Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://developers.redhat.com/articles/2025/04/24/evaluating-memory-overcommitment-openshift-virtualization
가상화는 워크로드 통합을 위한 일반적인 기술입니다. Red Hat OpenShift Virtualization을 통해 Red Hat OpenShift Container Platform 에 제공됩니다 . 이 플랫폼을 통해 기업은 가상 머신 기반 워크로드를 실행 및 배포하고, 클라우드 환경에서 가상 머신(VM)을 간편하게 관리하고 마이그레이션할 수 있습니다.
쿠버네티스, 즉 OpenShift와 OpenShift Virtualization은 설계상 스왑 사용을 허용하지 않습니다. 스왑을 사용하지 않고 메모리를 초과 사용하는 것은 위험합니다. 노드에서 실행 중인 프로세스에 필요한 메모리 양이 사용 가능한 RAM 용량을 초과하면 프로세스가 강제 종료되기 때문입니다. 이는 어떤 경우에도 바람직하지 않지만, 특히 VM이 종료되면 VM에서 실행 중인 워크로드가 중단되는 VM의 경우에는 더욱 그렇습니다.
Red Hat OpenShift는 현재 가상 메모리를 늘리기 위해 스왑을 사용하는 것을 지원하지 않습니다(4.18에서는 가상화만을 위한 기술 미리보기입니다). 실제로 특별한 예방 조치 없이 가상화는 워크로드 통합을 위한 일반적인 기술입니다. Red Hat OpenShift Virtualization을 통해 Red Hat OpenShift Container Platform 에 제공됩니다 . 이 플랫폼을 통해 기업은 가상 머신 기반 워크로드를 실행 및 배포하고, 클라우드 환경에서 가상 머신(VM)을 간편하게 관리하고 마이그레이션할 수 있습니다.
쿠버네티스, 즉 OpenShift와 OpenShift Virtualization은 설계상 스왑 사용을 허용하지 않습니다. 스왑을 사용하지 않고 메모리를 초과 사용하는 것은 위험합니다. 노드에서 실행 중인 프로세스에 필요한 메모리 양이 사용 가능한 RAM 용량을 초과하면 프로세스가 강제 종료되기 때문입니다. 이는 어떤 경우에도 바람직하지 않지만, 특히 VM이 종료되면 VM에서 실행 중인 워크로드가 중단되는 VM의 경우에는 더욱 그렇습니다.
Red Hat OpenShift는 현재 가상 메모리를 늘리기 위해 스왑을 사용하는 것을 지원하지 않습니다(4.18에서는 가상화만을 위한 기술 미리보기입니다). 실제로 특별한 예방 조치 없이는 스왑이 구성된 노드는 시작되지 않습니다.
스왑을 사용하더라도 메모리 초과 구독은 메모리를 스토리지로 페이징하는 결과를 초래할 수 있으며, 이는 RAM보다 훨씬 느리고, 특히 지연 시간이 훨씬 깁니다. 최신 RAM의 지연 시간은 일반적으로 100나노초 수준인 반면, 고속 스토리지(NVMe)의 지연 시간은 일반적으로 100마이크로초 수준입니다. 따라서 스왑을 과도하게 사용하면 작업 부하가 크게 느려질 수 있습니다.
그럼에도 불구하고 스왑 사용이 적절한 상황이 있습니다. 이를 위해 OpenShift Virtualization은 wasp-agent 구성 요소를 구축하여 VM에서 스왑을 제어된 방식으로 사용할 수 있도록 했습니다.
OpenShift Virtualization을 통한 워크로드 밀도 극대화
이 문서에서는 wasp-agent를 구성하고 튜닝하여 더 높은 워크로드 밀도를 구현하는 하위 레벨의 측면에 중점을 둡니다. wasp-agent 매개변수 설정, 다양한 매개변수 설정으로 시스템에서 생성 가능한 VM 수, 그리고 그로 인한 성능 영향에 대한 연구를 보고합니다.
말벌 에이전트 메모리 과잉 할당 평가에서 얻은 주요 내용은 다음과 같습니다.
wasp-agent에서 제어하는 스왑 사용을 허용하기 위해 kubelet을 적절히 구성하고, 작업 부하 요구 사항에 따라 wasp 임계값, 초당 페이지 버스트 보호 한도, 시스템 오버커밋 백분율을 구성하는 것이 필수적입니다.
스왑 성능은 물론 시스템에서 실행되는 다른 작업 부하를 위해 빠르고 전용적인 스왑 장치를 구성하는 것이 가장 바람직합니다.
절대 최대 밀도를 특성화하기 위해 스와핑하는 동안 일정한 VM 할당 패턴 동작을 보여줍니다.
이 게시물에서는 CPU 오버커밋(overcommit)에 대해서는 다루지 않습니다. 오버커밋은 프로세스 종료 및 심각한 성능 저하와 같은 문제를 일으키지 않습니다. CPU가 오버커밋되면 해당 리소스의 가용성 대비 과도한 CPU 수요로 인해 워크로드 속도가 느려질 뿐입니다.
테스트 환경
마스터 3개와 워커 2개로 구성된 5개 노드의 OpenShift 클러스터를 사용했습니다. 모든 작업은 하나의 워커 노드에서 수행했습니다. 노드 자체는 Dell PowerEdge R740xd 시스템으로, 각 노드에는 2.10GHz Intel Xeon Gold 6130 CPU 2개(각각 16코어)가 장착되어 총 64개의 CPU와 192G 메모리를 갖습니다. 노드에는 시스템 디스크용 480GB SATA SSD와 여러 개의 Dell Enterprise NVMe CM6-V 1.6TB 드라이브가 있으며, 그중 하나는 스왑용으로 사용했습니다. 이 드라이브들은 6.9GB/초의 순차 읽기 속도(최대 1,300K 4KB I/S), 2.8GB/초의 순차 쓰기 속도(최대 215K 4KB 쓰기)를 제공합니다. 이 드라이브들은 이 테스트에서 다른 용도로 사용되지 않았습니다.
클러스터에서는 OpenShift Container Platform 4.17.5가 실행 중이었습니다. 작업이 시작되었을 당시 최신 릴리스는 OpenShift Virtualization 4.17.5였습니다.
테스트 설정
이 섹션에서는 실행한 테스트에 대해 설명합니다. 더 높은 워크로드 밀도 구성에 대한 설명서를 이미 읽었다고 가정합니다 . 여기서 설명하지 않은 단계는 설명된 대로 수행됩니다.
주의 - 먼저 이 글을 읽어보세요!
VM 메모리 오버커밋이나 기타 목적으로 스왑을 사용해 보려면 kubelet이 스왑이 활성화된 상태로 시작되도록 설정해야 합니다. 기본적으로 스왑이 활성화되면 kubelet은 실행되지 않습니다. 이렇게 하면 노드가 제대로 부팅되지 않고 클러스터에 참여할 수 없습니다. 따라서 아래 설명된 대로 kubelet이 스왑이 활성화된 상태로 시작되도록 설정하는 것이 매우 중요합니다. 이 작업을 먼저 수행하지 않고 ssh를 통해 노드에 접속하여 변경 사항을 적용할 수 없는 경우, 노드를 다시 생성해야 합니다.
이 변경을 위해 다음 KubeletConfig를 사용했습니다.
$ oc apply -f - <<'EOF'
kind: KubeletConfig
apiVersion: machineconfiguration.openshift.io/v1
metadata:
name: wasp-config
spec:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ''
kubeletConfig:
failSwapOn: false
EOF이 작업은 kubelet 구성이나 노드 활성화 스왑에 다른 변경 사항을 적용하기 전에 수행해야 하며 , 동시에 수행해서는 안 됩니다. 이렇게 하면 여러 작업이 순차적으로 수행되어 각 노드를 추가로 재시작해야 합니다. 하지만 이 단계와 아래에 설명된 다른 단계를 결합하면 kubelet이 시작되기 전에 스왑이 생성되면 노드가 시작되지 않는 경쟁 조건이 발생합니다.
이것을 적용한 후에는 oc apply계속 진행하기 전에 노드가 새 구성과 동기화될 때까지 기다려야 합니다.
$ oc wait mcp worker --for condition=Updated=True --timeout=-1s스왑을 위한 마스터 노드가 아닌 워커 노드만 지원합니다. wasp-agent 문서에서는 마스터 노드 사용을 권장하지 않으며, 중요한 시스템 구성 요소의 작동을 방해할 수 있고, 본 문서의 범위를 벗어납니다.
스왑 구성
설명서에 나와 있듯이 시스템 디스크에 스왑 파일을 생성하는 대신, 로컬로 연결된 NVMe 장치에 스왑을 구성하기로 했습니다. 이렇게 하면 스왑 트래픽과 파일 시스템 사용 간의 교차 간섭이 발생하지 않아 성능에 부정적인 영향을 미칠 수 있습니다.
$ oc apply -f - <<'EOF'
kind: MachineConfig
apiVersion: machineconfiguration.openshift.io/v1
metadata:
labels:
machineconfiguration.openshift.io/role: worker
name: 90-worker-swap
spec:
config:
ignition:
version: 3.4.0
systemd:
units:
- contents: |
[Unit]
Description=Provision and enable swap
ConditionFirstBoot=no
[Service]
Type=oneshot
ExecStart=/bin/sh -c 'disk="/dev/disk/nvme1n1" && \
sudo mkswap "$disk" && \
sudo swapon "$disk" && \
free -h && \
sudo systemctl set-property --runtime system.slice MemorySwapMax=0 IODeviceLatencyTargetSec="/ 50ms"'
[Install]
RequiredBy=kubelet-dependencies.target
enabled: true
name: swap-provision.service
EOF이어서 노드가 두 번째로 재부팅되므로, 진행하기 전에 노드가 새 구성과 동기화될 때까지 다시 기다려야 합니다.
$ oc wait mcp worker --for condition=Updated=True --timeout=-1s$ oc wait mcp worker –for 조건=업데이트=True –시간 초과=-1s
wasp-agent DaemonSet 구성
우리는 다음과 같은 예외를 제외하고 문서화된 wasp-agent DaemonSet을 만드는 절차를 따랐습니다.
SWAP_UTILIZATION_THRESHOLD_FACTOR를 기본값 0.8 대신 0.99로 설정되었습니다. 이는 wasp-agent가 VM을 강제로 삭제하기 시작하는 시점의 사용량을 제어합니다. 이 설정의 목적은 Kubernetes가 아닌 프로세스를 위해 스왑 공간을 예약하는 것입니다. 이 설정은 이 목적과는 관련이 없습니다.
MAX_AVERAGE_SWAP_IN_PAGES_PER_SECOND과 MAX_AVERAGE_SWAP_OUT_PAGES_PER_SECOND는 기본값 1000 대신 (실질적으로 무제한) 1000000000000 으로 설정되었습니다. 이 매개변수는 wasp-agent에게 VM이 제거되기 전에 허용해야 하는 스왑 트래픽 수준(30초 평균)을 알려줍니다.
목적은 스왑 트래픽이 디스크 I/O 대역폭을 초과하여 다른 프로세스에 부담을 주는 것을 방지하는 것입니다. 기본값은 30초 동안 평균 약 4MB/초입니다. 높은 대역폭과 초당 I/O 속도를 제공하는 전용 장치로 스왑을 진행했기 때문에 이러한 이유로 VM을 제거할 이유가 없었습니다. 스왑에는 전용 로컬 스토리지를 사용하는 것이 권장되므로, 모든 장치 대역폭을 사용할 수 있도록 이 매개변수를 매우 높은 값으로 설정하는 것이 좋습니다.
메모리 초과 커밋 비율
memoryOvercommitPercentage는 사용해야 하는 마지막 구성 매개변수는 입니다. 이는 wasp-agent가 아닌 하이퍼컨버지드 객체의 일부이며, CNV가 실제로 VM을 생성하는 virt-launcher 포드에 적용하는 메모리 요청 계산을 제어합니다. 테스트에서 매개변수화되어 테스트 설명의 일부이지만, 시스템 구성 매개변수이므로 여기에 포함합니다.
100보다 큰 값(즉, 100%)으로 설정하면 CNV가 생성된 각 VM에 대해 메모리 요청을 어떻게 확장할지 결정합니다. 따라서 100으로 설정하면 CNV는 VM에 선언된 전체 메모리 크기를 기준으로 메모리 요청을 계산합니다. 100보다 큰 값으로 설정하면 CNV는 VM에 실제로 필요한 메모리 크기보다 작은 값으로 요청을 설정하여 메모리를 과도하게 할당할 수 있습니다.
예를 들어, 16GiB로 구성된 VM에서 오버커밋 비율을 기본값인 100로 설정하면 CNV가 Pod에 적용하는 메모리 요청량은 16GiB에 VM을 실행하는 QEMU 프로세스의 오버헤드를 더한 값입니다. 200로 설정하면 요청량은 오버헤드를 더한 8GiB로 설정됩니다.
테스트 설명
ClusterBuster 의 메모리 워크로드를 사용하여 CPU 사용률에 따라 메모리 압력을 적용하여 메모리 과다 할당이 CPU 기반 성능에 미치는 영향을 확인했습니다. 이는 정의된 메모리 블록을 할당하고 이를 어떻게 사용할지에 대한 옵션을 제공하는 순수 합성 워크로드입니다. 이 경우에는 두 가지 옵션을 사용했습니다.
- 정의된 시간(180초) 동안 페이지당 1바이트씩 쓰면서 메모리를 스캔합니다.
- 블록 내의 임의의 페이지에 동일한 시간 동안 페이지당 1바이트를 씁니다.
ClusterBuster는 컨트롤러-워커 아키텍처를 사용하며, 컨트롤러 포드는 워커 포드 또는 VM(이 경우 모든 VM) 세트를 관리합니다. 워크로드는 각 워커가 시작되고 메모리 블록을 할당한 후에만 실행됩니다. 이 방법을 사용하면 약 0.1초 이내에 동기화가 완료되는데, 180초의 런타임을 고려하면 매우 정확한 결과를 얻기에 충분합니다. 두 워커 중 하나에서는 컨트롤러를 실행하고, 다른 하나에서는 워커를 실행했습니다.
모든 VM은 단일 코어이며, 게스트 메모리 크기는 16GiB입니다. 워크로드 메모리 크기는 14GiB입니다.
우리가 사용한 기본 명령줄은 다음과 같습니다.
$ clusterbuster --workload=memory --deployment-type=vm --memory-scan=<scan_type> --vm-memory=16Gi --processes=1 --deployments=<n> --workload-runtime=180 --memory-size=14Gi --pin-node=<desired_node>scan_type은 1(순차 스캔) 또는 random(무작위 스캔)이었습니다. 현재 허용되는 다른 값은 0은 메모리 스캔이 없음을 나타내는 입니다(다른 종류의 테스트에 유용합니다). pin 노드는 모든 워커를 실행하기 위해 선택한 노드입니다.
하이퍼컨버지드 CRD의 매개 memoryOvercommitPercentage 변수는 퍼즐의 마지막 조각입니다. CNV는 VM의 메모리 요청을 VM의 메모리 크기보다 작은 값으로 설정하는 방식으로 작동합니다. 요청된 VM 크기에 대한 요청량은 게스트 메모리와 memoryOvercommitPercentage.
memoryOvercommitPercentage의 테스트된 각 값 (100, 700, 800, 900, 1000, 1100)에 대해 VM 1개로 시작하여 작업 실행이 실패할 때까지 VM 수를 늘렸습니다. 이 값들은 RAM만 사용할 때와 비교하여 모든 가상 메모리(RAM + 스왑)의 가용성을 상하로 확장하도록 설정했으며, VM 100개를 생성할 수 있을 때 중지했습니다. 이는 192GiB RAM을 가진 노드에서 1.4TiB 작업 세트에 해당합니다. 이 작업은 oc -n openshift-cnv patch HyperConverged설명서의 단계를 통해 수행됩니다. 또한 VM당 초당 처리된 페이지 수를 수집하여 임의 및 순차 스캔 모두에 대한 집계를 계산했습니다. 마지막으로 스왑을 전혀 활성화하지 않고 실행했습니다.
결과
이 섹션에서는 테스트에서 관찰된 VM 밀도와 성능 영향을 요약합니다.
VM 밀도
VM 밀도의 경우, 예상대로 메모리 오버커밋 수준에 따라 생성할 수 있는 VM 수가 꾸준히 증가하는 것을 확인했습니다(그림 1). 오버커밋 비율에 따라 VM 수가 선형적으로 증가하는 것을 확인했습니다. 한계에 도달하기 전에는 OOM 종료, 축출, 또는 노드 준비 안 됨 등 노드 스트레스 징후는 관찰되지 않았습니다.
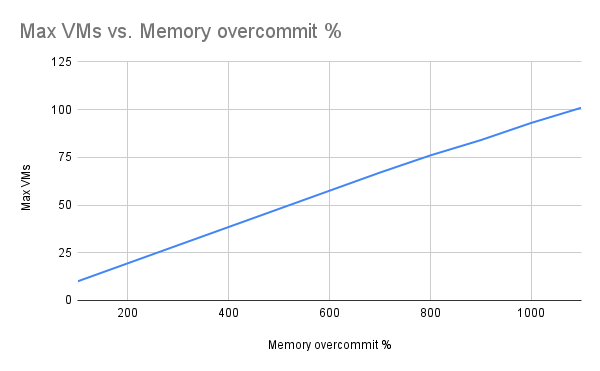
그림 1: 성공적으로 생성된 최대 VM 수 대비 메모리 오버커밋 비율. Robert Krawitz 제작.
메모리 처리량
우리는 3가지 성과 체계를 관찰했습니다.
- 최대 11개의 VM이 RAM에 모두 들어가고 선형적 성능이 관찰되었습니다(이 그래프는 로그형입니다).
- 12개에서 대략 15개의 VM 사이에서 스왑이 더 많이 사용되면서 성능이 급격히 떨어졌지만 완전히 떨어진 것은 아니었습니다.
- VM이 15개 정도를 넘으면 성능이 안정화됩니다(테스트의 한계인 VM이 100개일 때까지는 거의 안정화되었습니다).
결과는 사용된 초과 커밋 비율(표시되지 않음)에 관계없이 실질적으로 동일했습니다.
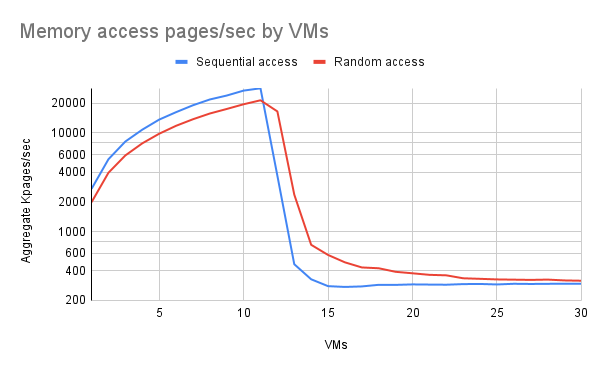
그림 2: 실행 중인 VM 수에 따른 VM의 총 I/O 속도. Robert Krawitz가 작성했습니다.
RAM이 주도하는 환경에서 순차 접근이 임의 접근보다 성능이 약간 더 우수하다는 점에 주목하십시오. 여기에는 몇 가지 이유가 있을 수 있습니다. 임의 접근으로 인해 큰 페이지가 있는 경우 TLB 스레싱이 더 많이 발생했거나, 난수 생성기 자체에 훨씬 더 많은 시간이 소요되었을 수 있습니다. 난수 생성기 실험 결과, 이것이 병목 현상의 원인이 아닐 가능성이 높습니다.
전이 영역에서는 임의 접근이 순차 접근보다 성능이 훨씬 뛰어났습니다. 이는 임의 접근이 때때로 RAM에 남아 있는 페이지에 영향을 미치는 반면, 순차 접근과 가장 최근에 사용되지 않은 페이지 처리 방식이 결합되면 거의 항상 저장소에서 페이지를 가져와야 하기 때문이라고 생각합니다.
전환 영역을 벗어나면 랜덤 액세스로 인해 가끔씩 충돌이 발생하지만 VM 수가 증가함에 따라 그 빈도는 점점 줄어듭니다.
VM 간 변형
우리가 파악하고자 했던 한 가지 요소는 모든 VM이 비슷한 성능을 보이는지, 아니면 일부 VM이 더 좋거나/나쁘게 나타나는지였습니다. 약 12개에서 14개 VM 사이의 전환 구간에서 VM마다 상당한 차이가 있음을 발견했습니다. 특히 12개 VM에서 일부 VM은 최대 RAM 속도로 작동하는 반면, 다른 VM은 페이징으로 인해 성능이 제한되었습니다.
이에 대한 명확한 설명은 없습니다. 아마도 “운이 좋은” VM은 메모리를 너무 빨리 스캔하여 페이지가 가장 최근에 사용된 페이지가 아닌 반면, 운이 나쁜 VM은 해당 페이지를 자주 사용하지 않아 사실상 모든 페이지가 삭제되었을 가능성이 있습니다. 그림 3의 차트는 VM당 초당 페이지 수를 그래프로 나타낸 것이므로, 집계 차트(그림 2)와 달리 VM 수가 증가함에 따라 이 수치는 계속 감소하는 경향을 보입니다.
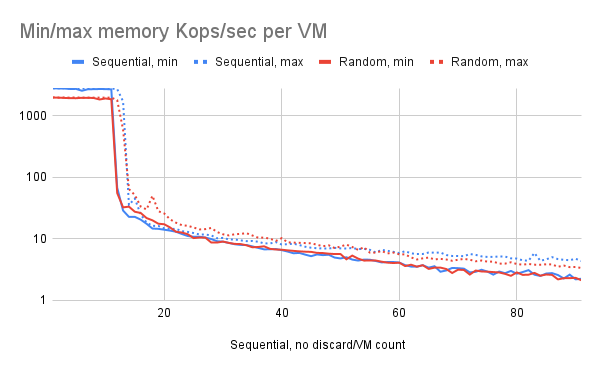
그림 3: 실행 중인 VM 수에 따른 VM당 최소 및 최대 I/O 속도. Robert Krawitz가 작성했습니다.
결론
필요에 따라 wasp-agent를 사용하면 하드웨어를 더욱 완벽하게 활용하거나 VM 마이그레이션과 같은 갑작스러운 부하를 처리하는 데 효과적인 방법이 될 수 있습니다. 이 테스트에 사용된 합성 워크로드는 최악의 워크로드이며, 많은 경우 메모리 오버커밋을 활용하여 VM 밀도를 높일 수 있습니다. 과부하 시나리오에서 VM의 전반적인 성능은 저하되었지만, VM은 계속 실행되었고 충돌이나 장애 없이 작동했습니다.는 스왑이 구성된 노드는 시작되지 않습니다.
스왑을 사용하더라도 메모리 초과 구독은 메모리를 스토리지로 페이징하는 결과를 초래할 수 있으며, 이는 RAM보다 훨씬 느리고, 특히 지연 시간이 훨씬 깁니다. 최신 RAM의 지연 시간은 일반적으로 100나노초 수준인 반면, 고속 스토리지(NVMe)의 지연 시간은 일반적으로 100마이크로초 수준입니다. 따라서 스왑을 과도하게 사용하면 작업 부하가 크게 느려질 수 있습니다.
그럼에도 불구하고 스왑 사용이 적절한 상황이 있습니다. 이를 위해 OpenShift Virtualization은 wasp-agent 구성 요소를 구축하여 VM에서 스왑을 제어된 방식으로 사용할 수 있도록 했습니다.
OpenShift Virtualization을 통한 워크로드 밀도 극대화
이 문서에서는 wasp-agent를 구성하고 튜닝하여 더 높은 워크로드 밀도를 구현하는 하위 레벨의 측면에 중점을 둡니다. wasp-agent 매개변수 설정, 다양한 매개변수 설정으로 시스템에서 생성 가능한 VM 수, 그리고 그로 인한 성능 영향에 대한 연구를 보고합니다.
말벌 에이전트 메모리 과잉 할당 평가에서 얻은 주요 내용은 다음과 같습니다.
- wasp-agent에서 제어하는 스왑 사용을 허용하기 위해 kubelet을 적절히 구성하고, 작업 부하 요구 사항에 따라 wasp 임계값, 초당 페이지 버스트 보호 한도, 시스템 오버커밋 백분율을 구성하는 것이 필수적입니다.
- 스왑 성능은 물론 시스템에서 실행되는 다른 작업 부하를 위해 빠르고 전용적인 스왑 장치를 구성하는 것이 가장 바람직합니다.
- 절대 최대 밀도를 특성화하기 위해 스와핑하는 동안 일정한 VM 할당 패턴 동작을 보여줍니다.
이 게시물에서는 CPU 오버커밋(overcommit)에 대해서는 다루지 않습니다. 오버커밋은 프로세스 종료 및 심각한 성능 저하와 같은 문제를 일으키지 않습니다. CPU가 오버커밋되면 해당 리소스의 가용성 대비 과도한 CPU 수요로 인해 워크로드 속도가 느려질 뿐입니다.
테스트 환경
마스터 3개와 워커 2개로 구성된 5개 노드의 OpenShift 클러스터를 사용했습니다. 모든 작업은 하나의 워커 노드에서 수행했습니다. 노드 자체는 Dell PowerEdge R740xd 시스템으로, 각 노드에는 2.10GHz Intel Xeon Gold 6130 CPU 2개(각각 16코어)가 장착되어 총 64개의 CPU와 192G 메모리를 갖습니다. 노드에는 시스템 디스크용 480GB SATA SSD와 여러 개의 Dell Enterprise NVMe CM6-V 1.6TB 드라이브가 있으며, 그중 하나는 스왑용으로 사용했습니다. 이 드라이브들은 6.9GB/초의 순차 읽기 속도(최대 1,300K 4KB I/S), 2.8GB/초의 순차 쓰기 속도(최대 215K 4KB 쓰기)를 제공합니다. 이 드라이브들은 이 테스트에서 다른 용도로 사용되지 않았습니다.
클러스터에서는 OpenShift Container Platform 4.17.5가 실행 중이었습니다. 작업이 시작되었을 당시 최신 릴리스는 OpenShift Virtualization 4.17.5였습니다.
테스트 설정
이 섹션에서는 실행한 테스트에 대해 설명합니다. 더 높은 워크로드 밀도 구성에 대한 설명서를 이미 읽었다고 가정합니다 . 여기서 설명하지 않은 단계는 설명된 대로 수행됩니다.
주의 – 먼저 이 글을 읽어보세요!
VM 메모리 오버커밋이나 기타 목적으로 스왑을 사용해 보려면 kubelet이 스왑이 활성화된 상태로 시작되도록 설정해야 합니다. 기본적으로 스왑이 활성화되면 kubelet은 실행되지 않습니다. 이렇게 하면 노드가 제대로 부팅되지 않고 클러스터에 참여할 수 없습니다. 따라서 아래 설명된 대로 kubelet이 스왑이 활성화된 상태로 시작되도록 설정하는 것이 매우 중요합니다. 이 작업을 먼저 수행하지 않고 ssh를 통해 노드에 접속하여 변경 사항을 적용할 수 없는 경우, 노드를 다시 생성해야 합니다.
이 변경을 위해 다음 KubeletConfig를 사용했습니다.
$ oc apply -f - <<'EOF'
종류: KubeletConfig
apiVersion: machineconfiguration.openshift.io/v1
메타데이터:
이름: wasp-config
사양:
machineConfigPoolSelector:
matchLabels:
pools.operator.machineconfiguration.openshift.io/worker: ''
kubeletConfig:
failSwapOn: false
EOF
이 작업은 kubelet 구성이나 노드 활성화 스왑에 다른 변경 사항을 적용하기 전에 수행해야 하며 , 동시에 수행해서는 안 됩니다. 이렇게 하면 여러 작업이 순차적으로 수행되어 각 노드를 추가로 재시작해야 합니다. 하지만 이 단계와 아래에 설명된 다른 단계를 결합하면 kubelet이 시작되기 전에 스왑이 생성되면 노드가 시작되지 않는 경쟁 조건이 발생합니다.
이것을 적용한 후에는 oc apply계속 진행하기 전에 노드가 새 구성과 동기화될 때까지 기다려야 합니다.
$ oc wait mcp worker --for 조건=업데이트=True --시간 초과=-1s
스왑을 위한 마스터 노드가 아닌 워커 노드만 지원합니다. wasp-agent 문서에서는 마스터 노드 사용을 권장하지 않으며, 중요한 시스템 구성 요소의 작동을 방해할 수 있고, 본 문서의 범위를 벗어납니다.
스왑 구성
설명서에 나와 있듯이 시스템 디스크에 스왑 파일을 생성하는 대신, 로컬로 연결된 NVMe 장치에 스왑을 구성하기로 했습니다. 이렇게 하면 스왑 트래픽과 파일 시스템 사용 간의 교차 간섭이 발생하지 않아 성능에 부정적인 영향을 미칠 수 있습니다.
$ oc apply -f - <<'EOF'
종류: MachineConfig
apiVersion: machineconfiguration.openshift.io/v1
메타데이터:
레이블:
machineconfiguration.openshift.io/role: 작업자
이름: 90-worker-swap
사양:
구성:
점화:
버전: 3.4.0
systemd:
단위:
- 내용: |
[Unit]
설명=스왑 프로비저닝 및 활성화
ConditionFirstBoot=no
[서비스]
유형=oneshot
ExecStart=/bin/sh -c 'disk="/dev/disk/nvme1n1" && \
sudo mkswap "$disk" && \
sudo swapon "$disk" && \
free -h && \
sudo systemctl set-property --runtime system.slice MemorySwapMax=0 IODeviceLatencyTargetSec="/ 50ms"'
[설치]
RequiredBy=kubelet-dependencies.target
enabled: true
name: swap-provision.service
EOF
이어서 노드가 두 번째로 재부팅되므로, 진행하기 전에 노드가 새 구성과 동기화될 때까지 다시 기다려야 합니다.
$ oc wait mcp worker --for 조건=업데이트=True --시간 초과=-1s
wasp-agent DaemonSet 구성
우리는 다음과 같은 예외를 제외하고 문서화된 wasp-agent DaemonSet을 만드는 절차를 따랐습니다.
SWAP_UTILIZATION_THRESHOLD_FACTOR0.99기본값 대신 로 설정되었습니다0.8. 이는 wasp-agent가 VM을 강제로 삭제하기 시작하는 시점의 사용량을 제어합니다. 이 설정의 목적은 Kubernetes가 아닌 프로세스를 위해 스왑 공간을 예약하는 것입니다. 이 설정은 이 목적과는 관련이 없습니다.MAX_AVERAGE_SWAP_IN_PAGES_PER_SECOND기본값 대신 (실질적으로 무제한)MAX_AVERAGE_SWAP_OUT_PAGES_PER_SECOND으로 설정되었습니다 . 이 매개변수는 wasp-agent에게 VM이 제거되기 전에 허용해야 하는 스왑 트래픽 수준(30초 평균)을 알려줍니다.10000000000001000목적은 스왑 트래픽이 디스크 I/O 대역폭을 초과하여 다른 프로세스에 부담을 주는 것을 방지하는 것입니다. 기본값은 30초 동안 평균 약 4MB/초입니다. 높은 대역폭과 초당 I/O 속도를 제공하는 전용 장치로 스왑을 진행했기 때문에 이러한 이유로 VM을 제거할 이유가 없었습니다. 스왑에는 전용 로컬 스토리지를 사용하는 것이 권장되므로, 모든 장치 대역폭을 사용할 수 있도록 이 매개변수를 매우 높은 값으로 설정하는 것이 좋습니다.
메모리 초과 커밋 비율
사용해야 하는 마지막 구성 매개변수는 입니다 memoryOvercommitPercentage. 이는 wasp-agent가 아닌 하이퍼컨버지드 객체의 일부이며, CNV가 실제로 VM을 생성하는 virt-launcher 포드에 적용하는 메모리 요청 계산을 제어합니다. 테스트에서 매개변수화되어 테스트 설명의 일부이지만, 시스템 구성 매개변수이므로 여기에 포함합니다.
100보다 큰 값(즉, 100%)으로 설정하면 CNV가 생성된 각 VM에 대해 메모리 요청을 어떻게 확장할지 결정합니다. 따라서 100으로 설정하면 CNV는 VM에 선언된 전체 메모리 크기를 기준으로 메모리 요청을 계산합니다. 100보다 큰 값으로 설정하면 CNV는 VM에 실제로 필요한 메모리 크기보다 작은 값으로 요청을 설정하여 메모리를 과도하게 할당할 수 있습니다.
예를 들어, 16GiB로 구성된 VM에서 오버커밋 비율을 기본값인 로 설정하면 100CNV가 Pod에 적용하는 메모리 요청량은 16GiB에 VM을 실행하는 QEMU 프로세스의 오버헤드를 더한 값입니다. 로 설정하면 200요청량은 오버헤드를 더한 8GiB로 설정됩니다.
테스트 설명
ClusterBuster 의 메모리 워크로드를 사용하여 CPU 사용률에 따라 메모리 압력을 적용하여 메모리 과다 할당이 CPU 기반 성능에 미치는 영향을 확인했습니다. 이는 정의된 메모리 블록을 할당하고 이를 어떻게 사용할지에 대한 옵션을 제공하는 순수 합성 워크로드입니다. 이 경우에는 두 가지 옵션을 사용했습니다.
- 정의된 시간(180초) 동안 페이지당 1바이트씩 쓰면서 메모리를 스캔합니다.
- 블록 내의 임의의 페이지에 동일한 시간 동안 페이지당 1바이트를 씁니다.
ClusterBuster는 컨트롤러-워커 아키텍처를 사용하며, 컨트롤러 포드는 워커 포드 또는 VM(이 경우 모든 VM) 세트를 관리합니다. 워크로드는 각 워커가 시작되고 메모리 블록을 할당한 후에만 실행됩니다. 이 방법을 사용하면 약 0.1초 이내에 동기화가 완료되는데, 180초의 런타임을 고려하면 매우 정확한 결과를 얻기에 충분합니다. 두 워커 중 하나에서는 컨트롤러를 실행하고, 다른 하나에서는 워커를 실행했습니다.
모든 VM은 단일 코어이며, 게스트 메모리 크기는 16GiB입니다. 워크로드 메모리 크기는 14GiB입니다.
우리가 사용한 기본 명령줄은 다음과 같습니다.
$ clusterbuster --워크로드=메모리 --배포 유형=vm --메모리 스캔= <스캔_유형> --vm-메모리=16Gi --프로세스=1 --배포= <n> --워크로드-런타임=180 --메모리-크기=14Gi --핀-노드=<원하는_노드>
scan_type1(순차 스캔) 또는 random(무작위 스캔)이었습니다. 현재 허용되는 다른 값은 0메모리 스캔이 없음을 나타내는 입니다(다른 종류의 테스트에 유용합니다). pin 노드는 모든 워커를 실행하기 위해 선택한 노드입니다.
하이퍼컨버지드 CRD의 매개 memoryOvercommitPercentage변수는 퍼즐의 마지막 조각입니다. CNV는 VM의 메모리 요청을 VM의 메모리 크기보다 작은 값으로 설정하는 방식으로 작동합니다. 요청된 VM 크기에 대한 요청량은 게스트 메모리와 memoryOvercommitPercentage.
테스트된 각 값 memoryOvercommitPercentage(100, 700, 800, 900, 1000, 1100)에 대해 VM 1개로 시작하여 작업 실행이 실패할 때까지 VM 수를 늘렸습니다. 이 값들은 RAM만 사용할 때와 비교하여 모든 가상 메모리(RAM + 스왑)의 가용성을 상하로 확장하도록 설정했으며, VM 100개를 생성할 수 있을 때 중지했습니다. 이는 192GiB RAM을 가진 노드에서 1.4TiB 작업 세트에 해당합니다. 이 작업은 oc -n openshift-cnv patch HyperConverged설명서의 단계를 통해 수행됩니다. 또한 VM당 초당 처리된 페이지 수를 수집하여 임의 및 순차 스캔 모두에 대한 집계를 계산했습니다. 마지막으로 스왑을 전혀 활성화하지 않고 실행했습니다.
결과
이 섹션에서는 테스트에서 관찰된 VM 밀도와 성능 영향을 요약합니다.
VM 밀도
VM 밀도의 경우, 예상대로 메모리 오버커밋 수준에 따라 생성할 수 있는 VM 수가 꾸준히 증가하는 것을 확인했습니다(그림 1). 오버커밋 비율에 따라 VM 수가 선형적으로 증가하는 것을 확인했습니다. 한계에 도달하기 전에는 OOM 종료, 축출, 또는 노드 준비 안 됨 등 노드 스트레스 징후는 관찰되지 않았습니다.
메모리 처리량
우리는 3가지 성과 체계를 관찰했습니다.
- 최대 11개의 VM이 RAM에 모두 들어가고 선형적 성능이 관찰되었습니다(이 그래프는 로그형입니다).
- 12개에서 대략 15개의 VM 사이에서 스왑이 더 많이 사용되면서 성능이 급격히 떨어졌지만 완전히 떨어진 것은 아니었습니다.
- VM이 15개 정도를 넘으면 성능이 안정화됩니다(테스트의 한계인 VM이 100개일 때까지는 거의 안정화되었습니다).
결과는 사용된 초과 커밋 비율(표시되지 않음)에 관계없이 실질적으로 동일했습니다.
RAM이 주도하는 환경에서 순차 접근이 임의 접근보다 성능이 약간 더 우수하다는 점에 주목하십시오. 여기에는 몇 가지 이유가 있을 수 있습니다. 임의 접근으로 인해 큰 페이지가 있는 경우 TLB 스레싱이 더 많이 발생했거나, 난수 생성기 자체에 훨씬 더 많은 시간이 소요되었을 수 있습니다. 난수 생성기 실험 결과, 이것이 병목 현상의 원인이 아닐 가능성이 높습니다.
전이 영역에서는 임의 접근이 순차 접근보다 성능이 훨씬 뛰어났습니다. 이는 임의 접근이 때때로 RAM에 남아 있는 페이지에 영향을 미치는 반면, 순차 접근과 가장 최근에 사용되지 않은 페이지 처리 방식이 결합되면 거의 항상 저장소에서 페이지를 가져와야 하기 때문이라고 생각합니다.
전환 영역을 벗어나면 랜덤 액세스로 인해 가끔씩 충돌이 발생하지만 VM 수가 증가함에 따라 그 빈도는 점점 줄어듭니다.
VM 간 변형
우리가 파악하고자 했던 한 가지 요소는 모든 VM이 비슷한 성능을 보이는지, 아니면 일부 VM이 더 좋거나/나쁘게 나타나는지였습니다. 약 12개에서 14개 VM 사이의 전환 구간에서 VM마다 상당한 차이가 있음을 발견했습니다. 특히 12개 VM에서 일부 VM은 최대 RAM 속도로 작동하는 반면, 다른 VM은 페이징으로 인해 성능이 제한되었습니다.
이에 대한 명확한 설명은 없습니다. 아마도 “운이 좋은” VM은 메모리를 너무 빨리 스캔하여 페이지가 가장 최근에 사용된 페이지가 아닌 반면, 운이 나쁜 VM은 해당 페이지를 자주 사용하지 않아 사실상 모든 페이지가 삭제되었을 가능성이 있습니다. 그림 3의 차트는 VM당 초당 페이지 수를 그래프로 나타낸 것이므로, 집계 차트(그림 2)와 달리 VM 수가 증가함에 따라 이 수치는 계속 감소하는 경향을 보입니다.
결론
필요에 따라 wasp-agent를 사용하면 하드웨어를 더욱 완벽하게 활용하거나 VM 마이그레이션과 같은 갑작스러운 부하를 처리하는 데 효과적인 방법이 될 수 있습니다. 이 테스트에 사용된 합성 워크로드는 최악의 워크로드이며, 많은 경우 메모리 오버커밋을 활용하여 VM 밀도를 높일 수 있습니다 . 과부하 시나리오에서 VM의 전반적인 성능은 저하되었지만, VM은 계속 실행되었고 충돌이나 장애 없이 작동했습니다.
