용합니다. Ceph에 익숙하지 않으시다면, Ceph는 기본적으로 상용 하드웨어에 설치되도록 설계된 소프트웨어 정의 스토리지 시스템으로, 디스크가 연결된 여러 대의 물리적 서버가 클러스터링되도록 설계되었습니다. Ceph 소개를 먼저 살펴보고 핵심 아키텍처 와 구성 요소 를 미리 파악하여 개념에 익숙해지는 것이 좋습니다.
쿠버네티스에서 Ceph를 실행하면 OpenShift Data Foundation이 배포를 자동화하지만, 이것이 만능 해결책은 아닙니다. 클러스터가 기반 인프라 전반에 어떻게 분산되어 있는지, 그리고 실제 스토리지의 출처를 파악하는 것은 성공적인 설계 및 배포를 위해 매우 중요합니다.
참고로, 지원 가능성에 대한 구체적인 내용을 보려면 knowledge-centered service (KCS) 문서인 Red Hat OpenShift Data Foundation 4.X에 지원되는 구성에서 무엇을 할 수 있고 무엇을 할 수 없는지에 대한 혼동을 다루어야 합니다.
토폴로지
스토리지가 기존 동적 스토리지 클래스를 통해 제공되거나 직접 연결된 디스크를 통해 제공되는 방식과 관계없이, 내결함성 토폴로지를 갖추는 것이 중요합니다. 먼저 다음 사항을 고려해야 합니다.
- 클러스터에 원하는 스토리지 노드 수
- 노드당 OSD(디스크) 수는 몇 개입니까?
- 노드가 위치한 곳
위의 사항은 기본 Ceph 구성을 정의하는 주요 요소이며, 따라서 운영자가 생성하는 확장 가능 해싱 (CRUSH) 맵 에 따른 배치 그룹 과 제어된 복제를 정의합니다 .
OpenShift Data Foundation을 별다른 생각 없이 설치하고 무작위로 보이는 노드들을 스토리지 노드로 레이블링하면 토폴로지가 좋지 않더라도 작동할 것입니다. 예를 들어, 동일한 가용성 영역에 여러 노드가 있고 장애 도메인에 데이터를 균등하게 분산하지 못할 수 있습니다. OpenShift Data Foundation은 노드 레이블을 기반으로 토폴로지를 구축합니다. 토폴로지를 구성하는 데 사용되는 노드 레이블은 다음과 같습니다.
topology.kubernetes.io/region topology.kubernetes.io/zone topology.rook.io/datacenter topology.rook.io/room topology.rook.io/pod topology.rook.io/pdu topology.rook.io/row topology.rook.io/rack topology.rook.io/chassis
지역, 영역, 랙 레이블이 더 일반적으로 사용되며, OpenShift Data Foundation은 주로 영역 및 랙 레이블을 활용하여 Ceph 풀의 토폴로지를 결정합니다. 다른 레이블도 OSD의 CRUSH 계층 구조에 기여하지만, OpenShift Data Foundation에서 생성한 풀은 영역 및 랙과 달리 이러한 레이블을 장애 도메인으로 사용하지 않습니다.
Kubernetes 지역 및 영역 레이블은 공통 노드 레이블입니다. 클라우드/기반 플랫폼에 따라 노드에 이미 논리적 지역/영역 레이블이 있을 수 있습니다. 토폴로지 레이블은 클러스터 배포 상황을 정확하게 파악하여 Rook이 Ceph 토폴로지를 배포하는 데 필요한 정보를 얻는 데 도움이 될 수 있습니다. 가능한 경우 Kubernetes 지역 및 영역 레이블을 활용하는 것이 가장 좋습니다. VMWare의 경우, vSphere에서 클러스터의 지역 및 영역 구성을 아직 지정하지 않았다면 지정하는 것이 좋습니다. 이렇게 하면 스토리지 클러스터가 Ceph 클러스터를 배포하는 방법에 대한 정보를 얻을 수 있습니다.
노드 레이블이 없는 경우, OpenShift Data Foundation 운영자는 장애 도메인을 자동으로 파악하기 위해 최선을 다합니다. 장애 도메인은 기본적으로 데이터가 어떻게 분산될지 정의합니다. 예를 들어, 세 개의 서로 다른 존(zone)에 대해 각 노드에 존 레이블이 있는 경우, Ceph는 세 개의 존에 데이터 복제본을 분산합니다. 노드 레이블을 추가하면 토폴로지 정보가 없는 데이터 분산에 의존하여 데이터를 무작위 노드에 분산하는 대신 최적의 데이터 복원력을 확보할 수 있습니다.
존 기반 예제
예를 들어, 그림 1은 각 존(zone)당 두 대의 서버가 있는 세 개의 존(zone)으로 구성된 토폴로지를 보여줍니다. 처음에는 노드당 하나의 디스크가 있고, 노드당 추가 디스크를 사용하여 확장할 수 있습니다. 토폴로지와 장애 존은 노드의 topology.kubernetes.io/zone 레이블을 기반으로 합니다.
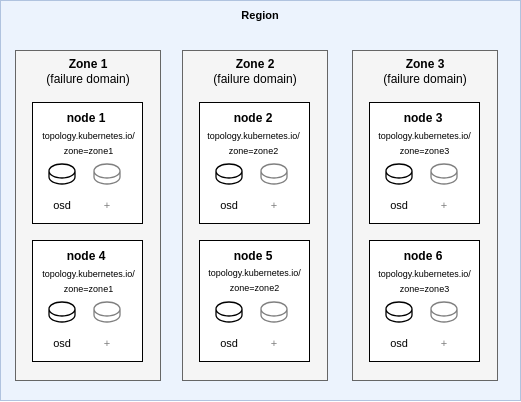
Ceph 스타일 레이아웃에서는 다음과 같습니다.
.
└── region
├── zone (topology.kubernetes.io/zone=zone1)
| |── host: ocs-deviceset-0-data
| | └── osd
| └── host: ocs-deviceset-4-data
| └── osd
├── zone (topology.kubernetes.io/zone=zone2)
| |── host: ocs-deviceset-1-data
| | └── osd
| └── host: ocs-deviceset-3-data
| └── osd
└── zone (topology.kubernetes.io/zone=zone3)
|── host: ocs-deviceset-2-data
| └── osd
└── host: ocs-deviceset-5-data
└── osd이 예시를 자세히 설명하면, 기본 블록 풀의 총 복제본 수는 3개이며, 각 존(zone)당 복제본은 1개입니다(이 예시에서 “존”은 정의된 장애 도메인입니다). 클러스터에 데이터가 기록되면 각 존의 OSD 하나에 저장되므로, 존 전체에 걸쳐 총 3개의 데이터 복제본이 생성됩니다.
유연한 확장성
유연한 확장 기능 은 StorageCluster에서 활성화하면 failureDomain 을 host 로 설정하는 기능입니다 . 이를 통해 영역이나 랙의 분포와 관계없이 모든 노드에 복제본을 균등하게 분산할 수 있습니다. 이는 OpenShift Data Foundation이 이미 정의된 영역을 사용하거나, 토폴로지를 시뮬레이션하기 위해 자동으로 세 개의 랙을 정의하는 기본 동작과 대조됩니다. 유연한 확장 기능은 Ceph 풀 생성 및 풀과 관련된 CRUSH 규칙에 큰 영향을 미치므로 클러스터 생성 중에 설정해야 합니다. 따라서 실행 중에 flexibleScaling을 수정하는 것은 불가능하며, 관련 리소스와 풀의 CRUSH 규칙은 변경되지 않습니다.
풀에 대한 CRUSH 규칙이 host 장애 도메인에 기반한 경우, 스토리지 노드의 위치에 따라 데이터 분배가 무작위적으로 이루어질 수 있습니다. 스토리지 노드가 3개뿐이고 특정 존에 고정된 설정이라면 각 노드에 복제본이 존재하므로 큰 문제가 되지 않습니다. 그러나 3개 이상의 스토리지 노드에서 풀을 운영할 계획이라면, host를 기반으로 한 CRUSH 규칙 적용 시 노드 단위에서 데이터 분산이 무작위로 이루어집니다(그림 2 참조). 존이나 기타 토폴로지 레이블이 정의된 경우 해당 수준에서는 토폴로지가 무시됩니다. 유연한 확장 기능에서는 오직 호스트 수준의 데이터 분산만 적용됩니다.
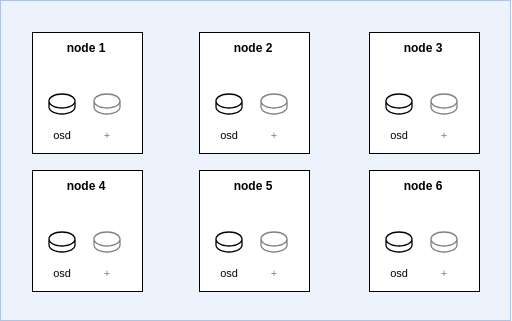
Ceph 스타일 레이아웃에서는 다음과 같습니다.
.
└──
├── host: ocs-deviceset-0-data
| └── osd
├── host: ocs-deviceset-1-data
| └── osd
├── host: ocs-deviceset-2-data
| └── osd
├── host: ocs-deviceset-3-data
| └── osd
├── host: ocs-deviceset-4-data
| └── osd
└── host: ocs-deviceset-5-data
└── osd토폴로지 확인
다음 명령은 풀이 계층 구조에 대해 예상 호스트, 영역 또는 기타 수준을 사용하고 있는지 확인하는 방법을 보여줍니다. 이러한 명령은 rook-ceph 도구 상자 컨테이너 내에서 실행할 수 있습니다. Rook-Ceph 도구 상자 구성 방법을 참조하세요 .
rook-ceph 도구 상자 포드를 활성화하려면 (아직 활성화/실행 중이 아닌 경우):
oc patch OCSInitialization ocsinit -n openshift-storage --type json --patch '[{ "op": "replace", "path": "/spec/enableCephTools", "value": true }]'포드에 들어가세요:
oc rsh -n openshift-storage $(oc get pods -n openshift-storage -l app=rook-ceph-tools -o name)
OSD 트리를 표시합니다.
ceph osd df tree
복제 요소와 CRUSH 규칙이 포함된 풀을 표시합니다.
ceph osd pool ls detail
모든 CRUSH 규칙과 각 풀에 대한 관련 버킷을 나열하세요.
ceph osd crush rule dump
기본 저장소
로컬 스토리지 오퍼레이터와 함께 베어 메탈(실제 원시 스토리지 사용)을 사용하는 경우, 호스트, 랙 및 영역과 베어 메탈 토폴로지를 일치시키기 위해 토폴로지를 정의하는 것이 매우 간단할 수 있습니다. VMware와 같이 장치가 동적 StorageClass을 사용하여 프로비저닝되는 다른 환경에서는 추가 고려 사항이 필요할 수 있습니다. VMware에서 기본 StorageClass를 사용하여 배포하는 경우 VSAN 또는 VMFS가 될 가능성이 높습니다. 이 두 가지 중 하나를 사용하면 복제가 반복되는 상황에 처할 수 있습니다. 복제 수준이 높아지면 성능이 저하되므로 OpenShift Data Foundation의 기본 스토리지가 어디에서 제공되는지, 그리고 그것이 무엇을 의미하는지 살펴보는 데 시간을 투자하는 것이 좋습니다.
복제 정책/계층
복제 요구 사항은 스토리지가 필요한 모든 워크로드가 동일하지 않으므로 평가해야 합니다. 데이터 복제 방식을 나타내는 계층 시스템을 도입할 수도 있습니다. 일부 스토리지 요구 사항은 단순히 “초기 공간”일 수 있으므로 필요 이상의 데이터 사본을 보관할 필요가 없습니다. 다른 애플리케이션 데이터는 매우 중요할 수 있으므로 데이터가 완전히 복제되었는지 더욱 확실하게 보장해야 합니다. 이를 염두에 두고, 브론즈/실버/골드 복제 계층과 같이 각각 다른 풀을 가진 여러 스토리지 클래스를 정의하는 것이 좋습니다.
간단한 기본 설정에서는 각각 디스크가 하나씩 있는 노드 3개와 각 풀의 복제본이 3개로 구성됩니다. 이 설정에서는 쓰기 작업이 발생할 때마다 모든 OSD가 데이터 사본을 보관합니다. 디스크 용량이 2TB라면 총 6TB 중 2TB를 사용할 수 있습니다. 복제본 개수가 다른 여러 풀이 있는 경우, 사용 가능한 공간은 각 풀의 사용량에 따라 달라집니다.
기본적으로 다음 리소스에 대한 기본 리소스가 제공됩니다.
CephBlockPoolCephFilesystemCephObjectStore
클러스터의 모든 기본 풀 failureDomain은 이전에 토폴로지에서 생성된 영역이나 랙 등과 일치합니다. 블록 스토리지 풀의 예는 다음과 같습니다.
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
spec:
enableRBDStats: true
failureDomain: zone
replicated:
replicasPerFailureDomain: 1
size: 3
targetSizeRatio: 0.49이 예제에서는 총 3개의 데이터 사본이 존재하고 각 사본은 다른 영역( failureDomain)에 저장되므로 영역 하나를 잃어버리더라도 해당 데이터의 사본은 2개 남아 있게 됩니다.
다양한 복제 옵션에 대한 지원 세부 정보는 복제본 2 풀 과 지원되는 구성 에 대한 데이터 가용성 및 무결성 고려 사항을 참조하세요 .
결론
OpenShift Data Foundation 스토리지 클러스터는 기반 플랫폼 환경, 사용 가능한 스토리지, 복제 옵션 등 다양한 요소를 신중하게 고려해야 합니다. 토폴로지와 노드 및 장애 도메인에 데이터가 어떻게 분산되는지 이해하는 것은 복원력 있는 설계를 달성하는 데 매우 중요합니다. 노드 레이블을 활용하고 적절한 복제 정책을 구성하면 배포 환경의 내결함성과 확장성을 모두 확보할 수 있습니다.


