이 글은 딥 러닝 신경망 아키텍처의 메모리 소비에 대해 더 깊이 파고듭니다. 입력이 신경망에 제시될 때 정확히 어떤 일이 일어나며, 왜 데이터 과학자들은 주로 메모리 부족 오류로 어려움을 겪습니까? 자연어 처리(NLP) 외에도, 컴퓨터 비전은 딥 러닝 네트워크의 가장 인기 있는 응용 프로그램 중 하나입니다. 우리들 대부분은 컴퓨터 시각의 한 형태를 매일 사용합니다. 예를 들어, 우리는 얼굴 인식을 사용하여 전화기를 잠금 해제하거나 번호판 인식을 사용하여 주차 구조를 부드럽게 빠져나가는 데 사용합니다. 그것은 당신의 의학적 진단을 돕기 위해 사용됩니다. 아니면, 이 단락을 해피노트로 끝내려면, 여러분의 핸드폰에 있는 모든 강아지 사진을 찾으세요.
사진 속 고양이와 개를 구별하기 위해 이미지 분류를 사용하는 것에 대해 많은 내용이 논의되지만, 애완동물 프로젝트의 범위를 넘어 살펴봅니다. 많은 조직이 이미지 분류, 개체 식별, 에지 인식 또는 패턴 검색을 비즈니스 프로세스에 적용하여 수익을 증대하거나 비용을 절감할 수 있는 방법을 찾고 있습니다. 이러한 기능을 통합한 애플리케이션을 플랫폼에 예상할 수 있습니다.
이 시리즈의 3부에서는 배치 크기를 다루었고 32개의 배치 크기를 언급했는데, 이것은 오늘날에는 적은 숫자처럼 보입니다. 압축되지 않은 8K 이미지(7680 x 4320)는 265MB를 사용합니다. 최신 데이터 센터 GPU의 메모리 용량은 16GB에서 80GB 사이입니다. 328K jpeg (896MB)는 고사하고 32개 이상의 압축되지 않은 (8GB) 8K 이미지를 쉽게 장착할 수 있다고 주장할 수 있습니다. 데이터 과학 포럼에서 메모리 소비에 대한 질문이 많은 이유는 무엇입니까? 왜 가장 일반적으로 사용되는 데이터 세트와 신경망은 224 x 224 이미지 크기를 맴도는 치수의 이미지에 초점을 맞추고 있습니까?
신경망의 메모리 소비는 많은 요인에 의해 결정됩니다. 사용되는 네트워크 아키텍처와 그 깊이와 같은 것입니다. 이미지 크기 및 배치 크기입니다. 그리고 그것이 훈련 작전인지 아니면 추론 작전인지도요. 이 기사는 결코 신경망에 대한 심층 강좌가 아니다. 저는 여러분이 스탠포드 대학의 CS231n을 팔로우하거나 fast.ai에서 무료 온라인 강좌에 등록하는 것을 추천합니다. 신경망을 조금 더 파고들어, 신경망의 구조와 그 구성 요소를 탐색하고, 이미지가 왜 많은 메모리를 소비하는지 알아봅시다.
워크로드 특성을 이해하면 리소스 관리, 문제 해결 및 용량 계획에 도움이 됩니다. 이 시리즈의 후반부에서 부분적인 vGPU 및 다중 GPU에 대해 다루면 이러한 기능 요구 사항을 플랫폼의 기술 기능에 더 쉽게 매핑할 수 있습니다. 그럼 양파의 첫 번째 층을 벗겨서 천천히 시작하고 이미지 분류를 위해 일반적으로 사용되는 신경 네트워크 아키텍처인 컨볼루션 신경망을 살펴봅시다.
컨볼루션 신경망
CNN(Convolutional Neural Network)은 이미지에서 패턴과 객체를 효율적으로 인식하고 캡처하며 컴퓨터 비전 작업의 핵심 구성 요소입니다. CNN은 다층 신경 네트워크이며 세 가지 유형의 계층으로 구성됩니다. 컨볼루션 계층, 풀링 계층, 완전히 연결된 계층입니다. 신경망의 첫 번째 부분은 특징 추출을 담당하며 컨볼루션 및 풀링 레이어로 구성됩니다. 컨볼루션 레이어 단락에서 그것이 정확히 무엇인지 설명하겠습니다. 네트워크의 두 번째 부분은 완전히 연결된 계층과 소프트맥스 계층으로 구성됩니다. 이 파트는 이미지 분류를 담당합니다.

컨볼루션 레이어
컨볼루션 레이어는 피처 추출을 수행하는 CNN의 중추입니다. 기능은 (번호판) 번호의 가장자리 또는 슈퍼마켓 항목의 윤곽이 될 수 있습니다. 기능 추출은 이미지를 세부 사항으로 분해하는 것이며, 네트워크에 깊이 들어갈수록 기능이 더 상세해집니다.
CNN은 이미지를 처리하지만, 컴퓨터는 어떻게 이미지를 볼 수 있을까요? 컴퓨터에게 이미지는 숫자에 불과합니다. 색상 이미지, 즉 RGB 이미지는 각 빨간색, 녹색 및 파란색 채널에 대한 값을 가지며, 이 픽셀 표현은 분류 파이프라인의 기반이 됩니다.
영어를 모국어로 하지 않는 사람들에게, convolution (layer)은 convolute (make an argument complex)과 혼동해서는 안 됩니다. 컨볼루션 계층에는 “결합” 또는 다른 요소에 의해 어떤 것이 어떻게 수정되는지를 의미하는 컨볼루션 작용이 있습니다. 이 경우 컨볼루션 레이어는 두 행렬 사이에 점 곱을 수행하여 활성화가 포함된 피쳐 맵을 생성합니다. 두려워하지 마세요. 선형대수학 수업은 되지 않을 것입니다. (노력해도 할 수 없을 거예요.) 그러나 우리는 신경 네트워크 내의 파이프라인 전체의 메모리 소비를 더 잘 이해하기 위해 컨볼루션 프로세스와 그 구성 요소를 높은 수준에서 살펴볼 필요가 있습니다.
신경망은 파이프라인이며, 이는 프로세스의 출력이 다음 프로세스의 입력임을 의미합니다. 컨볼루션 레이어에는 입력 배열, 필터 및 출력 배열의 세 가지 구성 요소가 있습니다. CNN의 초기 입력은 이미지이며 입력 배열(값의 매트릭스)입니다. 컨볼루션 계층은 커널 또는 필터로 알려진 피쳐 디텍터를 적용하며, 이를 가장 쉽게 설명하는 방법은 슬라이딩 창입니다. 매트릭스 형태로도 구성된 이 슬라이딩 윈도우는 신경망의 가중치를 포함합니다. 가중치는 훈련 중에 조정되는 신경 네트워크에서 학습 가능한 매개 변수입니다. 가중치는 랜덤 값으로 시작하며, 교육이 계속됨에 따라 치우침(bias, 다른 매개 변수)과 함께 정확한 출력을 제공하는 값으로 조정됩니다. 가중치와 편향은 훈련 중에 메모리에 저장되어야 하며 훈련된 네트워크의 핵심 IP입니다. 일반적으로 CNN은 필터당 적용되는 가중치 수를 결정하는 표준 커널(필터) 높이 및 너비 크기를 사용합니다. 일반적인 커널 크기는 3 x 3입니다. 이 필터는 첫 번째 컨볼루션 레이어인 이미지의 경우 입력 배열에 적용됩니다. 앞서 언급한 바와 같이, 컨볼루션 레이어는 두 matrices 사이에 dot product을 수행하여 활성화가 포함된 피쳐 맵을 생성합니다. 더 나은 이해를 위해 이미지를 살펴보도록 하겠습니다.

이 예에서는 3×3 필터가 6×6 이미지에 적용됩니다(보통 이미지 치수는 224 x 224). 이 커널 또는 필터 크기를 수용 필드라고 합니다. 이 프로세스 동안 필터는 커널의 값에 하이라이트 입력 배열 필드의 모든 값을 곱한 다음 “제품”을 추가하여 활성화라는 단일 값을 계산합니다.
Output = (1*1)+(2*4)+(1*1)+(4*1)+(2*3)+(1*5)+(0*9)+(1*1)+(1*3)=1+8+1+4+6+5+0+1+3=29활성화가 계산되면 필터가 스트라이드 설정에 의해 결정되는 여러 픽셀 위로 이동합니다. 일반적으로 이 값은 1 또는 2픽셀입니다. 그리고 그 과정을 반복하죠. 전체 입력 배열이 처리되면 출력 배열이 완료됩니다. 그리고 새 필터가 입력 배열에 적용됩니다. 이 출력 배열을 피쳐 맵 또는 활성화 맵이라고 합니다.
각 컨볼루션 계층에는 미리 정의된 개수의 필터가 있으며, 각 필터에는 서로 다른 가중치 구성이 있습니다. 각 필터는 다음 컨볼루션 또는 풀링 레이어에 대한 입력으로 변환되는 자체 피쳐 맵을 만듭니다. 필터당 하나의 바이어스 매개 변수가 적용됩니다. 매개 변수 단락은 이러한 관계가 메모리 소비에 미치는 영향을 명확하게 설명합니다.
풀링 계층
풀링 계층은 여러 컨볼루션 계층을 따릅니다. 중요한 정보를 잃지 않고 이전 계층의 중요한 부분을 요약합니다. 예를 들어 필터를 사용하여 케첩 병의 윤곽을 감지한 다음 풀링 레이어를 사용하여 케첩 병의 정확한 위치를 가리는 것입니다. 네트워크의 특정 단계에서 병의 위치를 알 필요가 없습니다. 따라서 풀링 계층은 불필요한 세부 정보를 걸러내고 네트워크가 가장 중요한 기능에 집중되도록 합니다. 풀링 계층을 도입하는 이유 중 하나는 네트워크 전체에서 매개 변수를 최대한 줄여 복잡성과 계산 부하를 줄이기 위함입니다. 이전 피쳐 맵을 통합하기 위해 특정 영역의 숫자 평균(평균 풀링) 또는 특정 영역에서 탐지된 최대값(최대 풀링)을 사용합니다. 입력에 적용된 필터와 유사하게 크기가 훨씬 작으며(2 x 2) 이동(스트라이드)이 훨씬 큽니다(2 픽셀). 결과적으로, 각 형상 맵의 크기는 2배, 즉 각 치수가 절반으로 줄어듭니다.
피쳐 맵의 수는 이전 계층과 동일합니다.
중요한 세부 사항은 이 계층에 가중치나 편향이 없다는 것입니다. 그 결과, 훈련 불가능한 계층입니다. 그것은 네트워크의 학습 기능이라기보다는 운영입니다. 이는 레이어의 전체 메모리 소비량에 영향을 미치며, 뒷부분에서 이를 발견하게 될 것입니다.
완전히 연결된 계층
완전히 연결된 레이어는 신경망의 전형적 아이입니다. 신경망의 이미지나 아이콘을 찾아보면 완전히 연결된 레이어에 대한 아티스트의 인상을 받을 수 있습니다. 완전히 연결된 계층에는 다음 계층의 각 뉴런에 연결된 뉴런 집합(수학 함수의 자리 표시자)이 포함됩니다.
이미지 분류를 수행하는 것은 완전히 연결된 레이어의 작업입니다. 컨볼루션 레이어의 파이프라인 전체에서 필터는 이미지의 특정 기능을 감지하고 전체 그림을 “보기”하지 않습니다. 그들은 특정한 특징들을 감지하고, 그것을 모두 하나로 묶는 것이 완전히 연결된 계층들의 작업입니다. 완전히 연결된 첫 번째 도면층은 마지막 풀링 도면층의 피쳐 맵을 가져와서 행렬을 단일 벡터로 평탄화합니다. 그것은 그것의 층에 있는 뉴런에 입력을 공급하고 정확한 라벨을 예측하기 위해 가중치를 적용합니다.
매개 변수 메모리 소비량
우리에게 흥미로운 것은 메모리를 소비할 때 수반되는 매개 변수의 수입니다. 각 네트워크 아키텍처는 레이아웃과 매개 변수 수가 다릅니다. AlexNet(2012), GoogleLeNet(2014), VGG(2014) 및 ResNet(2017)과 같은 여러 CNN 아키텍처가 있습니다. 오늘날 ResNet과 VGG-16은 가장 인기 있는 CNN 아키텍처로, 훈련과 이전 학습을 비교하는 가장 정확한 아키텍처를 찾기 위해 종종 서로 경쟁합니다. ResNet-50 vs VGG-19 vs training from scratch: A comparative analysis of the segmentation and classification of Pneumonia from chest X-ray images은 매혹적인 읽을거리입니다.
VGG-16 신경망 아키텍처를 예제 CNN으로 사용하여 메모리 소비를 더 잘 이해하겠습니다. VGG-16은 잘 문서화된 네트워크이기 때문에 내 계산이 의심스럽다면 다른 곳에서 쉽게 확인할 수 있습니다. VGG-16에는 13개의 컨볼루션 계층, 5개의 Max Pooling 계층 및 3개의 완전히 연결된 계층이 있습니다. 모든 계층을 세어 보면 21개까지 합친다는 것을 알 수 있지만, VGG-16의 16개 계층은 학습 가능한 매개 변수를 가진 16개 계층을 의미합니다. 아래 그림은 일반적으로 사용되는 신경 네트워크 구성을 보여 줍니다.
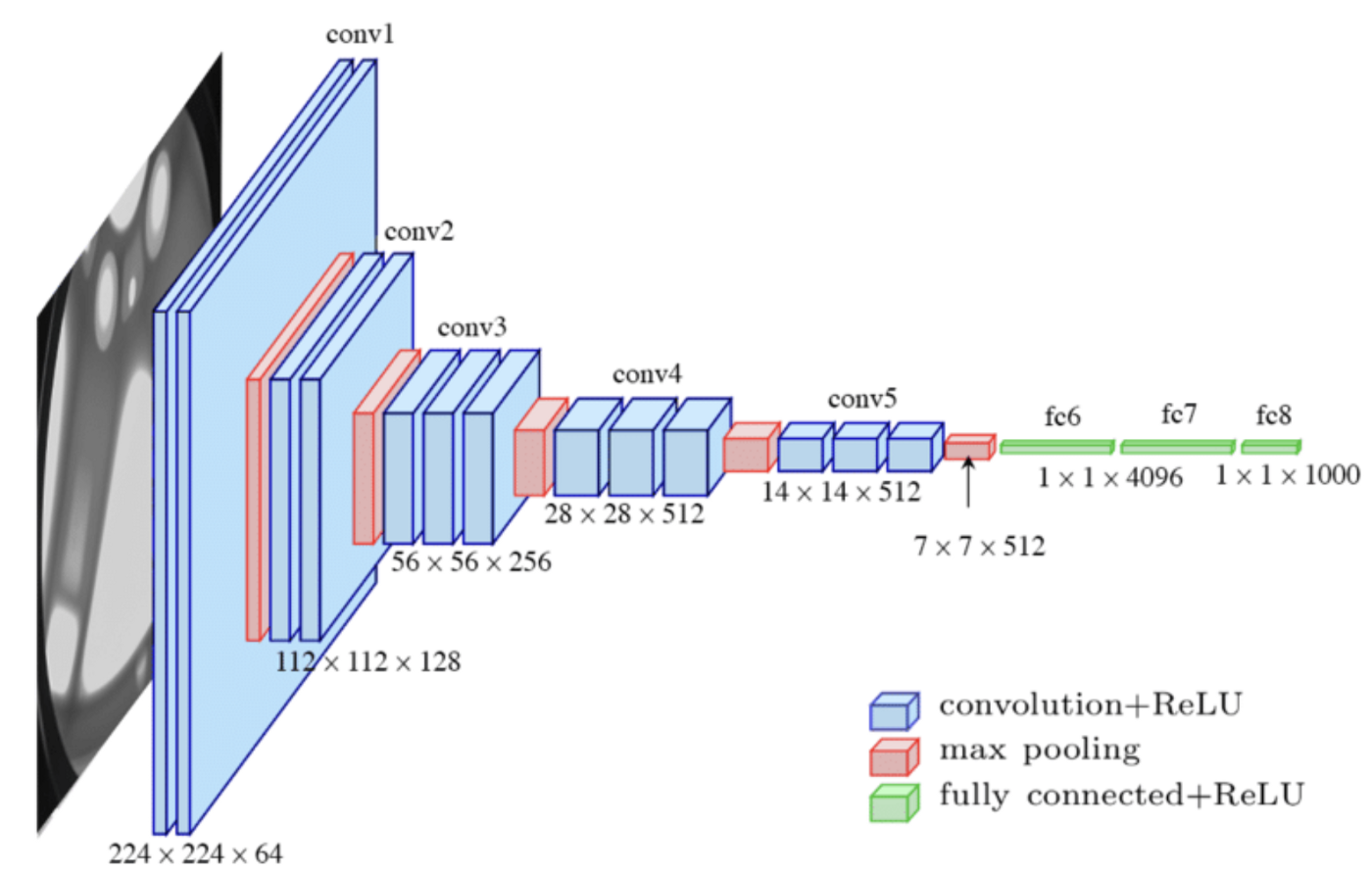
메모리 소비는 주로 매개 변수(무게 및 바이어스)를 저장하는 데 사용되는 두 가지 중요한 범주 메모리와 기능 맵의 활성화를 위해 저장된 메모리로 나뉩니다. 피쳐 맵 메모리 소비량은 이미지의 높이, 이미지의 너비 및 배치 크기에 따라 달라집니다. 파라미터의 메모리는 이미지 또는 배치 크기에 관계없이 일정하게 유지됩니다. 먼저 신경망의 메모리 소비 매개 변수를 살펴보겠습니다.
VGG-16 네트워크는 224 x 224 크기의 이미지를 RGB로 수신합니다. 즉, 3개의 입력 채널이 있습니다. 이 단계에서는 이미지 치수가 메모리 계산과 관련이 없습니다. 첫 번째 컨볼루션 레이어는 64개의 필터를 적용합니다(구조 다이어그램에 224 x 224 x 64로 명시됨). 커널 크기가 3 x 3인 필터를 적용하므로 3개의 입력 배열(Red channel, Blue channel, Green channel)에 3 x 3 (9) 무게의 커널을 적용하는 64개의 개별 필터를 계산합니다. 이 레이어에 적용된 가중치의 수는 1,728개입니다. 필터당 하나의 바이어스가 적용되어 이 컨볼루션 레이어의 총 매개 변수가 1,792개로 증가합니다. 각 가중치는 메모리에 부동 소수점 번호(부동 소수점 번호)로 저장되며, 각 단일 정밀 부동 소수점(FP32)은 4바이트를 차지하므로 메모리 설치 공간이 7KB입니다. 이 시리즈의 다음 기사에서는 부동 소수점 유형이 메모리 소비에 미치는 영향에 대해 설명합니다.

두 번째 계층은 첫 번째 컨볼루션 계층(CL)에 의해 생성된 64개의 피쳐 맵을 입력으로 사용합니다. 3 x 3 커널과 64개의 필터를 사용합니다. 계산은 9개의 가중치를 사용하여 64개의 입력 x 64개의 개별 필터로 변환됩니다. 각 필터는 36.864 가중치 + 64 바이어스 = 36928 매개 변수 x 4바이트 = 147kb와 같습니다.
풀링 계층은 커널 크기가 2 x 2이고 보폭이 2인 최대 풀링 작업을 적용합니다. 본질적으로 마지막 피쳐 맵의 매트릭스 크기를 절반으로 줄이는 것입니다. 피쳐 맵의 정확한 수는 남아 있으며 가중치가 포함되지 않으므로 다음 컨볼루션 레이어의 입력으로 작동합니다. 아니요, 매개 변수 관점에서 사용된 메모리 공간이 없습니다.
7kb와 147kb는 확실히 놀라운 수치는 아니지만, 이제 네트워크의 나머지 부분을 보겠습니다. 보시다시피, 메모리 매개 변수는 네트워크의 컨볼루션 레이어 전체에서 천천히 증가하다가 완전히 연결된 레이어에서 극적으로 폭발합니다. 흥미로운 점은 네트워크의 기능 추출 부분의 마지막 풀 계층 뒤에 평탄화 작업이 있다는 것입니다. 이 작업은 풀링된 피쳐 맵을 단일 열로 평탄화하여 완전히 연결된 레이어를 통과할 수 있는 입력 데이터의 긴 벡터를 생성합니다. 7 x 7의 512 행렬은 25,088개의 활성화가 포함된 단일 벡터로 바뀝니다(확대하려면 이미지를 클릭하십시오).

전체적으로 네트워크는 가중치와 편향을 저장하는 데 540MB가 필요합니다. 이를 에지 장치에 구축하는 것을 고려한다면 상당한 면적이 될 것입니다. 하지만 더 큰 물고기는 항상 있습니다. 텍스트를 생성하기 위한 최첨단(SOTA) 신경망인 GPT-3 또는 3세대 사전 훈련된 트랜스포머에는 1750억 개의 매개 변수가 있습니다. 단일 정밀 부동 소수점(FP32)을 사용할 경우 700GB의 메모리가 필요합니다. 대부분의 기업은 비즈니스 프로세스를 개선하기 위해 GPT-3 모델을 사용하지 않지만, 일부 신경망이 가질 수 있는 메모리 설치 공간의 범위를 보여줍니다.
| 네트워크 구조 | 컨볼루션 계층 수 | 완전 연결 레이어 수 | 파라미터 수 |
|---|---|---|---|
| AlexNet | 5 | 3 | 2억3천8백만 |
| GoogLeNet | 21 | 1 | 4천만 |
| ResNet | 49 | 1 | 5천만 |
| VGG-16 | 13 | 3 | 5억4천만 |
피쳐 맵 메모리 소비량
피쳐 맵의 메모리 소비는 상대적으로 간단한 계산, 즉 형상 맵의 이미지 x 번호의 치수입니다. 피쳐 맵에는 입력 어레이를 가로질러 이동하는 필터의 활성화가 포함됩니다. 각 컨볼루션 계층은 이전 계층의 피쳐 맵을 수신하고 각 풀링은 피쳐 맵의 크기를 절반으로 줄입니다.
피쳐 맵 메모리 소비는 가중치가 있는 커널이 이미지 사이를 이동할 때 이미지의 크기에 따라 달라집니다. 이미지가 클수록 활성화 횟수가 증가합니다. 배치 크기는 메모리 사용량에도 영향을 미칩니다. 이미지가 많을수록 메모리에 저장할 활성화가 많아집니다. 네트워크는 이미지 배지를 병렬로 실행합니다. 배치 크기가 32이고 기본 이미지 크기가 224 x 224인 경우 메모리 소비량은 224 x 224 x 64 채널 x 32 이미지 = 102.760.448 x 4바이트(플로트로 저장됨) = 401.40MB가 됩니다.
한 발짝 뒤로 물러나요. 평균적으로 224 x 224 이미지는 하드 드라이브의 19kb 공간을 차지합니다. 일부 빠른 계산은 32개의 이미지가 602KB를 소비한다는 것을 알려줍니다. 그것은 화려한 고밀도 드라이브가 아니라 이중 밀도의 3.5인치 플로피 디스크 드라이브에도 쉽게 들어갈 수 있습니다. 그리고 이제, 첫 번째 컨볼루션 이후, 401MB가 조금 넘는 용량을 차지합니다. 아, 네, 그리고 파라미터는 7kb입니다.
흥미롭게도, 우리는 네트워크의 끝을 향해 이동하는 동안 매개 변수의 메모리 공간이 증가하는 것을 발견했습니다. 풀링 계층이 각 기능 맵의 크기를 줄이면 기능 맵당 메모리 설치 공간이 단순해집니다. GPU 장치의 추론 요구 사항에 유의해야 합니다! 하지만 그건 나중에 자세히 다루겠습니다. 배치를 반복하는 동안 244 x 244 차원의 32개 이미지는 약 1.88GB의 메모리를 사용합니다. (확대하려면 이미지를 클릭하십시오.)

VGG-16 네트워크에서 가능한지 여부를 무시하고 동일한 산술을 4K 이미지에 적용한 경우 3840 x 2160 이미지의 메모리 소비량은 한 이미지에 약 9.6GB, 32개 이미지에 약 307,2GB가 됩니다. 즉, 데이터 과학자는 배치 크기를 줄이는 것 중 하나를 선택해야 하므로 교육 시간 증가에 동의해야 합니다. 또는 사용 가능한 GPU 메모리를 늘리기 위해 이미지 크기를 미리 처리하고 축소하거나 여러 GPU에 distributing the model하는 데 더 많은 시간을 할애할 수 있습니다.
교육 대 추론
이미지 배치가 소프트맥스 레이어에 도달하면 출력이 생성됩니다. 그리고 이 시점부터, 우리는 그것이 이후의 메모리 소비를 이해하기 위한 훈련인지 추론인지 구별해야 합니다.
위의 단락에서 설명한 프로세스는 정방향 전파 또는 일반적으로 정방향 통과라고 합니다. 이 전진 패스는 훈련 및 추론 작업 모두에 존재합니다. 훈련을 위해서는 역주행 또는 역주행과 같은 추가 과정이 필요합니다.
그리고 이것을 완전히 이해하기 위해서는, 우리는 선형대수와 미적분을 깊이 연구해야 합니다. 그리고 여러분은 이미 이 글에 2600개의 단어를 깊이 파고들었습니다. 이 모든 것은 지도 학습 방법을 통해 이미지 분류를 교육하는 것으로 귀결됩니다. 즉, 이미지 세트가 해당 레이블과 함께 교육됩니다. 이미지 또는 배치 훈련이 완료되면 네트워크는 예상 값(이미지 레이블)과 관측 값(전진 패스에 의해 생성된 값) 간의 차이를 계산하여 총 오류를 확인합니다.
네트워크는 “손실”을 최소화하기 위해 어떤 가중치가 오류의 가장 큰 원인이며 어떤 가중치를 변경해야 하는지 파악해야 합니다. 손실이 0이면 레이블이 정확합니다. 각 무게에 대한 오차의 부분 미분을 계산하여 이 작업을 수행합니다. 그게 무슨 의미죠? 기본적으로 각 가중치는 서로 연결된 다른 가중치로 인해 손실의 원인이 됩니다. 수학에서 파생된 것은 변수에 대한 함수의 변화율입니다. 신경망의 경우, 오류율을 얼마나 빠르게 올리거나 낮출 수 있는지 말입니다. 이 일반적인 묘사를 통해, 저는 이 예술 양식의 더 세밀한 부분들을 잃어버리고 있지만, 무슨 일이 일어나고 있는지 이해하는 것은 도움이 됩니다. 차이에 학습률을 곱하고 계산 결과를 각 가중치에서 뺍니다.
결과적으로 역전파에는 각 체중의 그레이디언트와 학습 속도를 저장할 공간이 필요합니다. 매개 변수의 메모리 소비량은 교육 중에 대략 두 배가 됩니다. 데이터 과학자가 ADAM과 같은 최적화 도구를 사용하는 경우 메모리 소비량이 3배로 증가할 것으로 예상하는 것이 일반적입니다. 주의할 점은 활성화(피처 맵)의 메모리 소비 기간이 신경망이 미분을 계산해야 하는 한 유지된다는 것입니다.
추론을 사용하면 메모리 소비량이 상당히 다릅니다. 신경망은 최적화된 가중치를 가지고 있으므로 전진 패스만 필요하며, 메모리에서는 매개 변수만 활성화하면 됩니다. 역전파 패스가 없습니다. 더 좋은 것은, 활성화가 짧은 기간이라는 것입니다. 포워드 패스가 새 계층으로 이동하면 활성화가 삭제됩니다. 따라서 메모리 소비 계산을 위해 모델 매개 변수와 가장 “비싼” 두 개의 연속 계층만 고려하면 됩니다. 일반적으로 이러한 계층은 처음 두 계층입니다. 메모리에서 활성 상태인 계층과 계산되는 계층입니다. 이것은 추론용 GPU가 거대한 장치일 필요는 없다는 것을 의미합니다. 네트워크 매개 변수를 연속적으로 유지하고 일시적으로 두 개의 피쳐 맵만 유지하면 됩니다. 이러한 사실을 알고 있다면 에지/추론 배포를 위해 다양한 솔루션을 찾는 것이 좋습니다.
| Training | Inference | |
|---|---|---|
| Memory Footprint | 대용량 메모리 공간 전방 전파 경로 – 후방 전파 경로 – 모델 매개 변수 활성화의 메모리 설치 공간이 오래 지속됩니다(메모리 설치 공간의 상당 부분). | 작은 메모리 공간 전달 경로 – 모델 매개 변수 활성화는 수명이 짧습니다(총 메모리 설치 공간 = 최대 2개 연속 계층) |
출처 : https://frankdenneman.nl/2022/07/15/training-vs-inference-memory-consumption-by-neural-networks/





