Proxmox VE 매뉴얼을 Google Translate로 기계번역하고, 살짝 교정했습니다.
https://pve.proxmox.com/pve-docs/pve-admin-guide.html
version 8.1.4, Wed Mar 6 18:21:39 CET 2024
8.1. 소개
Proxmox VE는 컴퓨팅 및 스토리지 시스템을 통합합니다. 즉, 컴퓨팅(VM 및 컨테이너 처리)과 복제된 스토리지 모두에 대해 클러스터 내에서 동일한 물리적 노드를 사용할 수 있습니다. 컴퓨팅 및 스토리지 리소스의 기존 사일로를 단일 하이퍼 컨버지드 어플라이언스로 묶을 수 있습니다. 별도의 스토리지 네트워크(SAN)와 NAS(Network Attached Storage)를 통한 연결이 사라집니다. 오픈 소스 소프트웨어 정의 스토리지 플랫폼인 Ceph가 통합되어 Proxmox VE는 하이퍼바이저 노드에서 직접 Ceph 스토리지를 실행하고 관리할 수 있습니다
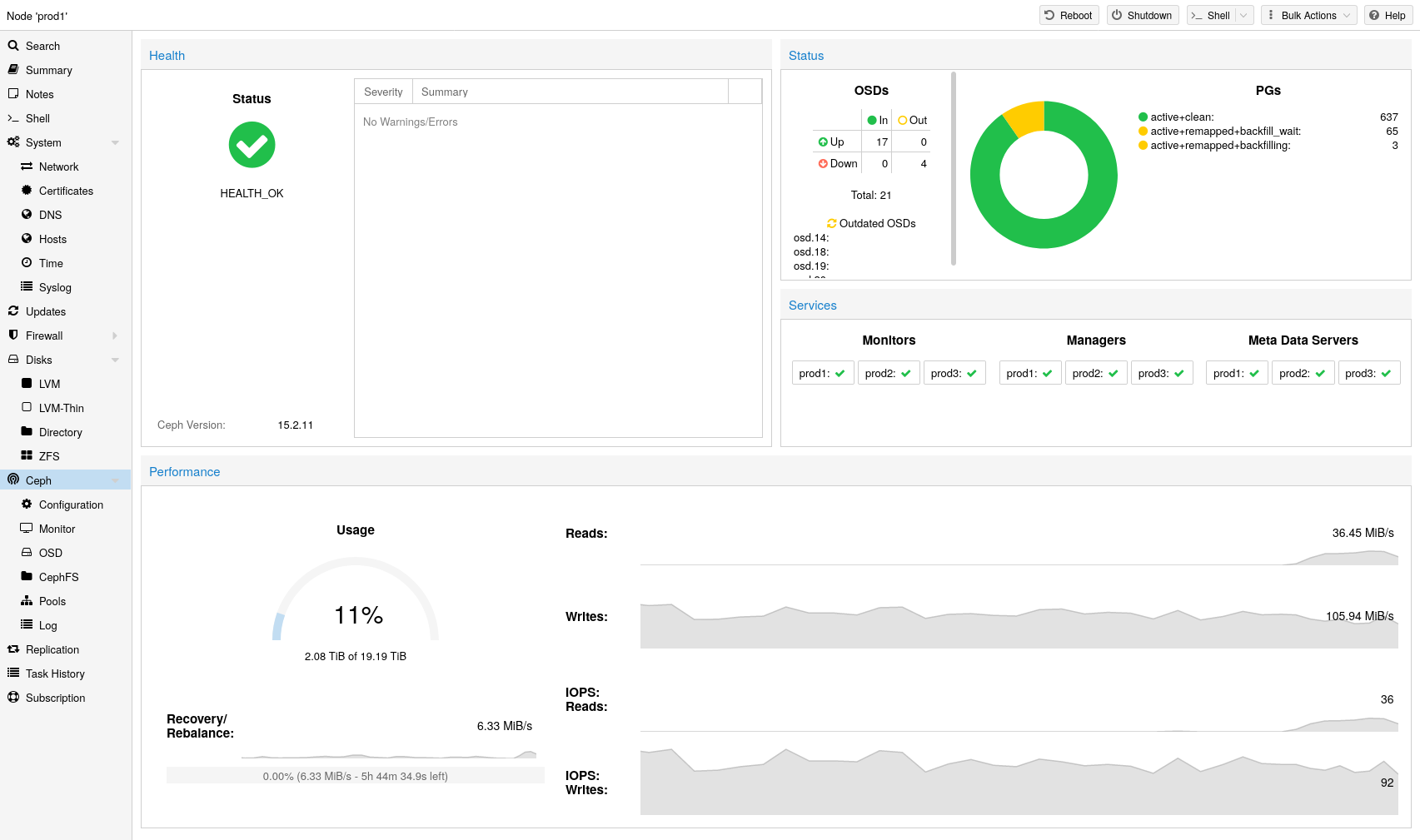
Ceph는 탁월한 성능, 안정성 및 확장성을 제공하도록 설계된 분산 개체 저장소 및 파일 시스템입니다.
Proxmox VE에서 Ceph의 장점은 다음과 같습니다.
- CLI 및 GUI를 통한 손쉬운 설정 및 관리
- 씬 프로비저닝
- 스냅샷 지원
- 자가 치유
- 엑사바이트 수준으로 확장 가능
- 블록, 파일 시스템, 객체 스토리지 제공
- 다양한 성능 및 중복 특성을 갖춘 설정 풀
- 데이터가 복제되어 내결함성을 갖습니다.
- 상용 하드웨어에서 실행
- 하드웨어 RAID 컨트롤러가 필요하지 않습니다.
- 오픈 소스
중소 규모 배포의 경우 RBD(RADOS 블록 장치) 또는 CephFS를 Proxmox VE 클러스터 노드에 직접 사용하기 위한 Ceph 서버를 설치할 수 있습니다(Ceph RADOS 블록 장치(RBD) 참조). 최신 하드웨어에는 CPU 성능과 RAM이 많기 때문에 동일한 노드에서 스토리지 서비스와 가상 게스트를 실행하는 것이 가능합니다.
관리를 단순화하기 위해 Proxmox VE는 내장된 웹 인터페이스나 pveceph 명령줄 도구를 사용하여 Proxmox VE 노드에 Ceph 서비스를 설치하고 관리할 수 있는 기본 통합을 제공합니다.
8.2. 용어
Ceph는 RBD 스토리지로 사용하기 위한 여러 데몬으로 구성됩니다.
- Ceph Monitor (ceph-mon 또는 MON)
- Ceph Manager (ceph-mgr 또는 MGS)
- Ceph Metadata Service (ceph-mds 또는 MDS)
- Ceph Object Storage Daemon (ceph-osd 또는 OSD)
팁: Ceph [14], 해당 아키텍처 [15] 및 어휘 [16]에 익숙해지는 것이 좋습니다.
8.3. 건강한 Ceph 클러스터에 대한 권장 사항
하이퍼 컨버지드 Proxmox + Ceph 클러스터를 구축하려면 설정에 최소 3개(가급적)의 동일한 서버를 사용해야 합니다.
Ceph 웹사이트의 권장 사항도 확인하세요.
참고: 아래 권장 사항은 하드웨어 선택을 위한 대략적인 지침으로 간주되어야 합니다. 따라서 특정 요구 사항에 맞게 조정하는 것이 여전히 중요합니다. 설정을 테스트하고 상태와 성능을 지속적으로 모니터링해야 합니다.
CPU
Ceph 서비스는 두 가지 범주로 분류될 수 있습니다. * 집약적인 CPU 사용, 높은 CPU 기본 주파수 및 다중 코어의 이점. 해당 범주의 구성원은 다음과 같습니다. OSD(Object Storage Daemon) 서비스 CephFS에 사용되는 MDS(메타 데이터 서비스) * CPU 사용량이 적당하며 여러 CPU 코어가 필요하지 않습니다. 모니터(MON) 서비스 관리자(MGR) 서비스
경험에 따르면 안정적이고 내구성 있는 Ceph 성능에 필요한 최소 리소스를 제공하려면 각 Ceph 서비스에 하나 이상의 CPU 코어(또는 스레드)를 할당해야 합니다.
예를 들어 노드에서 Ceph 모니터, Ceph 관리자 및 6개의 Ceph OSD 서비스를 실행할 계획이라면 기본적이고 안정적인 성능을 목표로 할 때 Ceph 전용으로 8개의 CPU 코어를 예약해야 합니다.
OSD의 CPU 사용량은 주로 디스크 성능에 따라 달라집니다. 디스크의 가능한 IOPS(초당 IO 작업)가 높을수록 OSD 서비스에서 더 많은 CPU를 활용할 수 있습니다. 밀리초 미만의 대기 시간으로 100,000이 넘는 높은 IOPS 로드를 영구적으로 유지할 수 있는 NVMe와 같은 최신 기업용 SSD 디스크의 경우 각 OSD는 여러 CPU 스레드를 사용할 수 있습니다. 예를 들어 매우 고성능일 가능성이 높은 NVMe 지원 OSD당 활용되는 CPU 스레드는 4~6개입니다.
메모리
특히 하이퍼컨버지드 설정에서는 메모리 소비를 신중하게 계획하고 모니터링해야 합니다. 가상 머신 및 컨테이너의 예상 메모리 사용량 외에도 우수하고 안정적인 성능을 제공하려면 Ceph에 사용할 수 있는 충분한 메모리가 있는지도 고려해야 합니다.
경험상 대략 1TiB의 데이터에 대해 OSD는 1GiB의 메모리를 사용합니다. 정상적인 조건에서는 사용량이 적을 수 있지만 복구, 재조정 또는 채우기와 같은 중요한 작업 중에 가장 많이 사용됩니다. 즉, 정상 작동 중에 사용 가능한 메모리를 이미 최대화하는 것을 피하고 가동 중단에 대처할 수 있는 여유 공간을 남겨두어야 한다는 의미입니다.
OSD 서비스 자체는 추가 메모리를 사용합니다. 데몬의 Ceph BlueStore 백엔드에는 기본적으로 3~5GiB의 메모리(조정 가능)가 필요합니다.
네트워크
Ceph 트래픽에만 사용하려면 최소 10Gbps 이상의 네트워크 대역폭을 권장합니다. 메시형 네트워크 설정[17]은 사용 가능한 10Gbps 이상의 스위치가 없는 경우 3~5개 노드 클러스터에 대한 옵션이기도 합니다.
중요 특히 복구 중 트래픽 볼륨은 동일한 네트워크의 다른 서비스를 방해합니다. 특히 대기 시간에 민감한 Proxmox VE corosync 클러스터 스택이 영향을 받아 클러스터 쿼럼이 손실될 수 있습니다. Ceph 트래픽을 물리적으로 분리된 전용 네트워크로 이동하면 corosync뿐 아니라 모든 가상 게스트가 제공하는 네트워킹 서비스에 대한 간섭도 방지됩니다.
대역폭 요구 사항을 예측하려면 디스크 성능을 고려해야 합니다. 단일 HDD가 1Gb 링크를 포화시키지 못할 수도 있지만 노드당 여러 HDD OSD도 이미 10Gbps를 포화시킬 수 있습니다. 최신 NVMe 연결 SSD를 사용하는 경우 단일 SSD는 이미 10Gbps 이상의 대역폭을 포화시킬 수 있습니다. 이러한 고성능 설정의 경우 최소 25Gpbs를 권장하며, 기본 디스크의 잠재력을 최대한 활용하려면 40Gbps 또는 100Gbps 이상이 필요할 수도 있습니다.
확실하지 않은 경우 고성능 설정을 위해 3개의(물리적) 별도 네트워크를 사용하는 것이 좋습니다. * Ceph(내부) 클러스터 트래픽을 위한 매우 높은 대역폭(25Gbps 이상) 네트워크 1개. * ceph 서버와 ceph 클라이언트 스토리지 트래픽 간의 Ceph(공용) 트래픽을 위한 고대역폭(10Gpbs 이상) 네트워크 1개. 필요에 따라 가상 게스트 트래픽과 VM 실시간 마이그레이션 트래픽을 호스팅하는 데에도 사용할 수 있습니다. * 대기 시간에 민감한 corosync 클러스터 통신 전용 중간 대역폭(1Gbps) 1개.
디스크
Ceph 클러스터의 크기를 계획할 때 복구 시간을 고려하는 것이 중요합니다. 특히 소규모 클러스터의 경우 복구 시간이 오래 걸릴 수 있습니다. 소규모 설정에서는 HDD 대신 SSD를 사용하여 복구 시간을 줄이고 복구 중에 후속 오류가 발생할 가능성을 최소화하는 것이 좋습니다.
일반적으로 SSD는 회전 디스크보다 더 많은 IOPS를 제공합니다. 이를 염두에 두고 높은 비용 외에도 클래스 기반 풀 분리를 구현하는 것이 합리적일 수 있습니다. OSD 속도를 높이는 또 다른 방법은 더 빠른 디스크를 저널 또는 DB/Write-Ahead-Log 장치로 사용하는 것입니다. Ceph OSD 생성을 참조하세요. 여러 OSD에 더 빠른 디스크를 사용하는 경우 OSD와 WAL/DB(또는 저널) 디스크 간의 적절한 균형을 선택해야 합니다. 그렇지 않으면 더 빠른 디스크가 연결된 모든 OSD에 병목 현상이 됩니다.
디스크 유형 외에도 Ceph는 크기가 균일하고 노드당 디스크 양이 균등하게 분산된 경우 최상의 성능을 발휘합니다. 예를 들어, 각 노드 내에 4개의 500GB 디스크가 1TB 디스크 1개와 250GB 디스크 3개가 있는 혼합 설정보다 낫습니다.
또한 OSD 수와 단일 OSD 용량의 균형을 맞춰야 합니다. 용량이 많을수록 스토리지 밀도가 높아지지만 단일 OSD 오류로 인해 Ceph가 한 번에 더 많은 데이터를 복구해야 한다는 의미이기도 합니다.
RAID 방지
Ceph는 데이터 개체 중복성과 디스크에 대한 다중 병렬 쓰기(OSD)를 자체적으로 처리하므로 일반적으로 RAID 컨트롤러를 사용해도 성능이나 가용성이 향상되지 않습니다. 반대로 Ceph는 중간에 추상화 없이 자체적으로 전체 디스크를 처리하도록 설계되었습니다. RAID 컨트롤러는 Ceph 워크로드용으로 설계되지 않았으며 쓰기 및 캐싱 알고리즘이 Ceph의 알고리즘을 방해할 수 있기 때문에 상황을 복잡하게 만들고 때로는 성능을 저하시킬 수도 있습니다.
경고: RAID 컨트롤러를 사용하지 마십시오. 대신 호스트 버스 어댑터(HBA)를 사용하십시오.
8.4. 초기 Ceph 설치 및 구성
8.4.1. 웹 기반 마법사 사용
Proxmox VE를 사용하면 Ceph용 설치 마법사를 쉽게 사용할 수 있다는 이점이 있습니다. 클러스터 노드 중 하나를 클릭하고 메뉴 트리에서 Ceph 섹션으로 이동합니다. Ceph가 아직 설치되지 않은 경우 Ceph를 설치하라는 메시지가 표시됩니다.
마법사는 Ceph를 사용하기 위해 각 섹션을 성공적으로 완료해야 하는 여러 섹션으로 나누어져 있습니다.
먼저 설치하려는 Ceph 버전을 선택해야 합니다. 다른 노드의 노드를 선호하거나 Ceph를 설치한 첫 번째 노드인 경우 최신 노드를 선호합니다.
설치를 시작하면 마법사가 Proxmox VE의 Ceph 저장소에서 필요한 모든 패키지를 다운로드하여 설치합니다.
설치 단계를 마친 후에는 구성을 생성해야 합니다. 이 단계는 클러스터당 한 번만 필요합니다. 이 구성은 Proxmox VE의 클러스터 구성 파일 시스템(pmxcfs)을 통해 나머지 모든 클러스터 구성원에게 자동으로 배포되기 때문입니다.
구성 단계에는 다음 설정이 포함됩니다.
- Public Network: 이 네트워크는 공용 스토리지 통신(예: Ceph RBD 지원 디스크 또는 CephFS 마운트를 사용하는 가상 머신) 및 다양한 Ceph 서비스 간의 통신에 사용됩니다. 이 설정은 필수입니다. Proxmox VE 클러스터 통신(corosync) 및 가상 게스트의 전면(공용) 네트워크에서 Ceph 트래픽을 분리하는 것이 좋습니다. 그렇지 않으면 Ceph의 고대역폭 IO 트래픽으로 인해 지연 시간이 짧은 다른 서비스에 간섭이 발생할 수 있습니다.
- Cluster Network: OSD 복제와 하트비트 트래픽도 분리하도록 지정합니다. 이 설정은 선택 사항입니다. 물리적으로 분리된 네트워크를 사용하는 것이 좋습니다. 이렇게 하면 Ceph 공용 네트워크와 가상 게스트 네트워크의 부담이 줄어들고 Ceph 성능도 크게 향상됩니다. Ceph 클러스터 네트워크는 나중에 구성하고 물리적으로 분리된 다른 네트워크로 이동할 수 있습니다.
고급으로 간주되는 두 가지 옵션이 더 있으므로 수행 중인 작업을 알고 있는 경우에만 변경해야 합니다.
https://pve.proxmox.com/pve-docs/images/screenshot/gui-node-ceph-install-wizard-step2.png
- Number of replicas: 개체가 복제되는 빈도를 정의합니다.
- Minimum replicas: I/O가 완료로 표시되는 데 필요한 최소 복제본 수를 정의합니다.
또한 첫 번째 모니터 노드를 선택해야 합니다. 이 단계는 필수입니다.
이게 전부입니다. 이제 진행 방법에 대한 추가 지침이 포함된 성공 페이지가 마지막 단계로 표시됩니다. 이제 시스템에서 Ceph를 사용할 준비가 되었습니다. 시작하려면 추가 모니터, OSD 및 하나 이상의 풀을 생성해야 합니다.
이 장의 나머지 부분에서는 Proxmox VE 기반 Ceph 설정을 최대한 활용하는 방법을 안내합니다. 여기에는 앞서 언급한 팁과 새로운 Ceph 클러스터에 유용한 추가 기능인 CephFS 등이 포함됩니다.
8.4.2. Ceph 패키지의 CLI 설치
웹 인터페이스에서 사용 가능한 권장 Proxmox VE Ceph 설치 마법사 대신 각 노드에서 다음 CLI 명령을 사용할 수 있습니다.
pveceph install
그러면 /etc/apt/sources.list.d/ceph.list에 적절한 패키지 저장소가 설정되고 필요한 소프트웨어가 설치됩니다.
8.4.3. CLI를 통한 초기 Ceph 구성
Proxmox VE Ceph 설치 마법사(권장)를 사용하거나 한 노드에서 다음 명령을 실행합니다.
pveceph init --network 10.10.10.0/24
이렇게 하면 Ceph 전용 네트워크를 사용하여 /etc/pve/ceph.conf에 초기 구성이 생성됩니다. 이 파일은 pmxcfs를 사용하여 모든 Proxmox VE 노드에 자동으로 배포됩니다. 또한 이 명령은 /etc/ceph/ceph.conf에 해당 파일을 가리키는 심볼릭 링크를 생성합니다. 따라서 구성 파일을 지정할 필요 없이 Ceph 명령을 간단히 실행할 수 있습니다.
8.5. 세프 모니터
Ceph Monitor(MON)[18]는 클러스터 맵의 마스터 복사본을 유지 관리합니다. 고가용성을 위해서는 최소 3개의 모니터가 필요합니다. 설치 마법사를 사용한 경우 하나의 모니터가 이미 설치되어 있습니다. 클러스터가 중소 규모라면 모니터가 3개 이상 필요하지 않습니다. 매우 큰 클러스터에만 이보다 더 많은 것이 필요합니다.
8.5.1. 모니터 생성
모니터를 배치하려는 각 노드에서(모니터 3개 권장) GUI의 Ceph → 모니터 탭을 사용하여 모니터를 생성하거나 다음을 실행합니다.
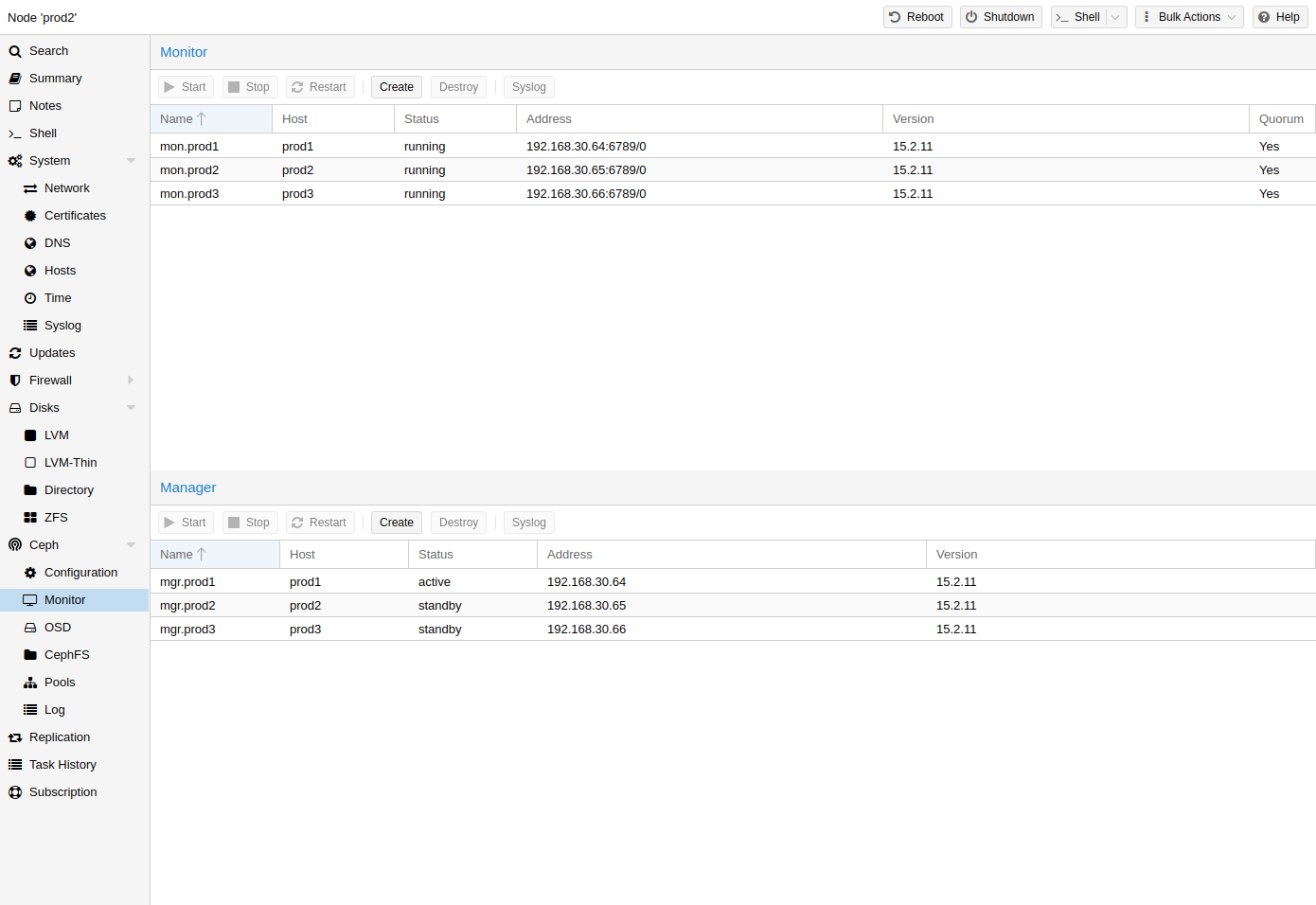
pveceph mon create
8.5.2. 모니터 파괴
GUI를 통해 Ceph 모니터를 제거하려면 먼저 트리 보기에서 노드를 선택하고 Ceph → Monitor 패널로 이동합니다. MON을 선택하고 Destory 버튼을 클릭합니다.
CLI를 통해 Ceph Monitor를 제거하려면 먼저 MON이 실행 중인 노드에 연결하십시오. 그런 다음 다음 명령을 실행합니다.
pveceph mon destroy
참고: 쿼럼에는 모니터가 3개 이상 필요합니다.
8.6. Ceph 매니저
Manager 데몬은 모니터와 함께 실행됩니다. 클러스터를 모니터링하기 위한 인터페이스를 제공합니다. Ceph luminous 출시 이후로 최소한 하나의 ceph-mgr [19] 데몬이 필요합니다.
8.6.1. 관리자 생성
여러 관리자를 설치할 수 있지만 주어진 시간에 하나의 관리자만 활성화됩니다.
pveceph mgr create
참고: Ceph Manager는 모니터 노드에 설치하는 것이 좋습니다. 고가용성을 위해 하나 이상의 관리자를 설치하십시오.
8.6.2. 관리자 파괴
GUI를 통해 Ceph Manager를 제거하려면 먼저 트리 보기에서 노드를 선택하고 Ceph → Monitor 패널로 이동합니다. Manager를 선택하고 Destory 버튼을 클릭하세요.
CLI를 통해 Ceph Monitor를 제거하려면 먼저 Manager가 실행 중인 노드에 연결하십시오. 그런 다음 다음 명령을 실행합니다.
pveceph mgr destroy
참고: 관리자는 하드 종속성은 아니지만 PG 자동 크기 조정, 장치 상태 모니터링, 원격 측정 등과 같은 중요한 기능을 처리하므로 Ceph 클러스터에 매우 중요합니다.
8.7. 세프 OSD
Ceph 객체 스토리지 데몬은 네트워크를 통해 Ceph용 객체를 저장합니다. 물리 디스크당 하나의 OSD를 사용하는 것이 좋습니다.
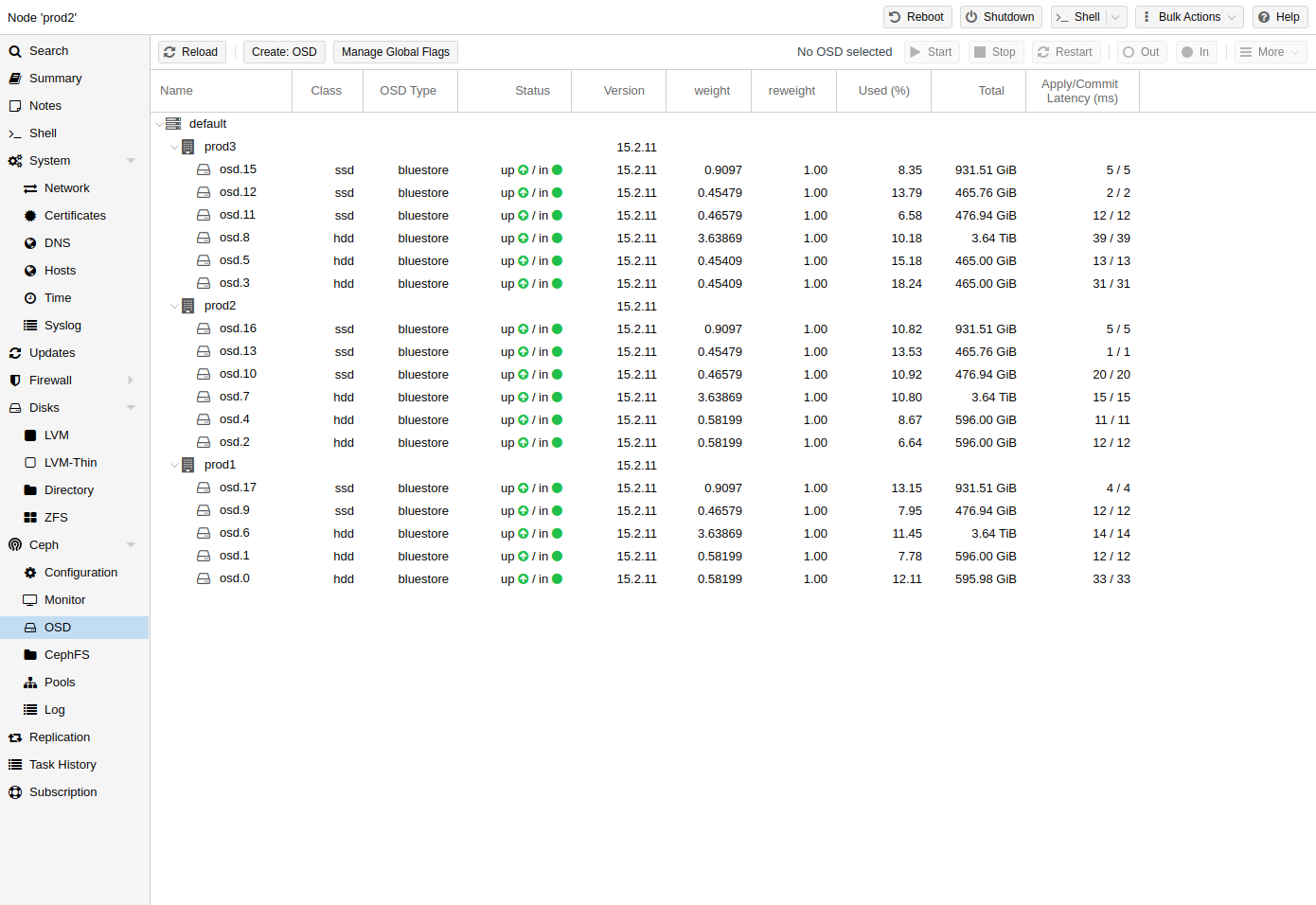
8.7.1. OSD 생성
Proxmox VE 웹 인터페이스나 pveceph를 사용하는 CLI를 통해 OSD를 생성할 수 있습니다. 예를 들어:
pveceph osd create /dev/sd[X]
팁: 노드 간에 균등하게 분산된 3개 이상의 노드와 12개 이상의 OSD가 있는 Ceph 클러스터를 권장합니다.
디스크가 이전에 사용 중이었다면(예: ZFS 또는 OSD용) 먼저 해당 사용에 대한 모든 추적을 삭제해야 합니다. 파티션 테이블, 부팅 섹터 및 기타 OSD 남은 부분을 제거하려면 다음 명령을 사용할 수 있습니다.
ceph-volume lvm zap /dev/sd[X] --destroy
경고: 위 명령은 디스크의 모든 데이터를 삭제합니다!
Ceph Bluestore
Ceph Kraken 릴리스부터 Bluestore[20]라는 새로운 Ceph OSD 스토리지 유형이 도입되었습니다. Ceph Luminous 이후 OSD를 생성할 때 기본값입니다.
pveceph osd create /dev/sd[X]
Block.db 및 block.wal
OSD에 별도의 DB/WAL 장치를 사용하려는 경우 -db_dev 및 -wal_dev 옵션을 통해 지정할 수 있습니다. WAL은 별도로 지정하지 않는 한 DB와 함께 배치됩니다.
pveceph osd create /dev/sd[X] -db_dev /dev/sd[Y] -wal_dev /dev/sd[Z]
각각 -db_size 및 -wal_size 매개변수를 사용하여 크기를 직접 선택할 수 있습니다. 지정되지 않은 경우 다음 값(순서대로)이 사용됩니다.
Ceph 구성의 bluestore_block_{db,wal}_size…
- bluestore_block_{db,wal}_size from Ceph 구성에서…
- … database, section osd
- … database, section global
- … file, section osd
- … file, section global
- OSD 크기의 10% (DB)/1% (WAL)
참고: DB는 BlueStore의 내부 메타데이터를 저장하고, WAL은 BlueStore의 내부 저널 또는 미리 쓰기 로그입니다. 더 나은 성능을 위해서는 빠른 SSD나 NVRAM을 사용하는 것이 좋습니다.
Ceph 파일스토어
Ceph Luminous 이전에는 Filestore가 Ceph OSD의 기본 스토리지 유형으로 사용되었습니다. Ceph Nautilus부터 Proxmox VE는 더 이상 pveceph를 사용한 OSD 생성을 지원하지 않습니다. 여전히 파일 저장소 OSD를 생성하려면 ceph-volume을 직접 사용하십시오.
ceph-volume lvm create --filestore --data /dev/sd[X] --journal /dev/sd[Y]
8.7.2. OSD 파괴
GUI를 통해 OSD를 제거하려면 먼저 트리 보기에서 Proxmox VE 노드를 선택하고 Ceph → OSD 패널로 이동합니다. 그런 다음 삭제할 OSD를 선택하고 OUT 버튼을 클릭하세요. OSD 상태가 in에서 out으로 변경되면 STOP 버튼을 클릭하십시오. 마지막으로 상태가 up에서 down으로 변경된 후 More 드롭다운 메뉴에서 Destroy를 선택합니다.
CLI를 통해 OSD를 제거하려면 다음 명령을 실행하십시오.
ceph osd out <ID> systemctl stop ceph-osd@<ID>.service
참고: 첫 번째 명령은 데이터 배포에 OSD를 포함하지 않도록 Ceph에 지시합니다. 두 번째 명령은 OSD 서비스를 중지합니다. 이때까지는 데이터가 손실되지 않습니다.
다음 명령은 OSD를 파괴합니다. 파티션 테이블을 추가로 삭제하려면 -cleanup 옵션을 지정합니다.
pveceph osd destroy <ID>
경고: 위 명령은 디스크의 모든 데이터를 삭제합니다!
8.8 Ceph 풀
풀은 객체를 저장하기 위한 논리적 그룹입니다. 여기에는 배치 그룹(PG, pg_num)이라는 개체 모음이 있습니다.
8.8.1. 풀 생성 및 편집
명령줄이나 Proxmox VE 호스트의 웹 인터페이스에서 Ceph → Pools 아래에 있는 풀을 생성하고 편집할 수 있습니다.
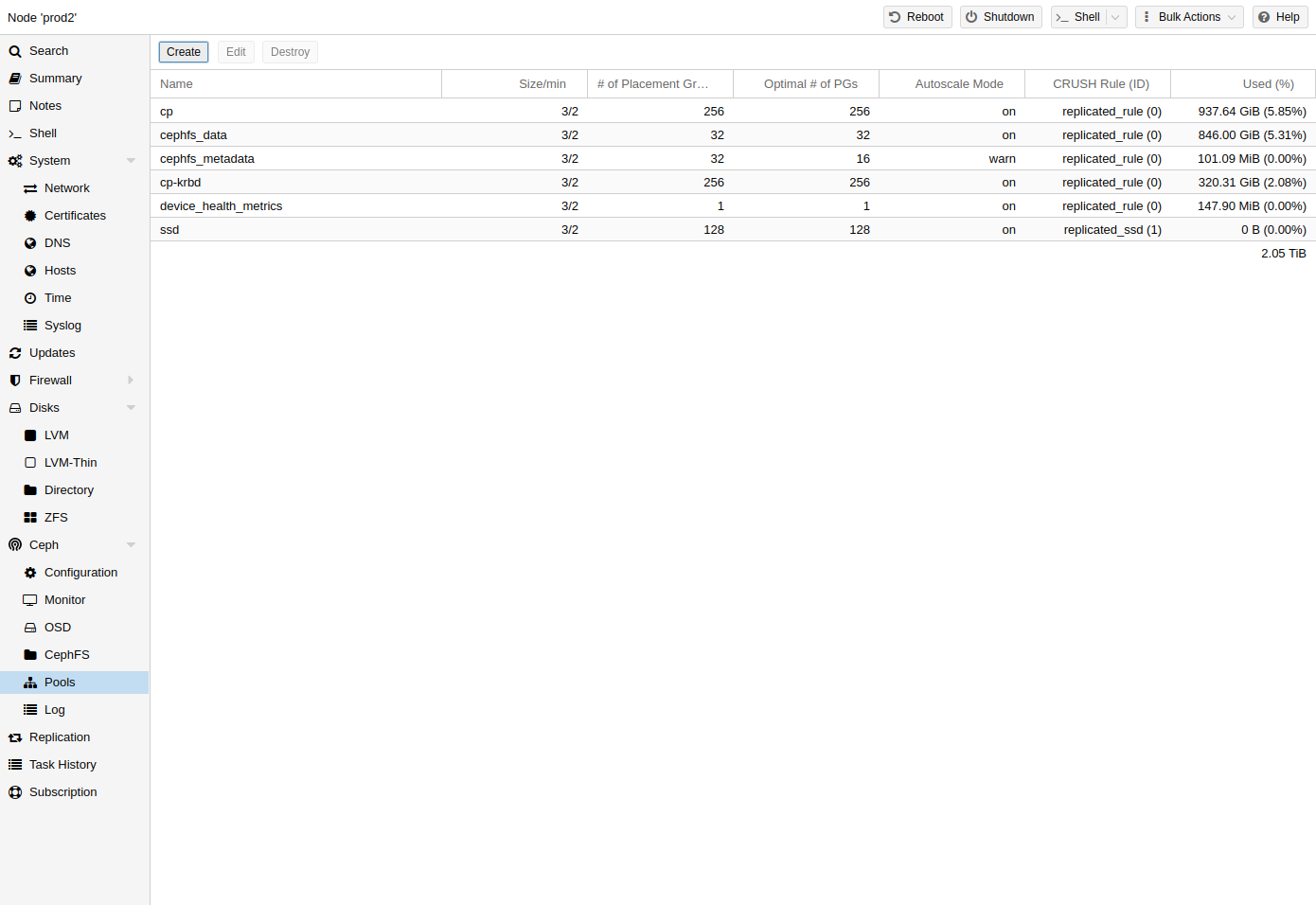
옵션이 제공되지 않으면 OSD가 실패할 경우 데이터 손실이 발생하지 않도록 기본값 128개 PG, 복제본 수 3개, min_size 2개 복제본을 설정합니다.
경고 min_size를 1로 설정하지 마십시오. min_size가 1인 복제된 풀은 복제본이 1개만 있을 때 객체에 대한 I/O를 허용합니다. 이로 인해 데이터 손실, 불완전한 PG 또는 찾을 수 없는 객체가 발생할 수 있습니다.
PG-Autoscaler를 활성화하거나 설정에 따라 PG 번호를 계산하는 것이 좋습니다. 공식과 PG 계산기[21]를 온라인에서 찾을 수 있습니다. Ceph Nautilus부터는 설정 후 PG 수[22]를 변경할 수 있습니다.
PG 자동 확장기[23]는 백그라운드에서 풀의 PG 수를 자동으로 확장할 수 있습니다. Target Size 또는 Target Ratio 고급 매개변수를 설정하면 PG-Autoscaler가 더 나은 결정을 내리는 데 도움이 됩니다.
CLI를 통해 풀을 생성하는 예
pveceph pool create <pool-name> --add_storages
팁: 풀에 대한 스토리지를 자동으로 정의하려면 웹 인터페이스에서 ‘Add as Storage’ 확인란을 선택된 상태로 유지하거나 풀 생성 시 명령줄 옵션 –add_storages를 사용하세요.
풀 옵션
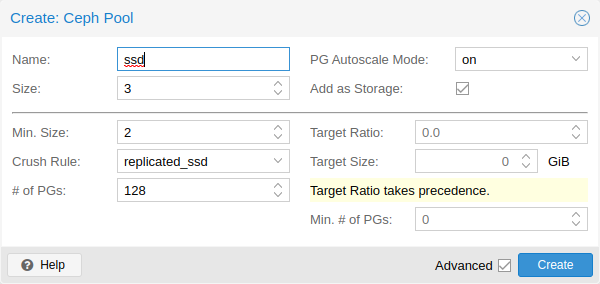
다음 옵션은 풀 생성 시 사용할 수 있으며 부분적으로는 풀 편집 시에도 사용할 수 있습니다.
- Name: 풀의 이름입니다. 이는 고유해야 하며 나중에 변경할 수 없습니다.
- Size: 객체당 복제본 수입니다. Ceph는 항상 이만큼의 객체 복사본을 가지려고 노력합니다. 기본값: 3.
- PG Autoscale Mode: 풀의 자동 PG 확장 모드[23]입니다. 경고로 설정된 경우 풀에 최적이 아닌 PG 수가 있을 때 경고 메시지를 생성합니다. 기본값: 경고합니다.
- Add as Storage: 새 풀을 사용하여 VM 또는 컨테이너 스토리지를 구성합니다. 기본값: true(생성 시에만 표시됨)
고급 옵션
- Min. Size: 객체당 최소 복제본 수입니다. PG의 복제본 수가 이보다 적으면 Ceph는 풀에서 I/O를 거부합니다. 기본값: 2.
- Crush Rule: 클러스터의 매핑 개체 배치에 사용할 규칙입니다. 이러한 규칙은 데이터가 클러스터 내에 배치되는 방식을 정의합니다. 장치 기반 규칙에 대한 자세한 내용은 Ceph CRUSH 및 장치 클래스를 참조하세요.
- # of PGs: 풀이 처음에 가져야 하는 배치 그룹 수[22]입니다. 기본값: 128.
- Target Ratio: 풀에서 예상되는 데이터의 비율입니다. PG 자동 크기 조정기는 다른 비율 세트를 기준으로 비율을 사용합니다. 둘 다 설정된 경우 대상 크기보다 우선합니다.
- Target Size: 풀에서 예상되는 예상 데이터 양입니다. PG 자동 크기 조정기는 이 크기를 사용하여 최적의 PG 수를 추정합니다.
- Min. # of PGs: 배치 그룹의 최소 수입니다. 이 설정은 해당 풀에 대한 PG 수의 하한을 미세 조정하는 데 사용됩니다. PG 자동 크기 조정기는 이 임계값 아래의 PG를 병합하지 않습니다.
Ceph 풀 처리에 대한 자세한 내용은 Ceph 풀 운영 [24] 매뉴얼에서 확인할 수 있습니다.
8.8.2. 삭제 코딩된 풀
삭제 코딩(Erasure Coded)은 일정량의 데이터 손실을 복구할 수 있는 ‘순방향 오류 수정’ 코드의 한 형태입니다. 삭제 코딩된 풀은 복제된 풀에 비해 더 많은 사용 가능한 공간을 제공할 수 있지만 성능에 비해 가격이 저렴합니다.
비교를 위해: 기존 복제 풀에서는 데이터의 여러 복제본이 저장(크기)되는 반면, 삭제 코딩 풀에서는 데이터가 추가 m 코딩(검사) 청크와 함께 k 데이터 청크로 분할됩니다. 이러한 코딩 청크는 데이터 청크가 누락된 경우 데이터를 다시 생성하는 데 사용될 수 있습니다.
코딩 청크 수 m은 데이터 손실 없이 손실될 수 있는 OSD 수를 정의합니다. 저장된 객체의 총량은 k + m입니다.
EC 풀 생성
EC 풀은 pveceph CLI 도구를 사용하여 생성할 수 있습니다. EC 풀을 계획할 때는 EC 풀이 복제된 풀과 다르게 작동한다는 사실을 고려해야 합니다.
EC 풀의 기본 min_size는 m 매개변수에 따라 다릅니다. m = 1이면 EC 풀의 min_size는 k가 됩니다. m > 1인 경우 min_size는 k + 1이 됩니다. Ceph 문서에서는 보수적인 min_size k + 2를 권장합니다[25].
사용 가능한 OSD가 min_size보다 적으면 다시 사용할 수 있는 OSD가 충분해질 때까지 풀에 대한 모든 IO가 차단됩니다.
참고: 삭제 코딩 풀을 계획할 때 min_size를 주의 깊게 살펴보세요. min_size는 사용 가능한 OSD 수를 정의합니다. 그렇지 않으면 IO가 차단됩니다.
예를 들어, k = 2이고 m = 1인 EC 풀은 크기 = 3, min_size = 2를 가지며 하나의 OSD가 실패하더라도 작동 상태를 유지합니다. 풀이 k = 2, m = 2로 구성되면 크기 = 4, min_size = 3이 되며 하나의 OSD가 손실되더라도 작동 상태를 유지합니다.
새 EC 풀을 생성하려면 다음 명령을 실행합니다.
pveceph pool create <pool-name> --erasure-coding k=2,m=1
선택적 매개변수는 failure-domain 및 device-class입니다. 풀에서 사용되는 EC 프로필 설정을 변경해야 하는 경우 새 프로필을 사용하여 새 풀을 생성해야 합니다.
그러면 새 EC 풀과 RBD Omap 및 기타 메타데이터를 저장하는 데 필요한 복제 풀이 생성됩니다. 마지막으로 -data 풀과 -metada 풀이 있게 됩니다. 기본 동작은 일치하는 스토리지 구성도 생성하는 것입니다. 해당 동작을 원하지 않는 경우 –add_storages 0 매개변수를 제공하여 비활성화할 수 있습니다. 스토리지 구성을 수동으로 구성하는 경우 data-pool 매개변수를 설정해야 한다는 점에 유의하세요. 그런 다음에만 EC 풀을 사용하여 데이터 개체를 저장합니다. 예를 들어:
참고: 선택적 매개변수 –size, –min_size 및 –crush_rule은 복제된 메타데이터 풀에 사용되지만 삭제 코딩된 데이터 풀에는 사용되지 않습니다. 데이터 풀의 min_size를 변경해야 하는 경우 나중에 변경할 수 있습니다. 삭제 코딩된 풀에서는 size 및 crush_rule 매개변수를 변경할 수 없습니다.
EC 프로파일을 추가로 사용자 정의해야 하는 경우 Ceph 도구를 사용하여 직접 생성하고[26] profile 매개변수와 함께 사용할 프로파일을 지정하면 됩니다.
예를 들어:
pveceph pool create <pool-name> --erasure-coding profile=<profile-name>
EC 풀을 스토리지로 추가
기존 EC 풀을 Proxmox VE에 스토리지로 추가할 수 있습니다. RBD 풀을 추가하는 것과 동일한 방식으로 작동하지만 추가 데이터 풀 옵션이 필요합니다.
pvesm add rbd <storage-name> --pool <replicated-pool> --data-pool <ec-pool>
팁: 로컬 Proxmox VE 클러스터에서 관리하지 않는 외부 Ceph 클러스터에 대해 keyring 및 monhost 옵션을 추가하는 것을 잊지 마십시오.
8.8.3. 풀 파괴
GUI를 통해 풀을 삭제하려면 트리 보기에서 노드를 선택하고 Ceph → Pools 패널로 이동합니다. 제거할 풀을 선택하고 Destory 버튼을 클릭합니다. 풀 삭제를 확인하려면 풀 이름을 입력해야 합니다.
풀을 삭제하려면 다음 명령을 실행하세요. 연관된 스토리지도 제거하려면 -remove_storages를 지정하십시오.
pveceph pool destroy <name>
참고 풀 삭제는 백그라운드에서 실행되며 다소 시간이 걸릴 수 있습니다. 이 프로세스 전반에 걸쳐 클러스터의 데이터 사용량이 감소하는 것을 확인할 수 있습니다.
8.8.4. PG 자동 크기 조정기
PG 자동 크기 조정기를 사용하면 클러스터가 각 풀에 저장된 (예상) 데이터의 양을 고려하고 적절한 pg_num 값을 자동으로 선택할 수 있습니다. Ceph Nautilus부터 사용 가능합니다.
조정 내용을 적용하려면 먼저 PG 자동 크기 조절기 모듈을 활성화해야 할 수도 있습니다.
ceph mgr module enable pg_autoscaler
자동 크기 조정기는 풀별로 구성되며 다음과 같은 모드를 갖습니다.
- warn: 제안된 pg_num 값이 현재 값과 너무 많이 다른 경우 상태 경고가 발행됩니다.
- on: pg_num은 수동 상호 작용이 필요 없이 자동으로 조정됩니다.
- off: 자동 pg_num 조정은 수행되지 않으며 PG 수가 최적이 아닌 경우 경고가 발행되지 않습니다.
target_size, target_size_ratio 및 pg_num_min 옵션을 사용하여 향후 데이터 저장을 용이하게 하기 위해 배율 인수를 조정할 수 있습니다.
경고 기본적으로 자동 크기 조정기는 풀이 3배로 벗어난 경우 풀의 PG 수 조정을 고려합니다. 이로 인해 데이터 배치가 크게 바뀌고 클러스터에 높은 로드가 발생할 수 있습니다.
Ceph’s Blog – New in Nautilus: PG merging and autotuning에서 PG 자동 크기 조정기에 대한 자세한 소개를 확인할 수 있습니다.
8.9. Ceph CRUSH 및 장치 클래스
[27](확장 가능한 해싱 하에서 제어된 복제) 알고리즘은 Ceph의 기초입니다.
CRUSH는 데이터를 저장하고 검색할 위치를 계산합니다. 이는 중앙 인덱싱 서비스가 필요하지 않다는 장점이 있습니다. CRUSH는 풀에 대한 OSD, 버킷(장치 위치) 및 규칙 세트(데이터 복제) 맵을 사용하여 작동합니다.
참고: 자세한 내용은 Ceph 문서의 CRUSH 맵 [28] 섹션에서 확인할 수 있습니다.
이 맵은 다양한 복제 계층을 반영하도록 변경될 수 있습니다. 원하는 배포를 유지하면서 객체 복제본을 분리할 수 있습니다(예: 장애 도메인).
일반적인 구성은 서로 다른 Ceph 풀에 대해 서로 다른 클래스의 디스크를 사용하는 것입니다. 이러한 이유로 Ceph는 쉬운 규칙 세트 생성에 대한 요구를 수용하기 위해 발광 장치 클래스를 도입했습니다.
장치 클래스는 ceph osd 트리 출력에서 볼 수 있습니다. 이러한 클래스는 아래 명령으로 볼 수 있는 자체 루트 버킷을 나타냅니다.
ceph osd crush tree --show-shadow
위 명령의 출력 예는 다음과 같습니다.
ID CLASS WEIGHT TYPE NAME -16 nvme 2.18307 root default~nvme -13 nvme 0.72769 host sumi1~nvme 12 nvme 0.72769 osd.12 -14 nvme 0.72769 host sumi2~nvme 13 nvme 0.72769 osd.13 -15 nvme 0.72769 host sumi3~nvme 14 nvme 0.72769 osd.14 -1 7.70544 root default -3 2.56848 host sumi1 12 nvme 0.72769 osd.12 -5 2.56848 host sumi2 13 nvme 0.72769 osd.13 -7 2.56848 host sumi3 14 nvme 0.72769 osd.14
특정 장치 클래스의 개체만 배포하도록 풀에 지시하려면 먼저 장치 클래스에 대한 규칙 세트를 만들어야 합니다.
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>
| <rule-name> | name of the rule, to connect with a pool (seen in GUI & CLI) |
| <root> | which crush root it should belong to (default Ceph root “default”) |
| <failure-domain> | at which failure-domain the objects should be distributed (usually host) |
| <class> | what type of OSD backing store to use (e.g., nvme, ssd, hdd) |
규칙이 CRUSH 맵에 있으면 풀에 규칙 세트를 사용하도록 지시할 수 있습니다.
ceph osd pool set <pool-name> crush_rule <rule-name>
팁: 풀에 이미 개체가 포함된 경우 이에 따라 개체를 이동해야 합니다. 설정에 따라 클러스터 성능에 큰 영향을 미칠 수 있습니다. 대안으로 새 풀을 생성하고 디스크를 별도로 이동할 수 있습니다.
8.10. Ceph 클라이언트
이전 섹션의 설정에 따라 이러한 풀을 사용하여 VM 및 컨테이너 이미지를 저장하도록 Proxmox VE를 구성할 수 있습니다. GUI를 사용하여 새 RBD 스토리지를 추가하기만 하면 됩니다(Ceph RADOS 블록 장치(RBD) 섹션 참조).
또한 외부 Ceph 클러스터의 사전 정의된 위치에 키링을 복사해야 합니다. Ceph가 Proxmox 노드 자체에 설치된 경우 이 작업은 자동으로 수행됩니다.
참고: 파일 이름은+ `.keyring이어야 합니다. 여기서는 /etc/pve/storage.cfg에서 rbd: 뒤의 표현식입니다. 다음 예에서 my-ceph-storage는입니다.
mkdir /etc/pve/priv/ceph cp /etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/my-ceph-storage.keyring
8.11. CephFS
Ceph는 RADOS 블록 장치와 동일한 객체 스토리지 위에서 실행되는 파일 시스템도 제공합니다. Metadata Server(MDS)는 RADOS 지원 개체를 파일 및 디렉터리에 매핑하는 데 사용되므로 Ceph는 POSIX 호환 복제 파일 시스템을 제공할 수 있습니다. 이를 통해 클러스터링된 고가용성 공유 파일 시스템을 쉽게 구성할 수 있습니다. Ceph의 메타데이터 서버는 파일이 전체 Ceph 클러스터에 고르게 분산되도록 보장합니다. 결과적으로 로드가 높은 경우에도 단일 호스트를 압도하지 않으며 이는 NFS와 같은 기존 공유 파일 시스템 접근 방식에서 문제가 될 수 있습니다.
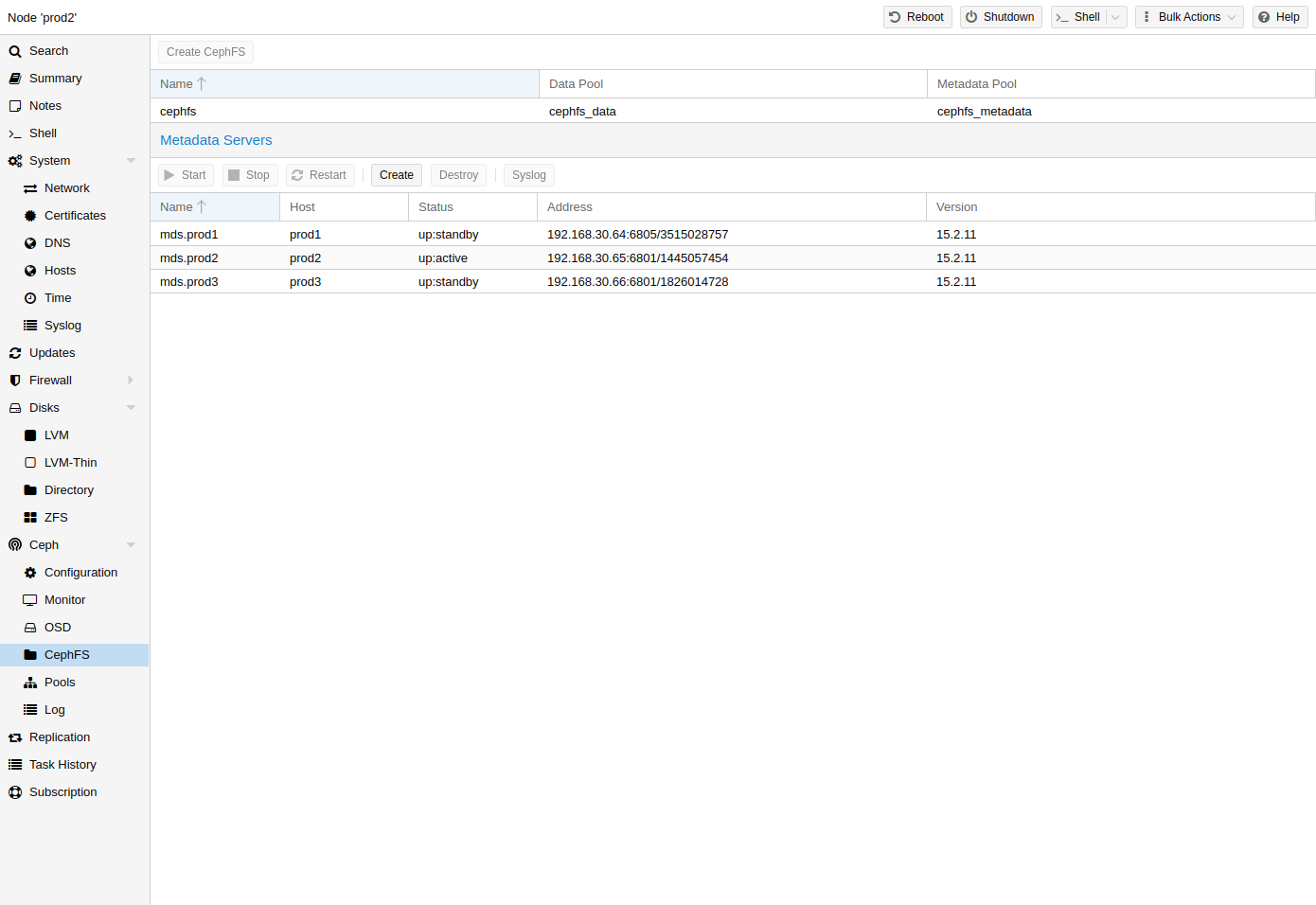
Proxmox VE는 하이퍼 컨버지드 CephFS 생성과 기존 CephFS를 스토리지로 사용하여 백업, ISO 파일 및 컨테이너 템플릿을 저장하는 것을 모두 지원합니다.
8.11.1. Metadata Server(MDS)
CephFS가 작동하려면 하나 이상의 메타데이터 서버를 구성하고 실행해야 합니다. Proxmox VE 웹 GUI의 Node -> CephFS 패널을 통해 또는 명령줄에서 다음을 사용하여 MDS를 생성할 수 있습니다.
pveceph mds create
여러 메타데이터 서버를 클러스터에 생성할 수 있지만 기본 설정에서는 한 번에 하나만 활성화할 수 있습니다. MDS 또는 해당 노드가 응답하지 않거나 충돌하는 경우 다른 대기 MDS가 활성 상태로 승격됩니다. 생성 시 hotstandby 매개변수 옵션을 사용하여 활성 MDS와 대기 MDS 간의 핸드오버 속도를 높일 수 있습니다. 또는 이미 생성한 경우 다음을 설정/추가할 수 있습니다.
mds standby replay = true
/etc/pve/ceph.conf의 해당 MDS 섹션에 있습니다. 이 기능을 활성화하면 지정된 MDS가 웜 상태로 유지되어 활성 MDS를 폴링하므로 문제가 발생할 경우 더 빠르게 인계받을 수 있습니다.
참고: 이 활성 폴링은 시스템과 활성 MDS에 추가적인 성능 영향을 미칩니다.
다중 활성 MDS
Luminous(12.2.x) 이후로 여러 활성 메타데이터 서버를 동시에 실행할 수 있지만 이는 일반적으로 병렬로 실행되는 클라이언트 수가 많은 경우에만 유용합니다. 그렇지 않으면 MDS가 시스템의 병목 현상을 일으키는 경우는 거의 없습니다. 이를 설정하려면 Ceph 설명서를 참조하세요. [29]
8.11.2. CephFS 생성
Proxmox VE에 CephFS가 통합되면 웹 인터페이스, CLI 또는 외부 API 인터페이스를 사용하여 CephFS를 쉽게 생성할 수 있습니다. 이것이 작동하려면 몇 가지 전제 조건이 필요합니다.
성공적인 CephFS 설정을 위한 전제 조건:
- Ceph 패키지 설치 – 이 작업이 얼마 전에 이미 수행된 경우 최신 시스템에서 다시 실행하여 모든 CephFS 관련 패키지가 설치되었는지 확인할 수 있습니다.
- 모니터 설정
- OSD 설정
- 하나 이상의 MDS를 설정
이 작업이 완료되면 Web GUI의 Node -> CephFS 패널 또는 명령줄 도구 pveceph를 통해 CephFS를 생성할 수 있습니다. 예를 들면 다음과 같습니다.
pveceph fs create --pg_num 128 --add-storage
그러면 128개의 배치 그룹이 있는 cephfs_data라는 데이터용 풀과 데이터 풀 배치 그룹의 1/4(32)이 있는 cephfs_metadata라는 메타데이터용 풀을 사용하여 cephfs라는 CephFS가 생성됩니다. 설정에 적합한 배치 그룹 번호(pg_num)에 대한 자세한 내용은 Proxmox VE 관리 Ceph 풀 장을 확인하거나 Ceph 설명서를 참조하세요[22]. 또한 –add-storage 매개변수는 Proxmox VE 스토리지 구성이 성공적으로 생성된 후 CephFS를 Proxmox VE 스토리지 구성에 추가합니다.
8.11.3. CephFS 파괴
경고: CephFS를 삭제하면 모든 데이터를 사용할 수 없게 됩니다. 이 취소 할 수 없습니다!
CephFS를 완전하고 정상적으로 제거하려면 다음 단계가 필요합니다.
- Proxmox가 아닌 모든 클라이언트의 연결을 끊습니다(예: 게스트에서 CephFS 마운트 해제).
- 관련된 모든 CephFS Proxmox VE 스토리지 항목을 비활성화합니다(자동으로 마운트되는 것을 방지하기 위해).
- 제거하려는 CephFS에 있는 게스트(예: ISO)에서 사용된 모든 리소스를 제거합니다.
- 다음을 사용하여 모든 클러스터 노드에서 CephFS 스토리지를 수동으로 마운트 해제합니다.
umount /mnt/pve/<STORAGE-NAME>
여기서 은 Proxmox VE의 CephFS 스토리지 이름입니다.
- 이제 CephFS를 중지하거나 삭제하여 해당 CephFS에 대해 실행 중인 메타데이터 서버(MDS)가 없는지 확인하십시오. 이는 웹 인터페이스나 명령줄 인터페이스를 통해 수행할 수 있으며 후자의 경우 다음 명령을 실행합니다.
pveceph stop --service mds.NAME
그들을 정지시키거나, 또는
pveceph mds destroy NAME
그들을 파괴하기 위해.
활성 MDS가 중지되거나 제거되면 대기 서버는 자동으로 활성 상태로 승격되므로 먼저 모든 대기 서버를 중지하는 것이 가장 좋습니다.
- 이제 다음을 사용하여 CephFS를 파괴할 수 있습니다.
pveceph fs destroy NAME --remove-storages --remove-pools
그러면 기본 Ceph 풀이 자동으로 삭제되고 pve 구성에서 스토리지가 제거됩니다.
이러한 단계 후에 CephFS는 완전히 제거되어야 하며 다른 CephFS 인스턴스가 있는 경우 중지된 메타데이터 서버를 다시 시작하여 대기 서버로 작동할 수 있습니다.
8.12. 세프 유지 관리
8.12.1. OSD 교체
Ceph에서 가장 일반적인 유지 관리 작업 중 하나는 OSD 디스크를 교체하는 것입니다. 디스크가 이미 오류 상태인 경우 OSD 제거의 단계를 수행할 수 있습니다. Ceph는 가능한 경우 나머지 OSD에 해당 복사본을 다시 생성합니다. 이 재조정은 OSD 오류가 감지되거나 OSD가 적극적으로 중지되는 즉시 시작됩니다.
참고: 풀의 기본 크기/min_size(3/2)를 사용하면 ‘size + 1’ 노드를 사용할 수 있는 경우에만 복구가 시작됩니다. 그 이유는 Ceph 객체 밸런서 CRUSH가 ‘장애 도메인’으로 전체 노드를 기본값으로 설정하기 때문입니다.
GUI에서 작동하는 디스크를 교체하려면 OSD 제거의 단계를 따르십시오. 유일한 추가 사항은 클러스터를 파괴하기 위해 OSD를 중지하기 전에 클러스터에 HEALTH_OK가 표시될 때까지 기다리는 것입니다.
명령줄에서 다음 명령을 사용합니다.
ceph osd out osd.<id>
OSD를 안전하게 제거할 수 있는지 아래 명령으로 확인할 수 있습니다.
ceph osd safe-to-destroy osd.<id>
위의 확인 결과 OSD를 제거해도 안전하다는 메시지가 나타나면 다음 명령을 계속 사용할 수 있습니다.
systemctl stop ceph-osd@<id>.service pveceph osd destroy <id>
기존 디스크를 새 디스크로 교체하고 OSD 생성에 설명된 것과 동일한 절차를 사용합니다.
8.12.2. Trim/Discard
VM 및 컨테이너에서 정기적으로 fstrim(discard을 실행하는 것이 좋습니다. 그러면 파일 시스템이 더 이상 사용하지 않는 데이터 블록이 해제됩니다. 데이터 사용량과 리소스 부하를 줄여줍니다. 대부분의 최신 운영 체제는 정기적으로 디스크에 삭제 명령을 실행합니다. 가상 머신이 디스크 폐기 옵션을 활성화하는지 확인하기만 하면 됩니다.
8.12.3. 스크럽 & 딥 스크럽
Ceph는 배치 그룹을 스크러빙하여 데이터 무결성을 보장합니다. Ceph는 PG의 모든 개체의 상태를 확인합니다. 스크러빙에는 일일 저렴한 메타데이터 확인과 주간 심층 데이터 확인이라는 두 가지 형태가 있습니다. 주간 심층 스크럽은 개체를 읽고 체크섬을 사용하여 데이터 무결성을 보장합니다. 실행 중인 스크럽이 비즈니스(성능) 요구 사항을 방해하는 경우 스크럽[30]이 실행되는 시간을 조정할 수 있습니다.
8.13. Ceph 모니터링 및 문제 해결
Ceph 도구를 사용하거나 Proxmox VE API를 통해 상태에 액세스하여 처음부터 Ceph 배포 상태를 지속적으로 모니터링하는 것이 중요합니다.
다음 Ceph 명령을 사용하여 클러스터가 정상인지(HEALTH_OK), 경고(HEALTH_WARN) 또는 오류(HEALTH_ERR)가 있는지 확인할 수 있습니다. 클러스터가 비정상 상태인 경우 아래 상태 명령을 사용하면 현재 이벤트 및 수행할 작업에 대한 개요도 제공됩니다.
# single time output pve# ceph -s # continuously output status changes (press CTRL+C to stop) pve# ceph -w
더 자세한 보기를 위해 모든 Ceph 서비스에는 /var/log/ceph/ 아래에 로그 파일이 있습니다. 더 자세한 내용이 필요한 경우 로그 수준을 조정할 수 있습니다[31].
공식 웹사이트에서 Ceph 클러스터 문제 해결에 대한 자세한 내용을 확인할 수 있습니다.





