Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://developers.redhat.com/articles/2025/07/17/openshift-lacp-bonding-performance-expectations
Red Hat OpenShift가 온프레미스 데이터 센터에 더 많이 도입됨에 따라 , 고가용성과 성능의 균형을 맞추기 위해 네트워크 인터페이스 카드(NIC) 본딩이 점점 더 많이 활용되고 있습니다. 본딩을 시작하기 전에 NIC 본딩 구성을 선택할 때 고려해야 할 몇 가지 사항이 있습니다. 이러한 고려 사항을 자세히 살펴보고 성능 수치가 무엇을 의미하는지 살펴보겠습니다.
빠른 히트: 알아야 할 사항
NIC 본드 구성과 관련하여 염두에 두어야 할 주요 사항은 다음과 같습니다.
- 실제로 802.3ad를 준수하는 것은 layer2/layer2+3 전송 정책뿐입니다.
- layer3+4 또는 encap3+4와 같은 비규격 전송 모드를 사용하는 경우 패킷이 순서에 맞지 않게 전달되는 현상이 나타날 수 있습니다.
- Red Hat OpenShift Container Platform이 MAC 주소를 할당하는 방식으로 인해 두 인터페이스를 본딩할 때 해싱 알고리즘이 특정 인터페이스를 우선적으로 사용하는 경우가 있습니다. 이는 Red Hat에서 추적 중인 알려진 문제 입니다.
- 궁극적으로, 가장 좋은 본딩 모드는 애플리케이션의 아키텍처와 네트워크를 사용하는 방법에 따라 달라집니다.
왜 xmit-hash에 관심을 가져야 할까요?
적절한 전송 해시 알고리즘을 선택하는 것은 단순히 “설정하고 잊어버리는” 종류의 문제가 아닙니다. OpenShift에서 어떤 종류의 애플리케이션을 실행할지 고려하는 것이 중요합니다. 각 노드에서 여러 개의 포드가 통신을 할까요, 아니면 몇 개의 포드(혹은 하나)만 지점 간 연결을 할까요?
- 설정에 네트워크 액세스가 필요한 여러 포드가 포함된 경우 , 레이어 2/레이어 2+3이 가장 좋은 선택일 수 있습니다. 이렇게 하면 연결된 링크 전체에 트래픽을 분산하는 데 도움이 됩니다.
- 반대로, 애플리케이션이 포드 스웜(즉, 노드당 하나의 포드)을 생성하지 않는 경우, 레이어 3+4가 더 나은 선택일 수 있습니다. 특히 애플리케이션이 생성하는 각 네트워크 스트림에 대해 서로 다른 소스 포트 또는 목적지 지점을 사용하는 데 능숙하다면 더욱 그렇습니다.
우리가 작업하고 있는 것: 테스트 설정
이 문제의 근본 원인을 파악하기 위해 구체적인 테스트 환경을 구축했습니다. 그림 1은 테스트 대상 시스템(SUT)의 모습을 간략하게 보여줍니다.

저희 연구실에서는 Top of Rack(ToR) 스위치로 Juniper QFX5200 한 대를 사용하고 있습니다. 저희 시스템에는 이중화를 위한 별도의 스위치가 없습니다. 하지만 스위치 인프라를 제대로 구성하면 테스트 결과는 달라지지 않으니 걱정하지 마세요.
장비
일관성을 유지하기 위해 모든 기계는 동일합니다.
- 서버: Intel(R) Xeon(R) Gold 5420+ CPU와 512Gi RAM을 탑재한 Dell R660.
- 본딩 NIC: R660의 Mellanox Technologies MT2892 제품군(ConnectX-6 Dx), 속도는 200000Mb/s입니다.
- NIC 세부 정보: 각 NIC 포트는 100000Mb/s이며, mlx5_core 드라이버와 펌웨어 버전 22.36.1010을 사용합니다.
소프트웨어 스택
하드웨어와 마찬가지로 소프트웨어도 전반적으로 동일합니다.
- OpenShift: 버전 4.18(4.14와 같은 이전 버전에서도 테스트를 실행했습니다).
- 커널: 5.14.0-427.66.1.el9_4.x86_64.
테스트 도구: k8s-netperf
테스트에는 k8s-netperf라는 업스트림 도구를 사용했습니다. 이 도구는 Red Hat Performance 엔지니어가 쿠버네티스 설정에서 네트워크 성능을 측정하기 위해 특별히 개발했습니다. 이 글에서는 서로 다른 OpenShift 워커 노드에서 실행되는 단일 클라이언트와 서버 포드 간의 간단한 TCP 스트림을 분석합니다.
다음은 k8s-netperf 구성을 간략히 살펴본 것입니다( netperf.yml):
---
tests:
- TCPStream:
parallelism: 1
profile: "TCP_STREAM"
duration: 30
samples: 5
messagesize: 4096
- TCPStream:
parallelism: 2
profile: "TCP_STREAM"
duration: 30
samples: 5
messagesize: 4096
# ... (and so on for 4, 8, 16, 20 parallel streams)테스트를 시작한 방법은 다음과 같습니다.
$ k8s-netperf --metrics --iperf --netperf=false --clean=false --all --debug
주의하세요:
이 글에서는 OpenShift를 Bonds를 사용하여 설정하는 방법을 안내하지 않습니다. 연구실에 이미 OpenShift가 설치되어 실행 중이라고 가정합니다.
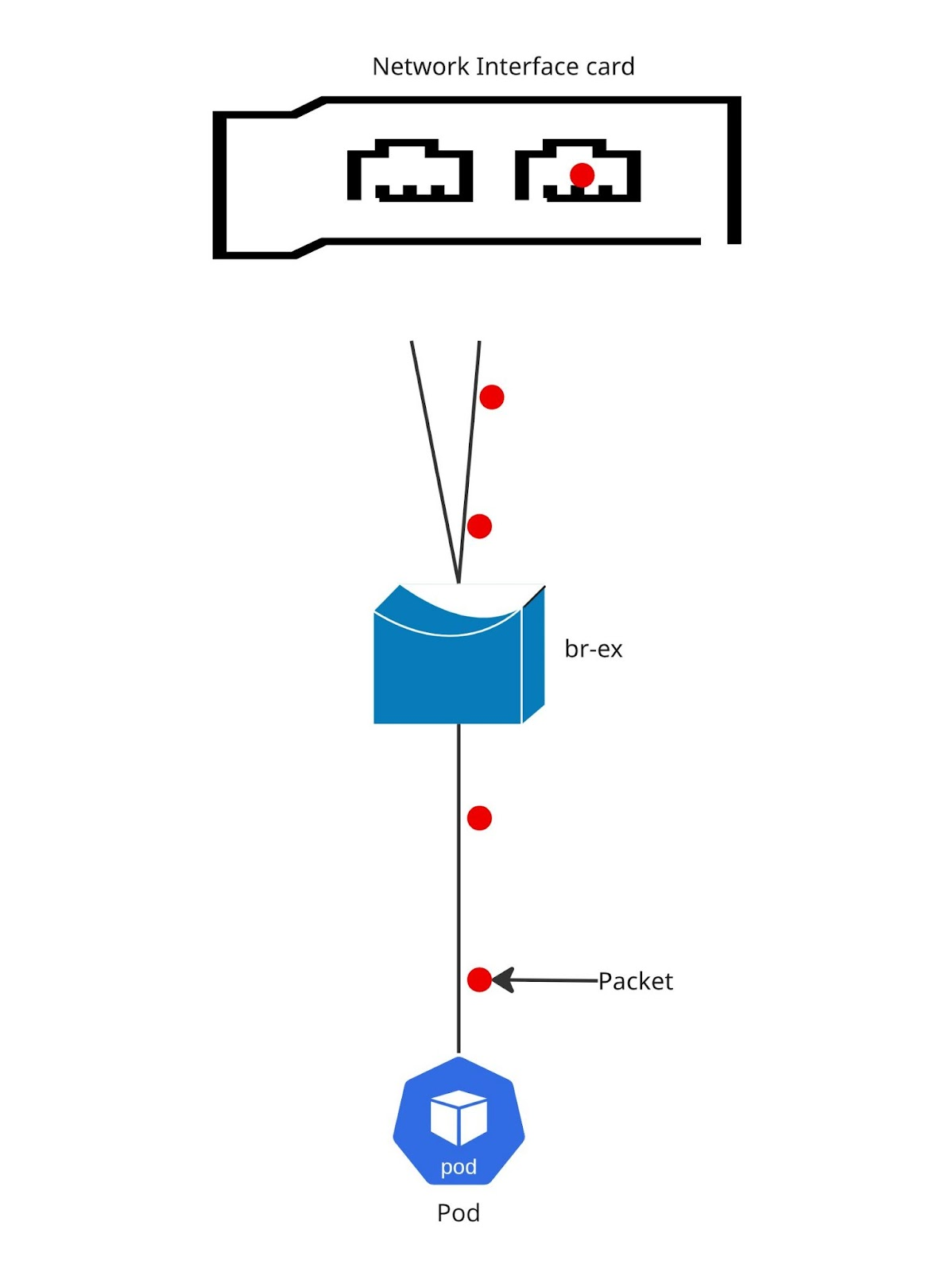
해싱: Layer2(기본값)
표준 LACP( Link Aggregation Control Protocol ) 본드 구성을 사용하는 경우 전송(xmit) 정책이 layer2(0)으로 설정됩니다. 이 방법은 소스(src)와 목적지(dst)의 MAC 주소를 확인하여 해싱 결정을 내립니다. OpenShift 환경에서는 OVNKubernetes가 실제로 IP 주소에서 이러한 MAC 주소를 생성합니다.
흥미로운 사실:
Linux는 MAC 주소 전체를 해시하지 않고, 마지막 바이트만 해시합니다.
커널 설명서에 따르면, 하드웨어 MAC 주소와 패킷 유형 ID를 XOR 연산하여 해시값을 생성합니다. 기본 공식은 다음과 같습니다.
Uses XOR of hardware MAC addresses and packet type ID field to generate the hash. The formula is hash = source MAC XOR destination MAC XOR packet type ID slave number = hash modulo slave count This algorithm will place all traffic to a particular network peer on the same slave. This algorithm is 802.3ad compliant.
이 접근 방식은 모든 트래픽을 동일한 슬레이브 인터페이스에 있는 특정 네트워크 피어로 유지하며 802.3ad를 준수합니다.
그림 2는 패킷 흐름을 보여줍니다.
Layer2 결과
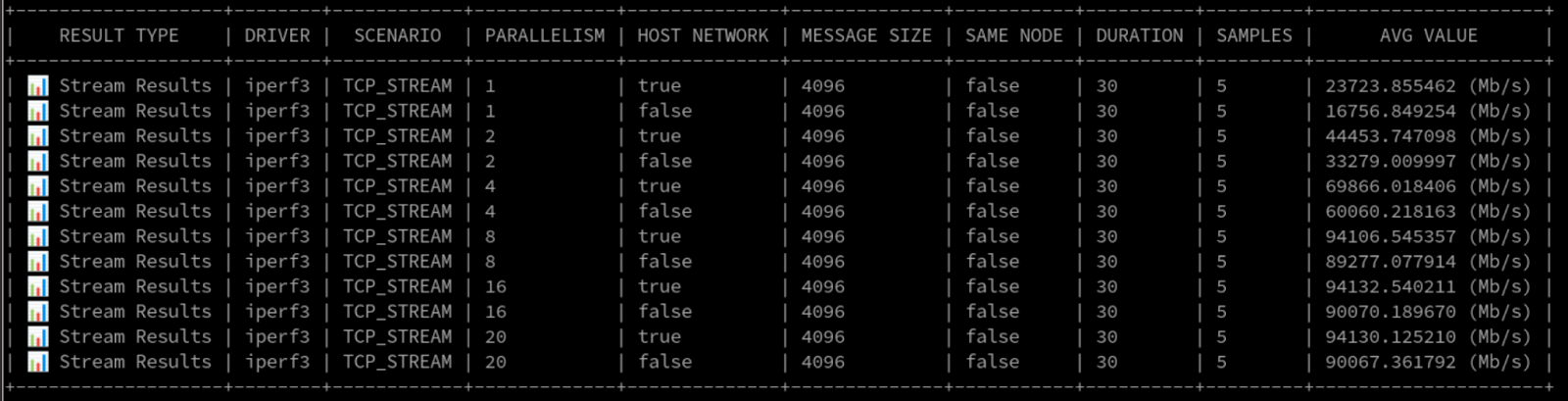
Pod 네트워크 내 단일 스트림으로 16Gbps 이상의 속도를 기록했습니다. 호스트 네트워크에서 실행했을 때는 23Gbps 이상으로 뛰어올랐습니다. iPerf3 스트림을 8개까지 늘렸을 때 최대 처리량은 무려 90Gbps에 달했습니다.
그림 3에서 이 테스트 동안의 네트워크 활용도를 확인하세요. 이 해싱 모드와 단일 목적지에서 예상되는 대로, 전송을 위해 대부분의 힘든 작업을 하나의 인터페이스에서 수행하는 것을 볼 수 있습니다.

데이터를 좋아하는 분들을 위해 원시 결과의 일부를 보여드리겠습니다(그림 4).
레이어 2+3 해싱
Layer2+3 해싱으로 넘어가면, 이 알고리즘은 Layer2와 유사하지만 IP 주소를 추가로 사용합니다. 흥미롭게도, 저희 테스트 결과 OVNKubernetes가 Pod의 MAC 주소를 생성하는 방식에서 개선이 필요한 부분이 드러났습니다. 현재 OVNKubernetes는 IP 주소 할당에서 MAC 주소를 도출합니다. 이러한 예측 가능성은 본드에 두 개의 인터페이스만 사용하는 경우 해싱에 적합하지 않습니다. 저희는 MAC 할당을 예측 가능한 방식이 아닌 무작위 방식으로 만들기 위해 개선 요청(RFE)을 추가했습니다. (Linux는 여기서도 MAC의 마지막 바이트를 해싱한다는 점을 기억하세요.)
커널 문서에 따르면 이 정책은 layer2와 layer3 정보를 조합하여 사용합니다. 공식은 다음과 같습니다.
This policy uses a combination of layer2 and layer3 protocol information to generate the hash. Uses XOR of hardware MAC addresses and IP addresses to generate the hash. The formula is hash = source MAC XOR destination MAC XOR packet type ID hash = hash XOR source IP XOR destination IP hash = hash XOR (hash RSHIFT 16) hash = hash XOR (hash RSHIFT 8) And then hash is reduced modulo slave count. If the protocol is IPv6 then the source and destination addresses are first hashed using ipv6_addr_hash. This algorithm will place all traffic to a particular network peer on the same slave. For non-IP traffic, the formula is the same as for the layer2 transmit hash policy. This policy is intended to provide a more balanced distribution of traffic than layer2 alone, especially in environments where a layer3 gateway device is required to reach most destinations. This algorithm is 802.3ad compliant.
패킷 흐름은 Layer2와 매우 유사합니다. 클라이언트와 서버 역할을 하는 포드가 더 많다면 본드 전체에서 트래픽 밸런싱이 더 개선될 것입니다. OCPBUGS-56076 문제(무작위 MAC 관련 RFE)가 해결되면 더욱 개선될 것입니다.
그림 5는 Layer2+3의 패킷 흐름을 보여줍니다.
Layer2+3 결과
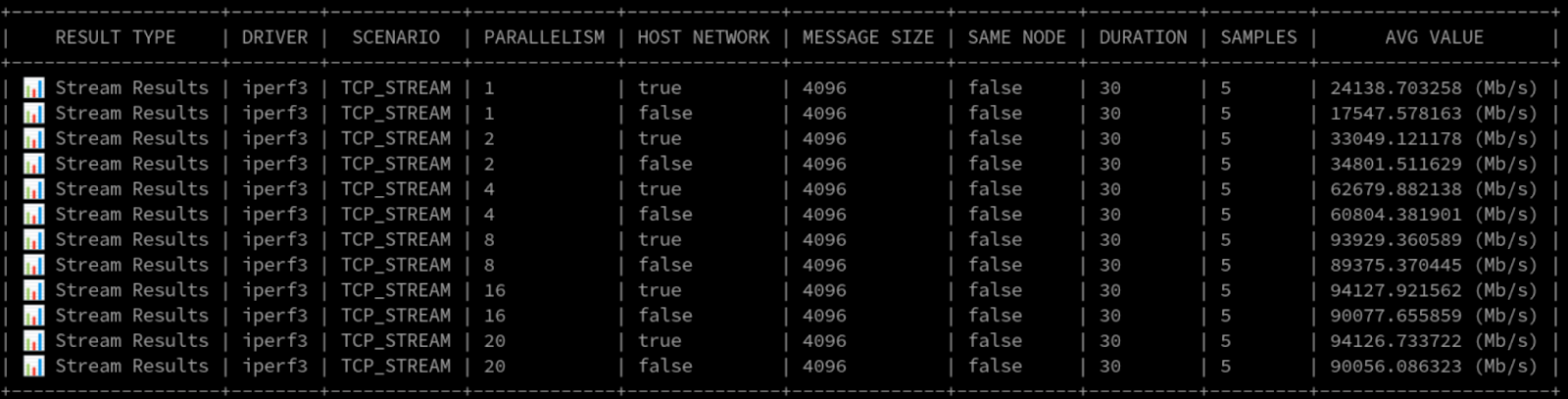
Layer2+3은 Layer2와 매우 가깝고, 단일 소스와 목적지로 테스트했기 때문에 해시 알고리즘은 본드에서 단일 인터페이스에 거의 고정되었습니다. 예상대로 성능은 Layer2에서 확인한 것과 크게 다르지 않았습니다.
그림 6의 활용도 그래프는 비슷한 상황을 보여주는데, 하나의 인터페이스가 대부분의 전송을 처리합니다.

그림 7은 원시 숫자를 보여줍니다.
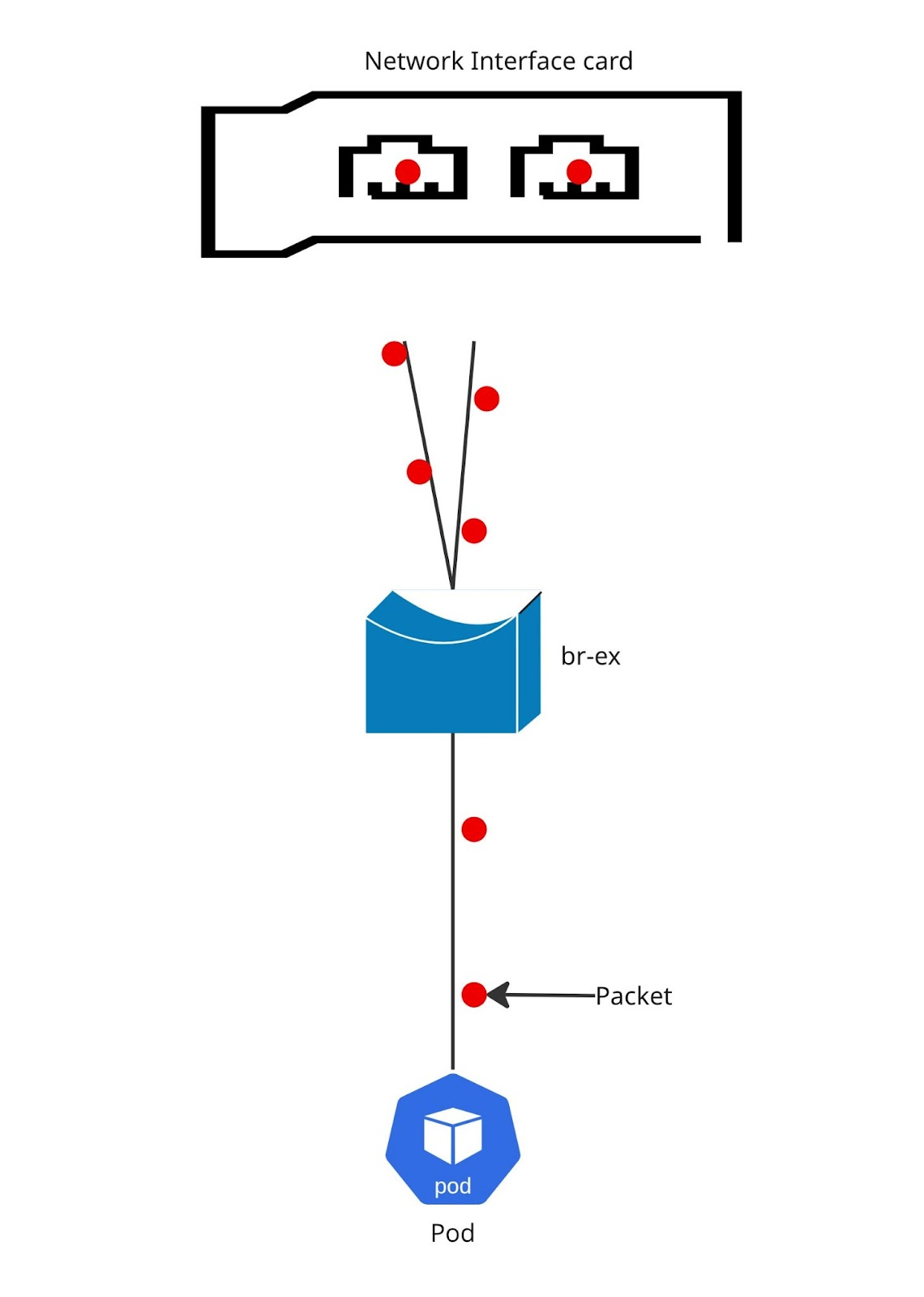
레이어 3+4 해싱
이제 Layer3+4 해싱에 대해 알아보겠습니다. 이 접근 방식은 단일 소스에서 단일 목적지로의 통신에서도 여러 통신 스트림에 대해 최고 처리량을 제공할 수 있습니다. Layer3+4는 IP 주소, 소스 포트, 목적지 포트를 고려합니다. 따라서 애플리케이션이 각 스트림에 대해 서로 다른 소스 포트를 사용할 만큼 능숙하다면 Layer2 또는 Layer2+3에 비해 처리량이 크게 향상될 것입니다.
하지만 문제는 이 해싱 알고리즘이 802.3ad를 준수하지 않아 패킷 순서가 잘못될 수 있다는 것입니다. 가능한 경우 상위 계층 프로토콜 정보를 사용합니다.
수식은 다음과 같습니다.
This policy uses upper layer protocol information, when available, to generate the hash. This allows for traffic to a particular network peer to span multiple slaves, although a single connection will not span multiple slaves. The formula for unfragmented TCP and UDP packets is hash = source port, destination port (as in the header) hash = hash XOR source IP XOR destination IP hash = hash XOR (hash RSHIFT 16) hash = hash XOR (hash RSHIFT 8) And then hash is reduced modulo slave count. If the protocol is IPv6 then the source and destination addresses are first hashed using ipv6_addr_hash. For fragmented TCP or UDP packets and all other IPv4 and IPv6 protocol traffic, the source and destination port information is omitted. For non-IP traffic, the formula is the same as for the layer2 transmit hash policy. This algorithm is not fully 802.3ad compliant. A single TCP or UDP conversation containing both fragmented and unfragmented packets will see packets striped across two interfaces. This may result in out of order delivery. Most traffic types will not meet this criteria, as TCP rarely fragments traffic, and most UDP traffic is not involved in extended conversations. Other implementations of 802.3ad may or may not tolerate this noncompliance.
여기서 중요한 경고는 이 알고리즘이 802.3ad를 완벽하게 준수하지 않는다는 것입니다. Layer3+4는 전송 순서가 잘못될 수 있습니다. 다른 802.3ad 구현에서는 이러한 비준수가 허용되지 않을 수 있습니다.
여기서는 본드의 인터페이스 전반에 트래픽이 분산될 수 있는 가능성을 확인할 수 있습니다.
그림 8은 Layer3+4의 패킷 흐름 그림을 보여줍니다.
Layer3+4 결과
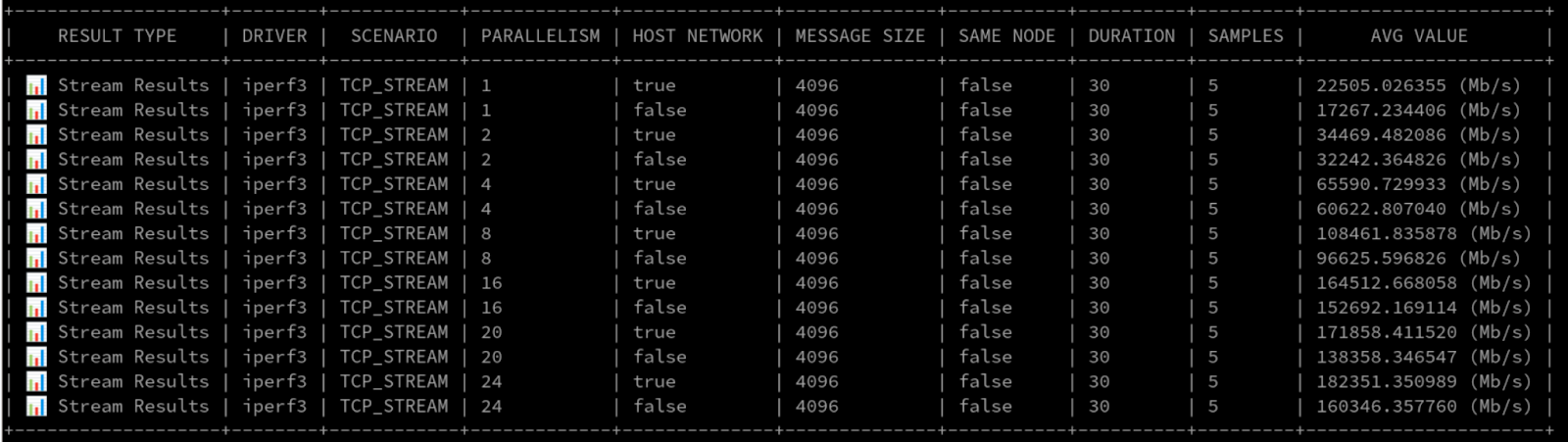
낮은 병렬 처리(최대 4개의 병렬 프로세스)에서는 Layer3+4가 Layer2/Layer2+3과 비슷한 성능을 보였습니다. 하지만 병렬 프로세스가 4개를 넘어서자 Layer3+4의 처리량이 눈에 띄게 증가했습니다. 심지어 iperf3 프로세스 24개를 사용하는 Pod 네트워크에서 160Gbps 이상의 처리량을 기록했습니다!
그림 9의 활용도 그래프는 두 인터페이스 모두 좋은 성과를 거두고 있음을 명확하게 보여줍니다.

그림 10은 인상적인 원시 숫자를 보여줍니다.
마무리하다
OpenShift의 LACP 본딩 성능에 대해 자세히 살펴보았습니다. 적절한 해싱 모드를 선택하는 것은 특정 워크로드와 패킷 순서 오류와 같은 잠재적 문제에 대한 허용 범위에 따라 달라집니다. 이 글이 온프레미스 OpenShift 배포에 대한 더욱 정확한 정보를 바탕으로 결정을 내리는 데 도움이 되기를 바랍니다.

