Red Hat Blog를 보다가 관심 가는 글이 보여서 AI번역+약간 교정해 보았습니다.
출처: https://www.redhat.com/en/blog/Improving-performance-of-multiple-I/O-threads-for-red-hat-openshift-virtualization
Red Hat OpenShift Virtualization 4.19는 데이터베이스와 같이 I/O 집약적인 워크로드의 성능과 속도를 크게 향상시킵니다. Red Hat OpenShift Virtualization의 다중 I/O 스레드는 가상 머신(VM) 디스크 I/O를 호스트의 여러 작업자 스레드로 분산하고, 이 스레드들이 VM 내부의 디스크 대기열에 매핑되도록 하는 새로운 기능입니다. 이를 통해 VM은 다중 스트림 I/O에 vCPU와 호스트 CPU를 모두 효율적으로 사용하여 성능을 향상시킬 수 있습니다.
이 글은 제 동료 제니퍼 에이브럼스의 기능 소개 글 과 함께 제공됩니다. 이어서, 더 나은 I/O 처리량을 달성하기 위해 VM을 튜닝하는 데 도움이 되는 성능 결과를 제공합니다.
테스트를 위해 Linux VM에서 fio를 합성 I/O 워크로드로 사용했습니다. 다른 애플리케이션과 Microsoft Windows에서도 테스트하기 위한 작업이 진행 중입니다.
KVM에서 이 기능이 어떻게 구현되는지에 대한 자세한 내용은 IOThread Virtqueue 매핑 에 대한 이 문서 와 Red Hat Enterprise Linux(RHEL) 환경에서 실행되는 VM의 데이터베이스 작업 부하에 대한 성능 개선을 보여주는 이 문서를 참조하세요.
테스트 설명
두 가지 구성에서 I/O 처리량을 테스트했습니다.
- Local Storage Operator(LSO) 가 프로비저닝한 Logical Volume Manager를 사용하는 로컬 스토리지 가 있는 클러스터
- OpenShift Data Foundation (ODF) 을 사용하는 별도 클러스터
구성이 매우 다르므로 비교할 수 없습니다.
Pod(기준선)와 VM에서 테스트를 진행했습니다. VM에는 16개의 코어와 8GB RAM이 할당되었습니다. VM 1개에는 512GB, VM 2개에는 256GB의 테스트 파일을 사용했습니다. 모든 테스트에서 직접 I/O를 사용했습니다. VM에는 블록 모드에서 ext4로 포맷된 영구 볼륨 클레임(PVC)을 사용했고, Pod에는 파일 시스템 모드 PVC도 ext4로 포맷했습니다. 모든 테스트는 libaio I/O 엔진을 사용하여 실행했습니다.
다음 매트릭스를 테스트했습니다.
| 매개변수 | 설정 |
| 저장 볼륨 유형 | 로컬(LSO), ODF |
| Pod/VM 수 | 1, 2 |
| I/O 스레드 수(VM만 해당) | 없음(기준선), 1, 2, 3, 4, 6, 8, 12, 16 |
| I/O 작업 | 순차적 및 무작위 읽기 및 쓰기 |
| I/O 블록 크기(바이트) | 2K, 4K, 32K, 1M |
| 동시 작업 | 1, 4, 16 |
| I/O iodepth(iodepth) | 1, 4, 16 |
ClusterBuster를 사용하여 테스트를 조정했습니다. VM은 CentOS Stream 9를 사용했고, Pod 역시 CentOS Stream을 컨테이너 이미지 기반으로 사용했습니다.
로컬 스토리지
로컬 스토리지 클러스터는 5노드(마스터 3개 + 워커 2개) 클러스터로, 각각 16코어, 2스레드(32개 CPU)를 갖춘 Intel Xeon Gold 6130 CPU 2개를 탑재한 Dell R740xd 노드로 구성되었습니다. 총 32코어, 64개 CPU를 지원합니다. 각 노드에는 192GB RAM이 장착되어 있습니다. I/O 하위 시스템은 기본 설정으로 RAID0 스트라이프 다중 장치(MD) 구성으로 구성된 Dell 브랜드 Kioxia CM6 MU 1.6TB NVMe 드라이브 4개로 구성되었습니다. lvmcluster 연산자를 사용하여 이 MD에서 영구 볼륨 클레임을 생성했습니다. 안타깝게도 이 간단한 구성이 제가 사용할 수 있는 전부였고, 더 빠른 I/O 시스템이 다중 I/O 스레드를 통해 더 큰 성능 향상을 가져올 가능성이 매우 높습니다.
오픈시프트 데이터 파운데이션
OpenShift Data Foundation(ODF) 클러스터는 6노드(마스터 3개 + 워커 3개) 클러스터였으며, 각 노드에는 AMD EPYC 9534 CPU 2개가 포함되어 있었습니다. 각 CPU는 64코어, 2스레드(128개)로 총 128코어, 256개 CPU를 지원했습니다. 각 노드에는 512GB RAM이 있습니다. I/O 하위 시스템은 노드당 5.8TB NVMe 드라이브 2개로 구성되었으며, 25GbE 기본 Pod 네트워크를 통해 3방향 복제를 지원했습니다. 이 테스트에서는 더 빠른 네트워크를 사용할 수 없었지만, 최신 네트워크 하드웨어를 사용했다면 더 나은 성능 향상을 얻을 수 있었을 것입니다.
결과 요약
이 테스트는 특정 I/O 백엔드를 사용하는 여러 I/O 스레드를 평가하는데, 이는 사용 사례를 대표하지 않을 수 있습니다. 스토리지 특성의 차이는 I/O 스레드 수 선택에 큰 영향을 미칠 수 있습니다.
제가 테스트한 결과는 다음과 같습니다.
- 최대 I/O 처리량: 로컬 스토리지의 경우, 최대 처리량은 iodepth나 로컬 스토리지의 작업 수와 관계없이 Pod와 VM 모두에서 읽기 약 7.3GB/초, 쓰기 약 6.7GB/초였습니다. 이는 하드웨어에서 기대했던 것보다 상당히 낮은 수치입니다. 각 장치(각각 4개의 PCIe Gen4 슬롯)는 읽기 6.9GB/초, 쓰기 4.2MB/초의 성능을 제공합니다. 그 이유는 아직 조사하지 않았지만, 저는 노후된 하드웨어를 사용하고 있었습니다. 최고 성능은 단일 드라이브 성능보다 분명히 우수하여 스트라이핑 효과가 있었음을 나타냅니다. ODF의 경우, 최고 성능은 읽기 약 5GB/초, 쓰기 2GB/초였습니다.
- 대용량 블록 I/O(1MB)는 시스템에 의해 성능이 이미 제한되어 있었기 때문에 거의 개선되지 않았습니다.
- 최적의 I/O 스레드 수는 워크로드와 스토리지 특성에 따라 달라집니다. 예상대로, I/O 동시성이 크지 않은 워크로드에서는 이점이 거의 없었습니다.
- 로컬 스토리지 : I/O 동시성이 높은 VM의 경우 일반적으로 4~8개가 좋은 시작점입니다. 특히 I/O 크기가 작고 동시성이 높은 워크로드의 경우, 스레드 수가 많을수록 이점을 얻을 수 있습니다.
- ODF : I/O 스레드가 두 개 이상 있어도 큰 이점이 거의 없었고, 많은 경우 전혀 필요하지 않았습니다. 이는 비교적 느린 Pod 네트워크 때문일 가능성이 높습니다. 네트워킹 속도가 더 빠르면 다른 결과가 나올 가능성이 높습니다.
- 적어도 이 테스트에서는 심층적인 비동기 I/O보다 여러 동시 작업을 처리하는 데 여러 I/O 스레드가 더 효과적으로 개선되었습니다.
- 기본 집계 최대 I/O 처리량(위에 언급됨)에 도달할 때까지 1개와 2개의 동시 VM 간에 동작에 큰 차이가 없었습니다.
- 여러 I/O 스레드는 작업 수나 I/O I/O 깊이가 낮은 Pod와의 격차를 완전히 메우지 못했습니다. 작은 작업으로 높은 I/O I/O 깊이를 사용하는 경우, VM은 쓰기 작업에서 Pod보다 상당한 성능 향상을 보였습니다.
숫자로 보면
로컬 스토리지 기반 시스템에서 여러 I/O 스레드를 사용했을 때 얻을 수 있는 전체 I/O 처리량은 다음과 같습니다. 보시다시피, 빠른 I/O 시스템에 더 작은 I/O 크기와 많은 병렬 처리가 필요한 워크로드에서는 큰 이점을 얻을 수 있습니다. 아래에서는 다양한 I/O 스레드 수를 통해 얻은 이점에 대한 자세한 내용을 제시합니다. 1MB 블록 크기에서는 성능이 이미 기본 시스템 한계에 매우 근접했기 때문에 미미한 개선만 관찰되었습니다. 더 빠른 하드웨어를 사용하면 큰 블록 크기에서도 I/O 스레드를 추가하면 성능 향상을 얻을 수 있습니다.
| 추가 I/O 스레드를 사용한 VM 기준선에 비해 가장 큰 개선 | ||||||||||
| (로컬 스토리지) | 일자리 | 아이오뎁스 | ||||||||
| 1 | 4 | 16 | ||||||||
| 크기 | 옵 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
| 2048 | 랜드레드 | 18% | 31% | 30% | 30% | 103% | 192% | 151% | 432% | 494% |
| 랜덤라이트 | 81% | 59% | 24% | 153% | 199% | 187% | 458% | 433% | 353% | |
| 읽다 | 67% | 58% | 25% | 64% | 71% | 103% | 252% | 241% | 287% | |
| 쓰다 | 103% | 64% | 0% | 143% | 99% | 84% | 410% | 250% | 203% | |
| 총 2048개 | 67% | 53% | 20% | 97% | 118% | 141% | 318% | 339% | 334% | |
| 4096 | 랜드레드 | 18% | 34% | 28% | 33% | 101% | 208% | 156% | 432% | 492% |
| 랜덤라이트 | 95% | 69% | 20% | 149% | 200% | 187% | 471% | 543% | 481% | |
| 읽다 | 26% | 53% | 27% | 24% | 46% | 66% | 142% | 155% | 165% | |
| 쓰다 | 103% | 69% | 0% | 144% | 86% | 48% | 438% | 256% | 161% | |
| 총 4096개 | 60% | 56% | 19% | 87% | 108% | 127% | 302% | 346% | 325% | |
| 32768 | 랜드레드 | 16% | 23% | 26% | 23% | 71% | 124% | 99% | 160% | 129% |
| 랜덤라이트 | 75% | 71% | 28% | 108% | 132% | 116% | 203% | 123% | 115% | |
| 읽다 | 21% | 57% | 25% | 21% | 42% | 32% | 77% | 54% | 32% | |
| 쓰다 | 79% | 64% | 26% | 104% | 59% | 24% | 195% | 45% | 27% | |
| 총 32768개 | 48% | 53% | 26% | 64% | 76% | 74% | 143% | 96% | 76% | |
| 1048576 | 랜드레드 | 5% | 2% | 0% | 9% | 0% | 0% | 17% | 0% | 0% |
| 랜덤라이트 | 10% | 0% | 1% | 6% | 0% | 2% | 9% | 0% | 2% | |
| 읽다 | 12% | 18% | 0% | 9% | 0% | 0% | 16% | 0% | 0% | |
| 쓰다 | 19% | 0% | 0% | 7% | 0% | 0% | 9% | 0% | 0% | |
| 총 1048576개 | 11% | 5% | 0% | 8% | 0% | 1% | 13% | 0% | 0% | |
최대 16개의 I/O 스레드로 달성 가능한 최고 결과의 90%를 달성하는 데 필요한 I/O 스레드 수는 다음과 같습니다. 예를 들어, 특정 작업, 블록 크기, 작업 및 I/O 깊이 조합으로 테스트에서 얻은 최고 결과가 1GB/초였다면, 이 지표는 900MB/초를 달성하는 데 필요한 최소 스레드 수가 됩니다. 이를 통해 좋은 성능을 유지하면서도 스레드 수를 보수적으로 설정할 수 있습니다.
| 최상의 성능의 90%를 달성하기 위한 최소 iothread 수 | ||||||||||
| (로컬 스토리지) | 일자리 | 아이오뎁스 | ||||||||
| 1 | 4 | 16 | ||||||||
| 크기 | 옵 | 1 | 4 | 16 | 1 | 4 | 16 | 1 | 4 | 16 |
| 2048 | 랜드레드 | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
| 랜덤라이트 | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
| 읽다 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 6 | 8 | |
| 쓰다 | 1 | 1 | 0 | 2 | 12 | 6 | 8 | 6 | 6 | |
| 총 2048개 | 1 | 1 | 1 | 2 | 9 | 8 | 6 | 9 | 10 | |
| 4096 | 랜드레드 | 1 | 1 | 1 | 1 | 4 | 8 | 3 | 12 | 12 |
| 랜덤라이트 | 1 | 1 | 1 | 3 | 16 | 12 | 8 | 12 | 12 | |
| 읽다 | 1 | 1 | 1 | 1 | 2 | 3 | 3 | 6 | 8 | |
| 쓰다 | 1 | 1 | 0 | 3 | 12 | 4 | 8 | 6 | 4 | |
| 총 4096개 | 1 | 1 | 1 | 2 | 9 | 7 | 6 | 9 | 9 | |
| 32768 | 랜드레드 | 1 | 1 | 1 | 1 | 3 | 6 | 2 | 4 | 3 |
| 랜덤라이트 | 1 | 1 | 1 | 2 | 12 | 6 | 4 | 3 | 3 | |
| 읽다 | 1 | 1 | 1 | 1 | 2 | 2 | 2 | 2 | 2 | |
| 쓰다 | 1 | 1 | 1 | 2 | 6 | 2 | 4 | 2 | 1 | |
| 총 32768개 | 1 | 1 | 1 | 2 | 6 | 4 | 3 | 3 | 2 | |
| 1048576 | 랜드레드 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 랜덤라이트 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 읽다 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
| 쓰다 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 총 1048576개 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | |
자세한 결과
측정된 각 테스트 사례에 대해 다음과 같은 성능 지표를 계산했습니다.
- I/O 처리량 측정
- 최상의 VM 성능(직접 보고되지 않음)
- 최상의 VM 성능의 90%를 달성하기 위한 최소 iothread 수
- 최상의 VM 성능과 Pod 성능의 비율
- 기준 VM 성능에 비해 최상의 VM 성능 향상
최상의 성능을 위한 스레드 수를 보고하는 것이 아닙니다. 많은 경우 차이가 매우 작아 I/O 성능 보고에서 나타나는 일반적인 분산보다 작았기 때문입니다.
로컬 스토리지와 ODF의 결과는 특성이 너무 다르기 때문에 별도로 요약하여 제공합니다.
아래의 모든 성능 그래프는 X축에 포드(pod), I/O 스레드가 없는 기준 VM(0), 그리고 지정된 수의 I/O 스레드에 대한 결과를 표시합니다.
로컬 스토리지
원시 성능을 살펴보면, 적어도 일부 경우에는 여러 I/O 스레드를 사용하는 것이 상당한 이점을 제공한다는 것을 알 수 있습니다. 예를 들어, 16개의 작업에서 iodepth가 1인 비동기 I/O를 실행하고 로컬 스토리지에서 추가 I/O 스레드를 사용하면 훨씬 더 큰 이점을 얻을 수 있습니다.
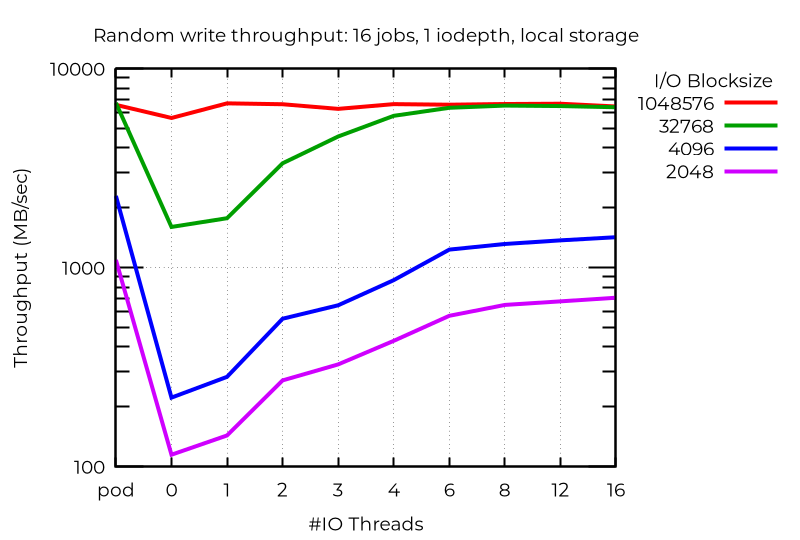
단일 스트림 I/O를 사용하더라도 추가 I/O 스레드를 사용하면 이점을 얻을 수 있습니다. 당연하게도, 하나 이상 사용하는 것은 도움이 되지 않습니다.

추가 I/O 스레드가 실제로 성능을 저하시키는 비정상적인 사례가 있습니다. 이 경우, 작은 블록으로 심층 비동기 I/O를 사용하면 전용 I/O 스레드를 사용하지 않는 VM에서 실제로 최상의 성능(포드보다 더 나은 성능)을 얻을 수 있습니다. 왜 이런 현상이 발생하는지는 아직 밝혀지지 않았습니다.
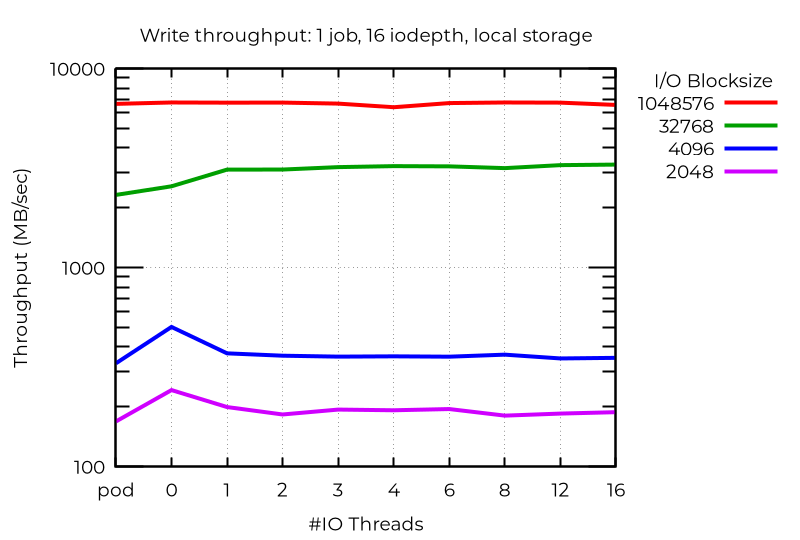
이 모든 것은 여러 I/O 스레드에서 최상의 성능을 얻으려면 특정 작업 부하를 실험해야 한다는 것을 보여줍니다.
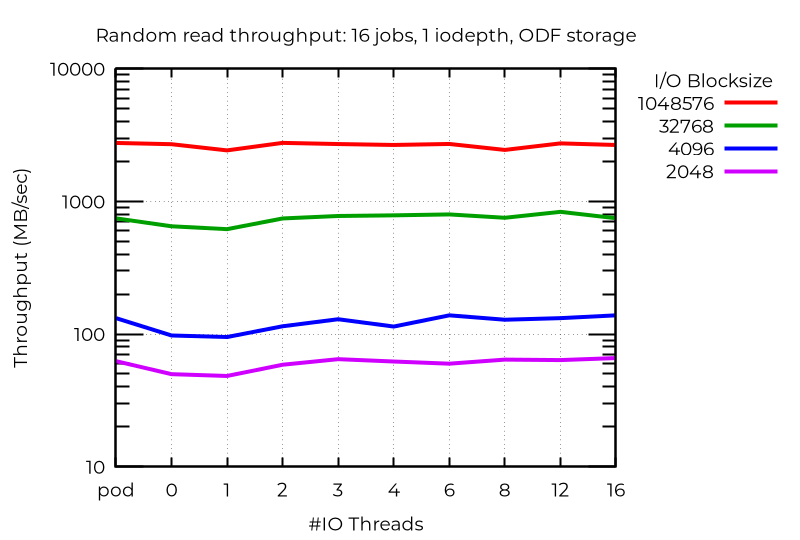
ODF 클러스터 결과
로컬 스토리지에서는 여러 I/O 스레드를 사용할 때 작은 블록의 임의 쓰기 성능이 크게 향상되었지만, ODF에서는 작업 수가 많더라도 성능 향상이 미미했습니다. 네트워킹 속도가 더 빠르거나 지연 시간이 짧을수록 더 큰 효과를 볼 수 있을 것으로 예상됩니다. 읽기 작업, 특히 임의 읽기는 약간의 효과를 보였지만, 쓰기 작업과 작업 수가 적을 때는 효과가 거의 없었습니다.
결론
OpenShift 가상화를 위한 다중 I/O 스레드는 OpenShift 4.19의 흥미로운 새 기능으로, 동시 I/O가 발생하는 워크로드, 특히 테스트에 사용된 로컬 NVMe 스토리지와 같은 고속 I/O 시스템에서 I/O 성능을 크게 향상시킬 수 있는 잠재력을 제공합니다. 기본 베어 메탈 I/O를 완전히 구동하려면 더 많은 CPU가 필요하므로, 더 빠른 I/O 하위 시스템이 다중 I/O 스레드의 이점을 가장 크게 누릴 것으로 예상됩니다. I/O의 경우 항상 그렇듯이, I/O 시스템과 전체 워크로드의 차이는 성능에 큰 영향을 미칠 수 있으므로 이 새로운 기능을 최대한 활용하려면 직접 워크로드를 테스트해 보는 것이 좋습니다. 제 테스트 결과가 I/O 스레드를 선택하는 데 도움이 되기를 바랍니다!

